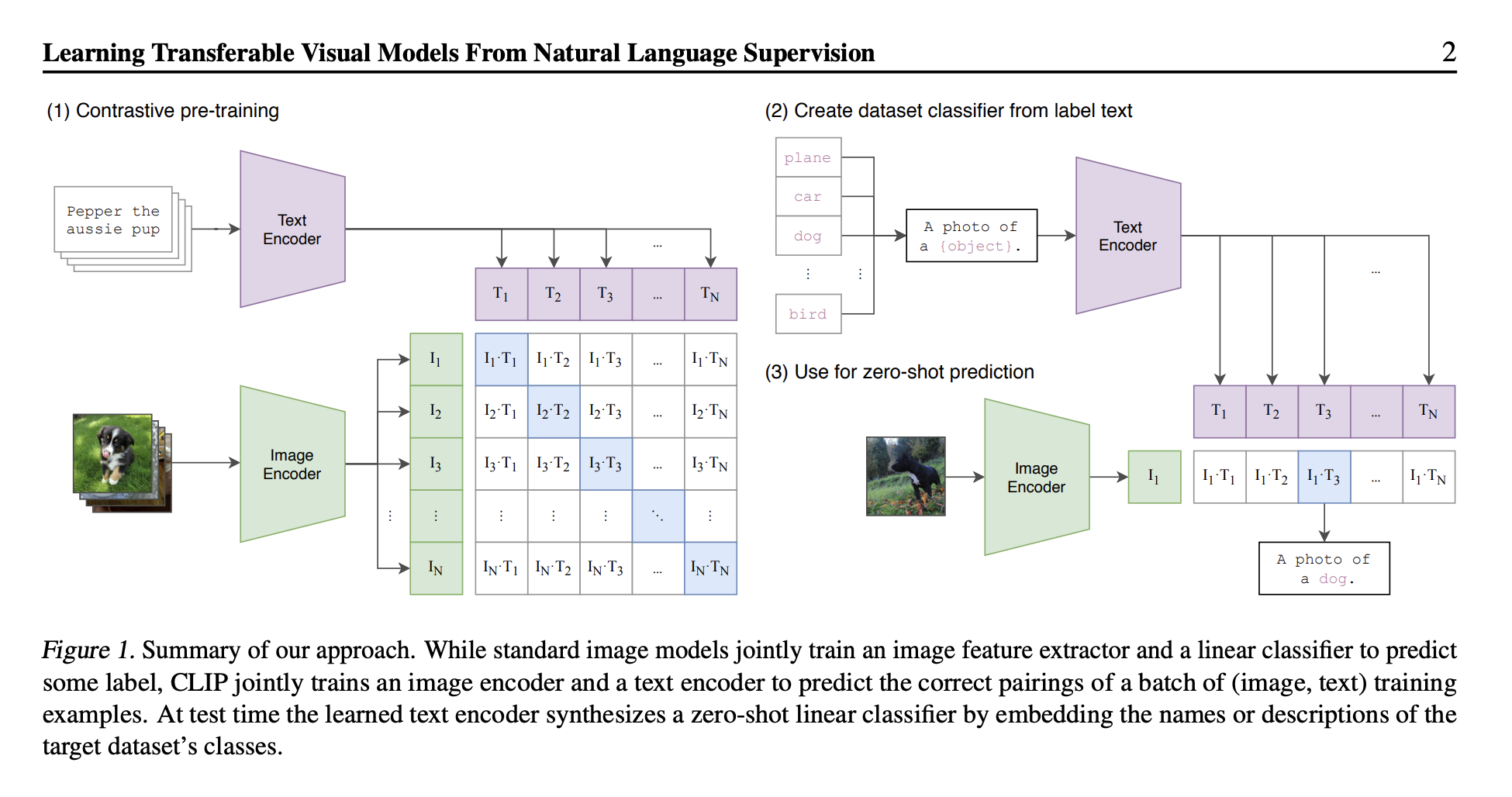
Contrastive Language-Image Pre-Training (CLIP)
CLIP was trained on a huge number of image-caption pairs from the internet.
Resources:
- https://arxiv.org/pdf/2103.00020
- https://medium.com/one-minute-machine-learning/clip-paper-explained-easily-in-3-levels-of-detail-61959814ad13
CLIP is a model for telling you how well a given image and a given text caption fit together.