Reinforcement Learning from Human Feedback (RLHF)
I dont get how the PPO works:
The papers that you need to read:
- Deep reinforcement learning from human preferences
- Learning to summarize from human feedback
- FineTuning Language Models from Human Preferences
- Training language models to follow instructions with human feedback
Robotics
Resources
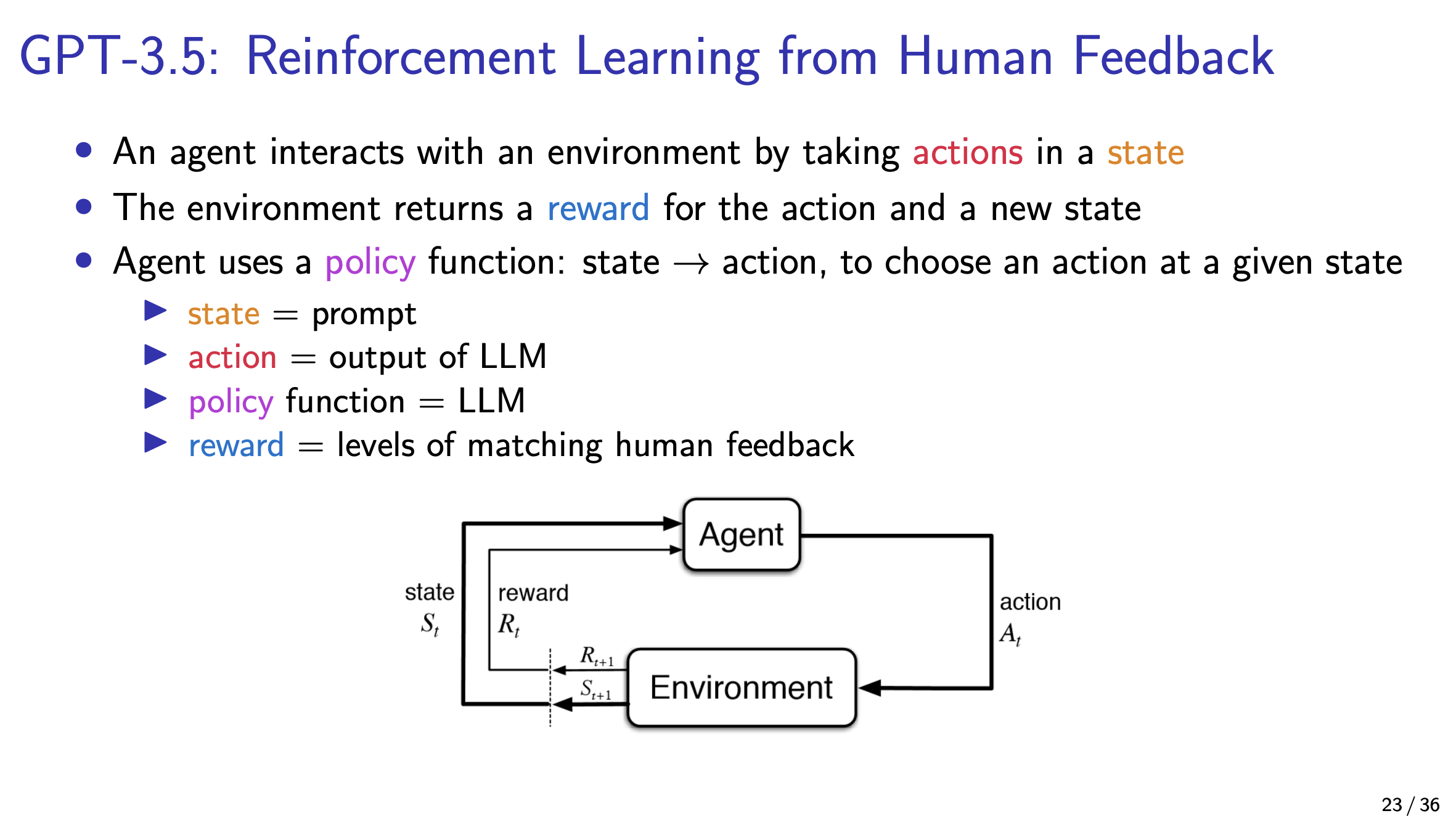
This is where AI Alignment is important, since the human feedback determines what are good and bad instructions.
