Parameter Golf Challenge
Challenge by OpenAI. Im going to hyper-obsess over this.
The main thing is achieving good compression.
Turboquant:
List of ideas:
- FP8
- Smarter attention
- QAT
Some side ideas
There’s this talk from Ilya Sutksokover about An Observation on Generalization which talks about LLMs are really just these glorified compression machines, but the reason they work so well is because the objective itself is cross-entropy.
There are 2 main axes:
- Speeding up training (since we are limited to training for 10 mins on 8xh100 cluster)
- Improving model architecture to get better compression while remaining under 16MB
Running the baseline train_gpt.py on my RTX5090:
RUN_ID=profiled_baseline_sp1024 \
DATA_PATH=./data/datasets/fineweb10B_sp1024/ \
TOKENIZER_PATH=./data/tokenizers/fineweb_1024_bpe.model \
VOCAB_SIZE=1024 \
torchrun --standalone --nproc_per_node=1 train_gpt.py step:967/20000 val_loss:2.3008 val_bpb:1.3627 train_time:600152ms step_avg:620.63ms
stopping_early: wallclock_cap train_time:600152ms step:967/20000
peak memory allocated: 10255 MiB reserved: 10834 MiB
Serialized model: 67224983 bytes
Code size: 47686 bytes
Total submission size: 67272669 bytes
Serialized model int8+zlib: 12225991 bytes (payload:17178912 raw_torch:17224025 payload_ratio:3.91x)
Total submission size int8+zlib: 12273677 bytes
final_int8_zlib_roundtrip val_loss:2.3043 val_bpb:1.3647 eval_time:21564ms
final_int8_zlib_roundtrip_exact val_loss:2.30429686 val_bpb:1.36473439Change #1: Sliding Window
This is a common eval idea popularized by the huggingface blog https://huggingface.co/docs/transformers/perplexity#calculating-ppl-with-fixed-length-models.
