Vision in Action: Learning Active Perception from Human Demonstrations
Website:
The main contribution comes slapping a camera onto the head, and motion tracking the head with a VR headset, so the data includes the human’s perception.
The tasks are designed to showcase when this is needed, where the camera gets occluded when its picking up things.
The tasks that they did with visual occlusion:
- Bag task
- Failure mode due to object being deep inside backpack
- Cup Task
- Failure mode due to occlusion
- Lime & pot task
- The failure mode is due to right arm not knowing where to go
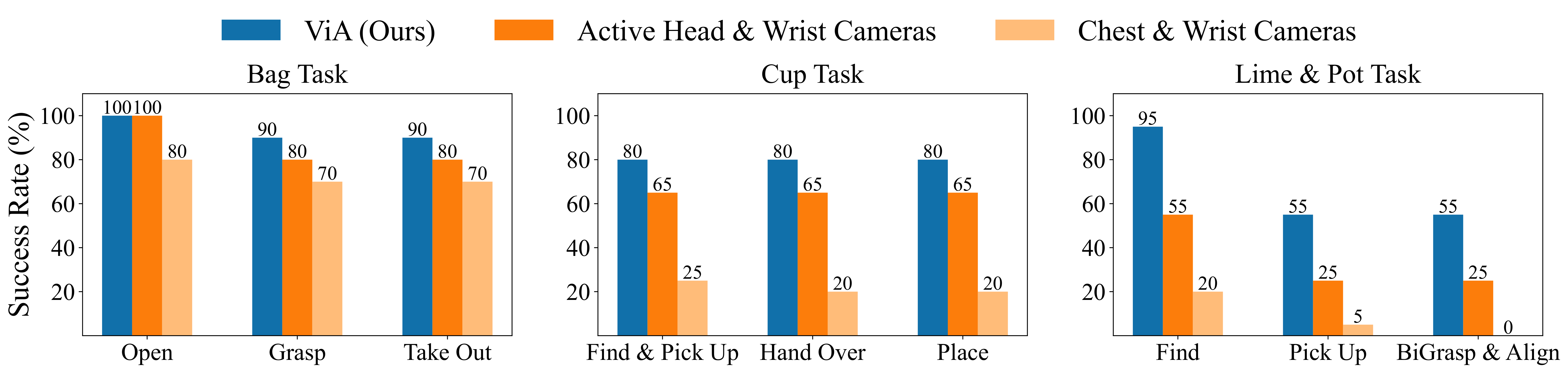
“Surprisingly, augmenting [ViA] with additional wrist camera observations ([Active Head & Wrist Cameras]) does not improve performance”.
- Additional views may introduce redundant or noisy observations, especially due to frequent occlusions during manipulation
Policy architecture:
- they use diffusion policy pretrained with DINOv2
My thoughts
More of an engineering paper. Interesting that head image alone does better than head + wrists images