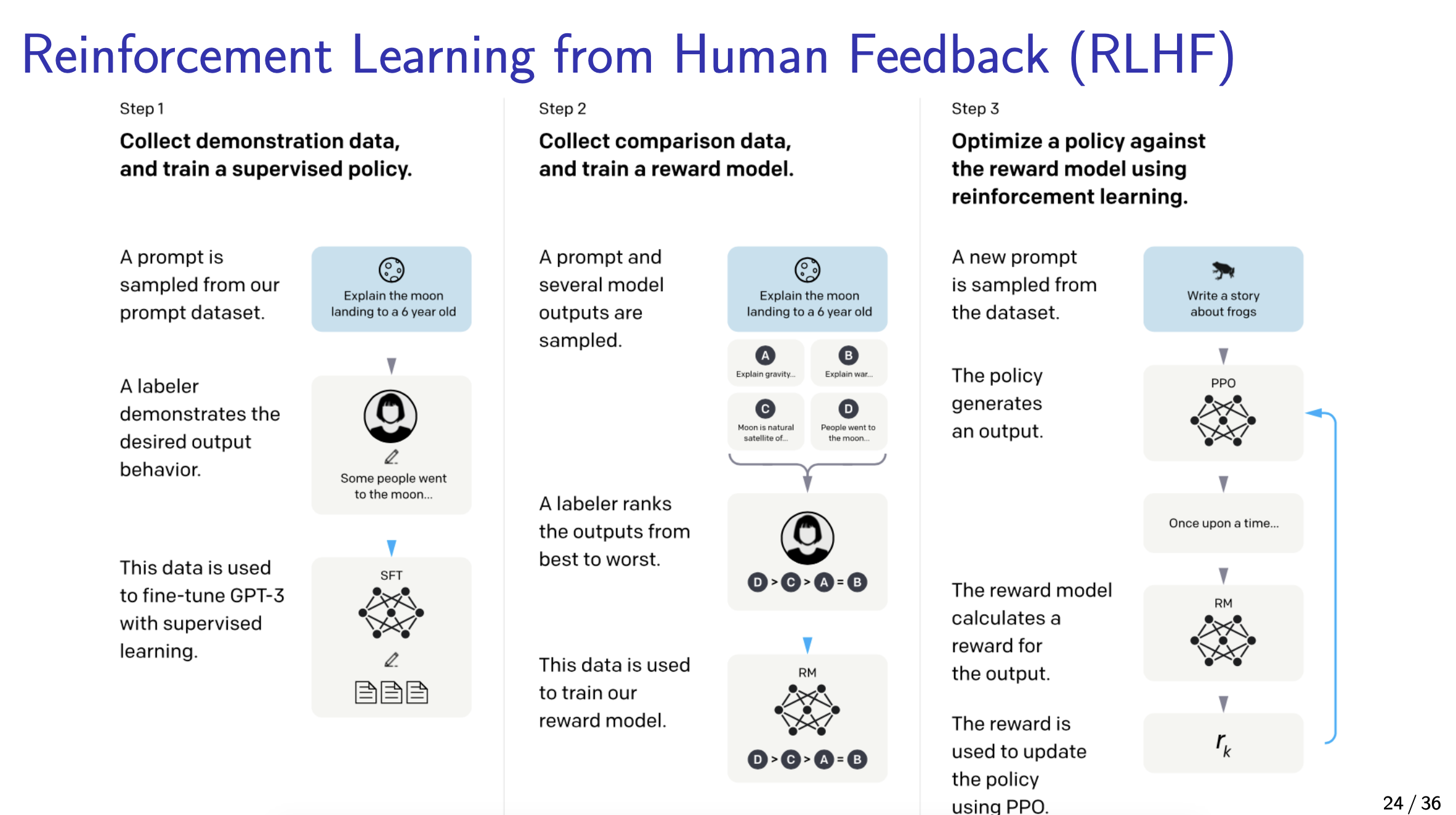
Ok i don’t wanna keep copy pasting these slides but they are very good for explaining how things work.