The problem: Given a long sequence of tokens, we want to evaluate the perforamnce on our LLM. However, our models can only accept a maximum context window size, so we need to split the sequence up.
Naively, we can chunk this up into non-overlapping sequences, and evaluate each sequence individually. For example for a max context size of 1024 tokens, we would:
- Feed tokens
[0...1023], and score positions[0...1023] - Feed tokens
[1024...2047], and score positions[1024...2047] - Feed tokens
[2048...3071], and score positions[2048...3071]
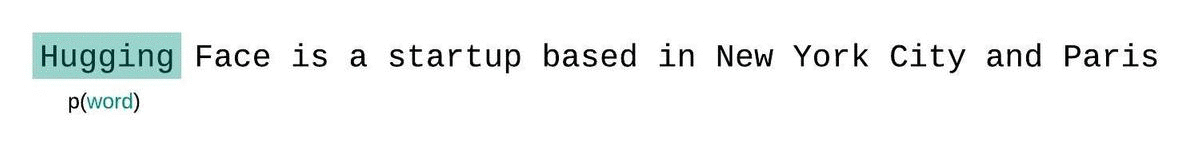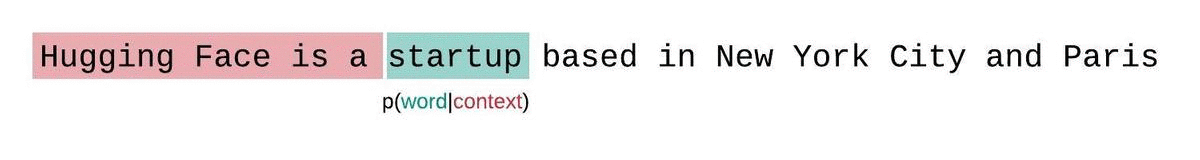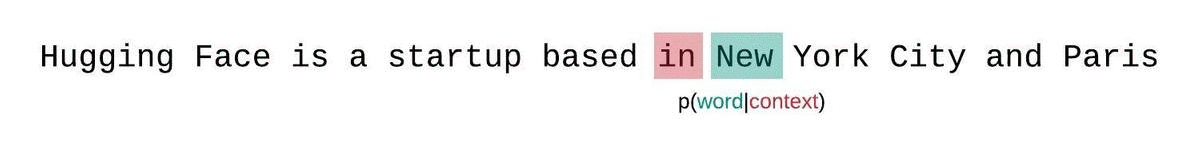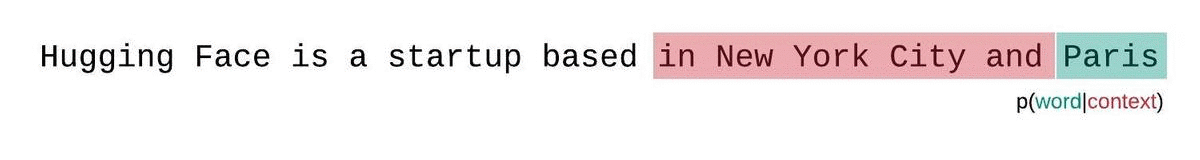
You can see that the average length of the context window that each token gets scored on is sequence length / 2 (tokens predicted at the beginning of sequence get no context, tokens predicted at end of sequence get all the context)
However, we can do better. position 1024 should ideally be scored on from getting the full context from tokens [1...1024], however in this setup it only gets context from a single token, at position[1024] (since it is the beginning of the sequence).
We can address this by using a sliding window.
- Feed tokens
[0...1023], score positions[0...1023] - Feed tokens
[1...1024], but only score positions[1024] - Feed tokens
[2...1025], but only score positions[1025] - etc.
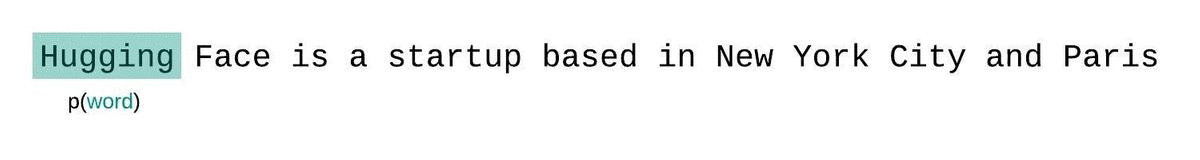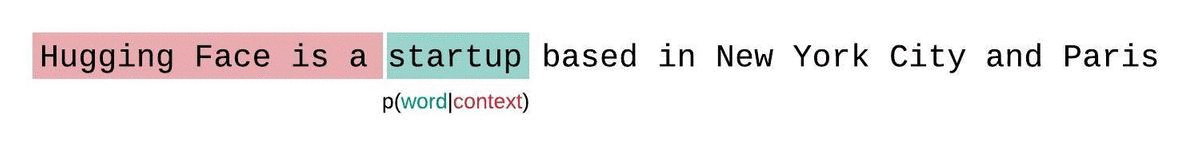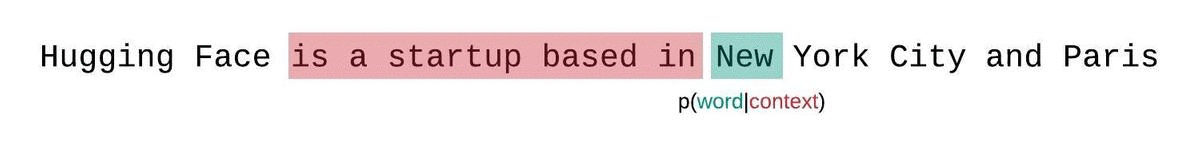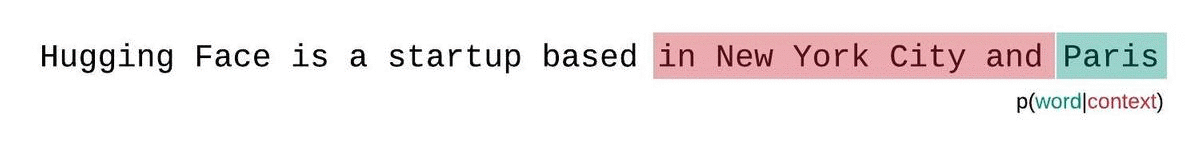
In this setup, we just throws away the loss for the early positions.
