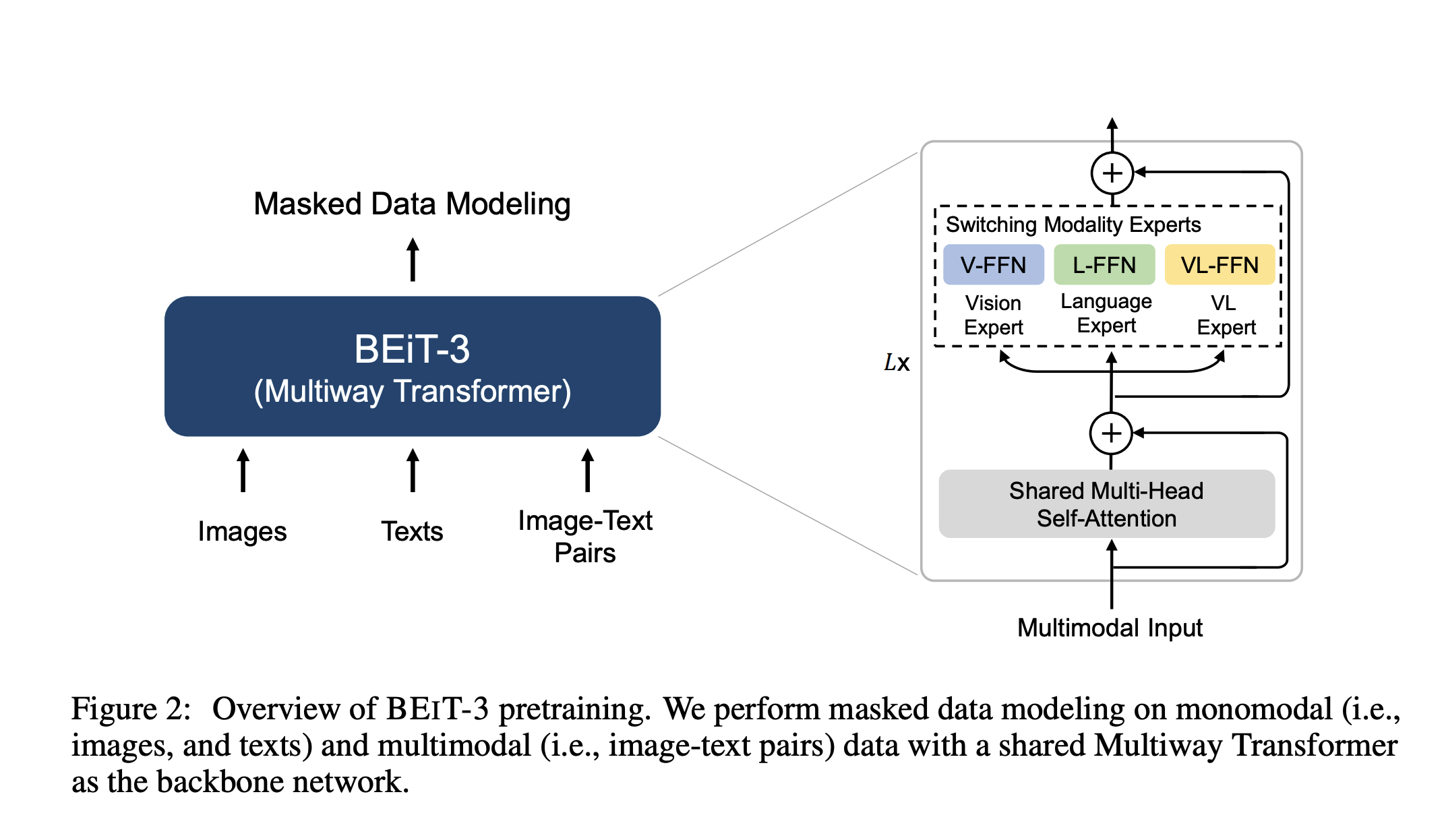
Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks BEIT-3 is a general-purpose multimodal foundation model. Paper: https://arxiv.org/pdf/2208.10442