Implicit Q-Learning
Saw from this paper https://arxiv.org/pdf/2505.08078
Original paper:
- https://arxiv.org/pdf/2110.06169 - OFFLINE REINFORCEMENT LEARNING WITH IMPLICIT Q-LEARNING
- https://arxiv.org/pdf/2304.10573 - IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
- they mention implicit policy extraction here
In this work, we primarily consider the Implicit Q-Learning (IQL) [20] value objectives given its effectiveness on a range of tasks. IQL aims to fit a value function by estimating expectiles τ with respect to actions within the support of the data, and then uses the value function to update the
Q-function. To do so, it aims to minimize the following objectives for learning a parameterized Q-function (with target Q-function Qϕ′ ) and value function Vψ:
- where .
Original paper:
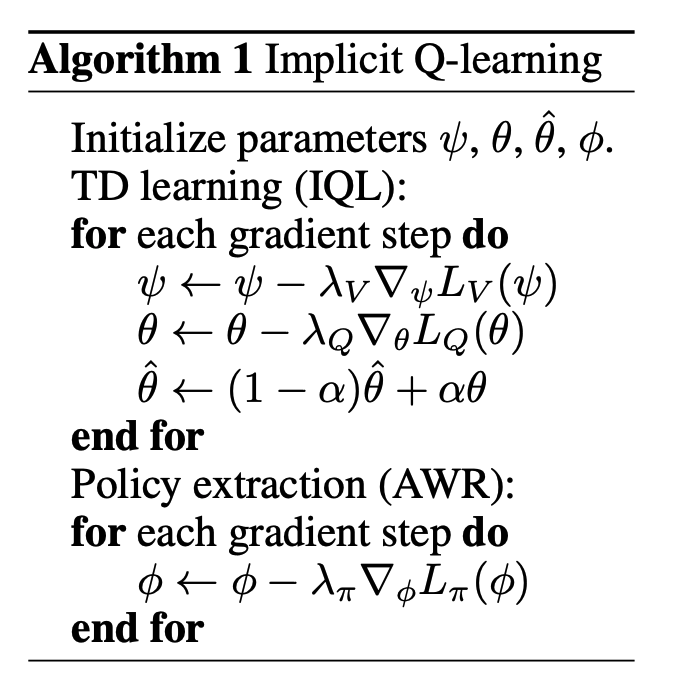
It learns a Q-function from the offline dataset.
It derives a value function by “aggregating” the learned Q-function across actions.
It then trains the policy to imitate the best actions in the dataset (using advantage-weighted updates).