For this challenge, people have been using a stride of 64.
The naive implementation uses window = 1024, stride = 1024, and took ~20s
Why stride = 64?
Ideally, we use a stride of so that
- Feed tokens
[0...1023], but only score positions[960...1023](the last 64) - Feed tokens
[64...1087], but only score positions[1024...1087](the last 64) - Feed tokens
[128...1151], but only score positions[1088...1151](the last 64)
Change #2: Fp8 Training
Might be a bit hard.
Run a profiler through the model. And then it can be easy to see the bottlenecks in your training loop.
RUN_ID=profiled_baseline_sp1024 \
DATA_PATH=./data/datasets/fineweb10B_sp1024/ \
TOKENIZER_PATH=./data/tokenizers/fineweb_1024_bpe.model \
VOCAB_SIZE=1024 \
nsys profile --capture-range=cudaProfilerApi --pytorch=autograd-nvtx --trace=cuda,nvtx,osrt -o new_profile_output torchrun --standalone --nproc_per_node=1 train_gpt.py 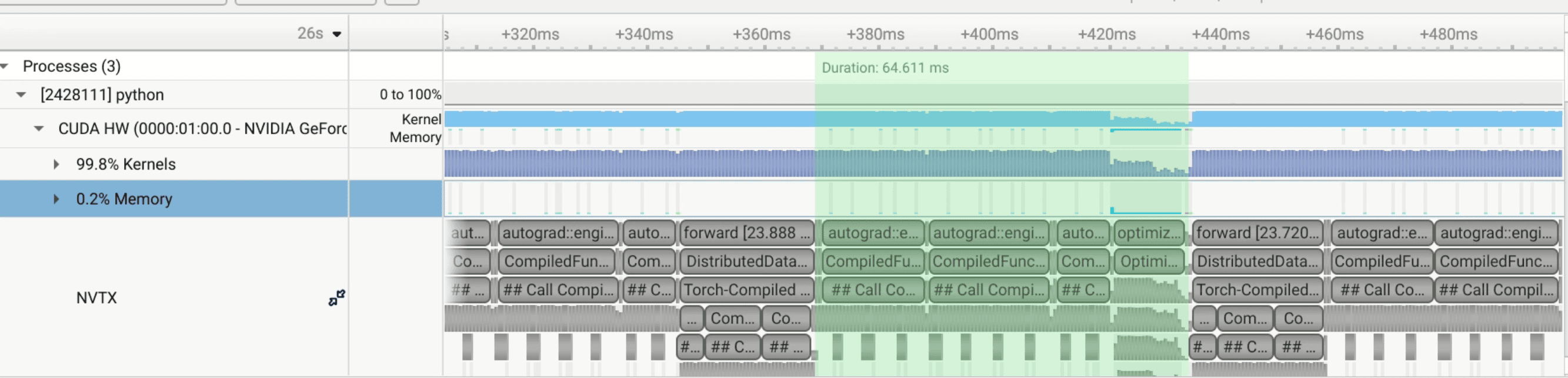
-
Forward: 23ms
-
Backward: 64ms
The multiple rows in Nsight Systems are nested NVTX ranges — each nesting level gets its own row. The hierarchy looks something like:
Row 1: [forward] [backward] [forward] [backward] … ← your manual nvtx.range() markers -
Row 2: [DistributedDataParallel.forward] … ← PyTorch DDP wrapper
-
Row 3: [Torch-Compiled Region: 0/3] … ← torch.compile regions Row 4: [CompiledFxGraph fk4s…] [CompiledFxGraph fov…] ← actual compiled graphs Row 5: [newton_schulz] … ← optimizer internals
This is normal — it’s just Nsight showing the call hierarchy. Each parent range contains child ranges, and they stack vertically. It’s not multiple
backward passes; it’s one operation shown at multiple levels of detail.
