One-Hot Encoding
First learned about this term through Machine Learning, but surprisingly I hear is as well in Digital Circuits.
One-hot distribution
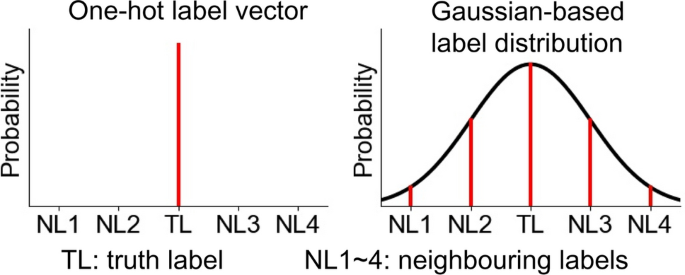
- This is just the Kronecker Delta
Machine Learning
Where there is categorical data, we use one-hot encoding to convert it into features, where each category is a feature of 1.
Danger
We also need to remove one column because that is simply a duplicate because it is a Dummy Variable (i.e. redundant information).
It seems that Andrej Karpathy didn’t worry about this however.