Efficient Online Reinforcement Learning with Offline Data (RLPD)
It’s actually a very simple idea, just sample equally from offline dataset and online dataset. However, there are also some implementation details to get this right.
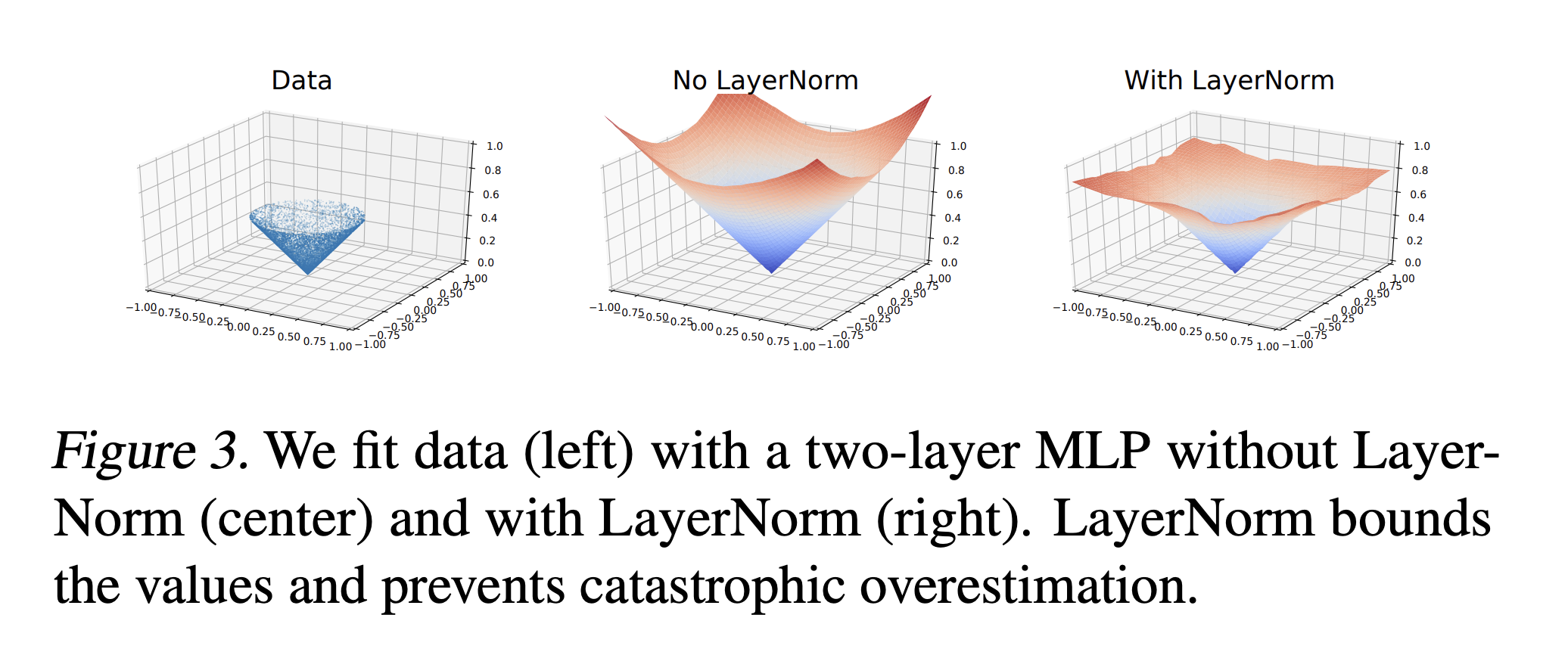
UTD Ratio: However can result in statistical over-fitting
A great way to visualize this overfitting