Details about the optimizer
No — the optimizer works in fp32.
The key lines are 928-930: CastedLinear weights are stored in fp32, so Adam/Muon see fp32 parameters and accumulate fp32 momentum buffers.
The one exception is Muon’s internal Newton-Schulz iteration, which explicitly casts to bf16 for speed at line 102.
USE_FP8=1 \
RUN_ID=profiled_baseline_sp1024 \
DATA_PATH=./data/datasets/fineweb10B_sp1024/ \
TOKENIZER_PATH=./data/tokenizers/fineweb_1024_bpe.model \
VOCAB_SIZE=1024 \
nsys profile --capture-range=cudaProfilerApi --pytorch=autograd-nvtx --trace=cuda,nvtx,osrt -o fp8 torchrun --standalone --nproc_per_node=1 train_gpt.py
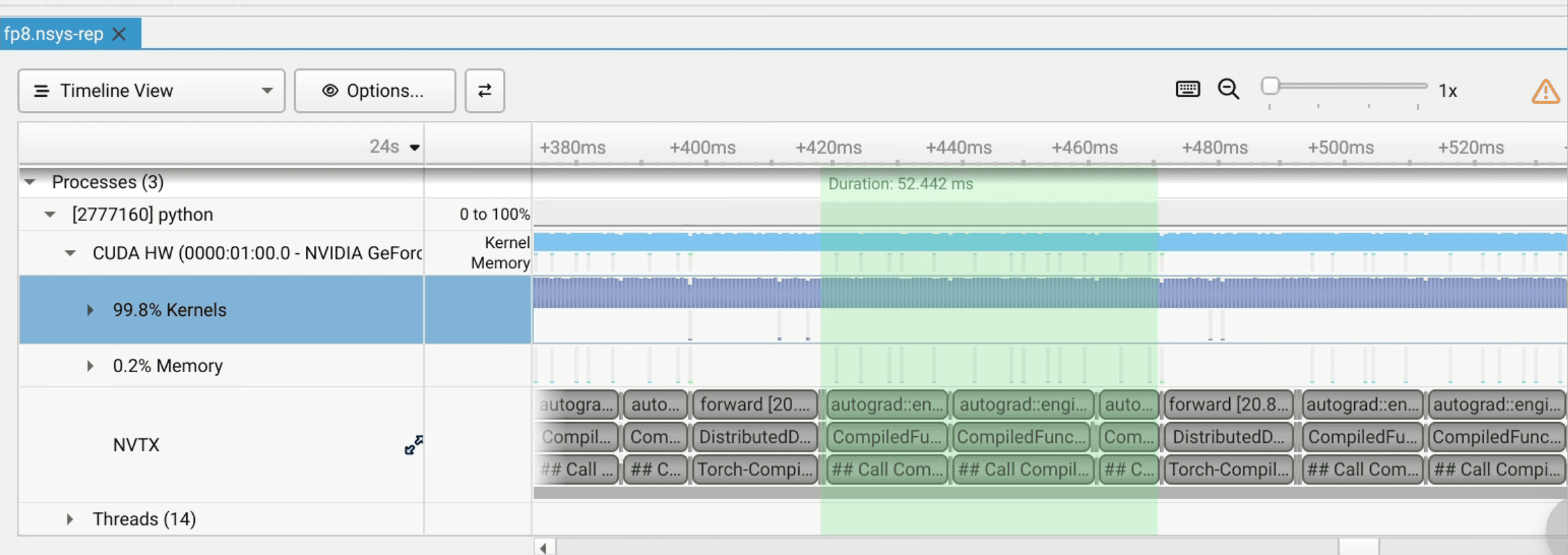
- Forward: 20ms
- Backward: 52ms
.venv) (base) steven@steven-beast:~/research/parameter-golf$ USE_FP8=1 RUN_ID=fp8_baseline_sp1024 DATA_PATH=./data/datasets/fineweb10B_sp1024/ TOKENIZER_PATH=./data/tokenizers/fineweb_1024_bpe.model VOCAB_SIZE=1024 torchrun --s
tandalone --nproc_per_node=1 train_gpt.py
logs/fp8_baseline_sp1024.txt
val_bpb:enabled tokenizer_kind=sentencepiece tokenizer_path=./data/tokenizers/fineweb_1024_bpe.model
train_loader:dataset:fineweb10B_sp1024 train_shards:80
val_loader:shards pattern=./data/datasets/fineweb10B_sp1024/fineweb_val_*.bin tokens:62021632
model_params:17059912
world_size:1 grad_accum_steps:8
sdp_backends:cudnn=False flash=True mem_efficient=False math=False
attention_mode:gqa num_heads:8 num_kv_heads:4
tie_embeddings:True embed_lr:0.05 head_lr:0.0 matrix_lr:0.04 scalar_lr:0.04
train_batch_tokens:524288 train_seq_len:1024 iterations:20000 warmup_steps:20 max_wallclock_seconds:600.000
seed:1337
warmup_step:1/20
warmup_step:2/20
warmup_step:3/20
warmup_step:4/20
warmup_step:5/20
warmup_step:6/20
warmup_step:7/20
warmup_step:8/20
warmup_step:9/20
warmup_step:10/20
warmup_step:11/20
warmup_step:12/20
warmup_step:13/20
warmup_step:14/20
warmup_step:15/20
warmup_step:16/20
warmup_step:17/20
warmup_step:18/20
warmup_step:19/20
