Genie: Generative Interactive Environments
This seems to be follow up of Dream to Control Learning Behaviors by Latent Imagination.
How TF does it learn action without being provided ground truth action?
You let the model learn on its own what it thinks the ground truth action should be. And then say that there are only 8 possible actions for example.
Genie 2
https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model/
Genie 2 is an autoregressive Latent Diffusion Model, trained on a large video dataset. After passing through an autoencoder, latent frames from the video are passed to a large transformer dynamics model, trained with a causal mask similar to that used by large language models.
Inference time
At inference time, Genie 2 can be sampled in an autoregressive fashion, taking individual actions and past latent frames on a frame-by-frame basis.
- They use ClassifierFree Diffusion Guidance to improve action controllability.
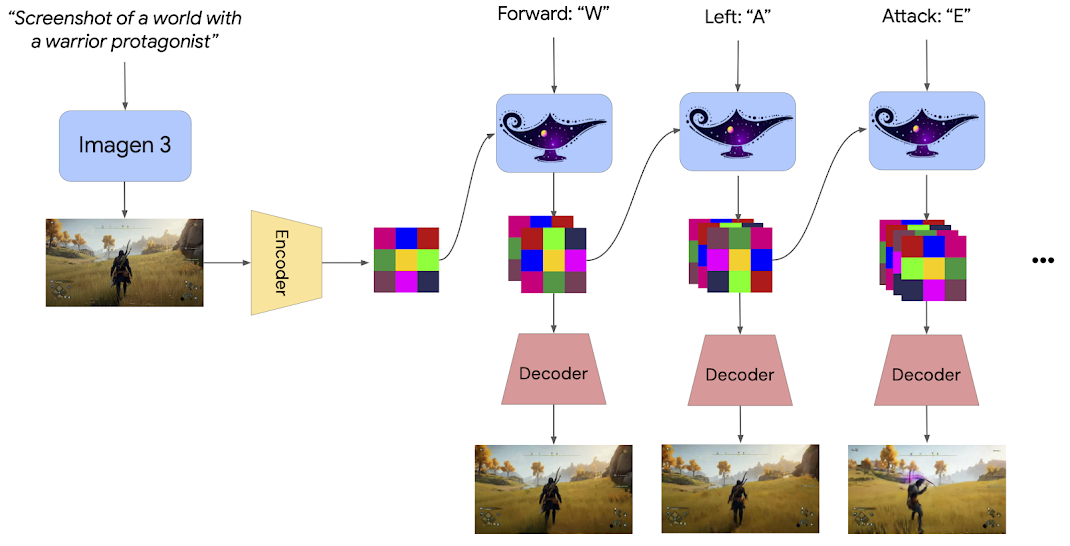
Genie 3
https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/
Adds controllability, but doesn’t really say how Genie 3 was built.