warmup_step:20/20
step:0/20000 val_loss:6.9357 val_bpb:4.1077 train_time:0ms step_avg:0.01ms
step:1/20000 train_loss:6.9357 train_time:590ms step_avg:589.89ms
step:2/20000 train_loss:16.7423 train_time:1176ms step_avg:587.92ms
step:3/20000 train_loss:9.3528 train_time:1767ms step_avg:588.93ms
step:4/20000 train_loss:6.6005 train_time:2358ms step_avg:589.52ms
step:5/20000 train_loss:6.4850 train_time:2949ms step_avg:589.87ms
step:6/20000 train_loss:6.6235 train_time:3540ms step_avg:590.04ms
step:7/20000 train_loss:6.3330 train_time:4131ms step_avg:590.20ms
step:8/20000 train_loss:6.1912 train_time:4723ms step_avg:590.34ms
step:9/20000 train_loss:6.0772 train_time:5314ms step_avg:590.46ms
step:10/20000 train_loss:5.9786 train_time:5906ms step_avg:590.58ms
step:200/20000 train_loss:2.7744 train_time:119309ms step_avg:596.54ms
step:400/20000 train_loss:2.3767 train_time:239359ms step_avg:598.40ms
step:600/20000 train_loss:2.4696 train_time:359502ms step_avg:599.17ms
step:800/20000 train_loss:2.3143 train_time:479661ms step_avg:599.58ms
step:1000/20000 train_loss:2.3335 train_time:599801ms step_avg:599.80ms
step:1000/20000 val_loss:2.2993 val_bpb:1.3618 train_time:599804ms step_avg:599.80ms
step:1001/20000 val_loss:2.2993 val_bpb:1.3618 train_time:600406ms step_avg:599.81ms
stopping_early: wallclock_cap train_time:600406ms step:1001/20000
peak memory allocated: 9418 MiB reserved: 9510 MiB
Serialized model: 67224983 bytes
Code size: 56222 bytes
Total submission size: 67281205 bytes
Serialized model int8+zlib: 12378179 bytes (payload:17178912 raw_torch:17224025 payload_ratio:3.91x)
Total submission size int8+zlib: 12434401 bytes
final_int8_zlib_roundtrip val_loss:2.3022 val_bpb:1.3635 eval_time:21498ms
final_int8_zlib_roundtrip_exact val_loss:2.30219270 val_bpb:1.36348819
final_sliding_window_eval stride:64 val_loss:2.2460 val_bpb:1.3302 eval_time:691423ms
final_sliding_window_eval_exact stride:64 val_loss:2.24600126 val_bpb:1.33020846