Agent-Environment Interface
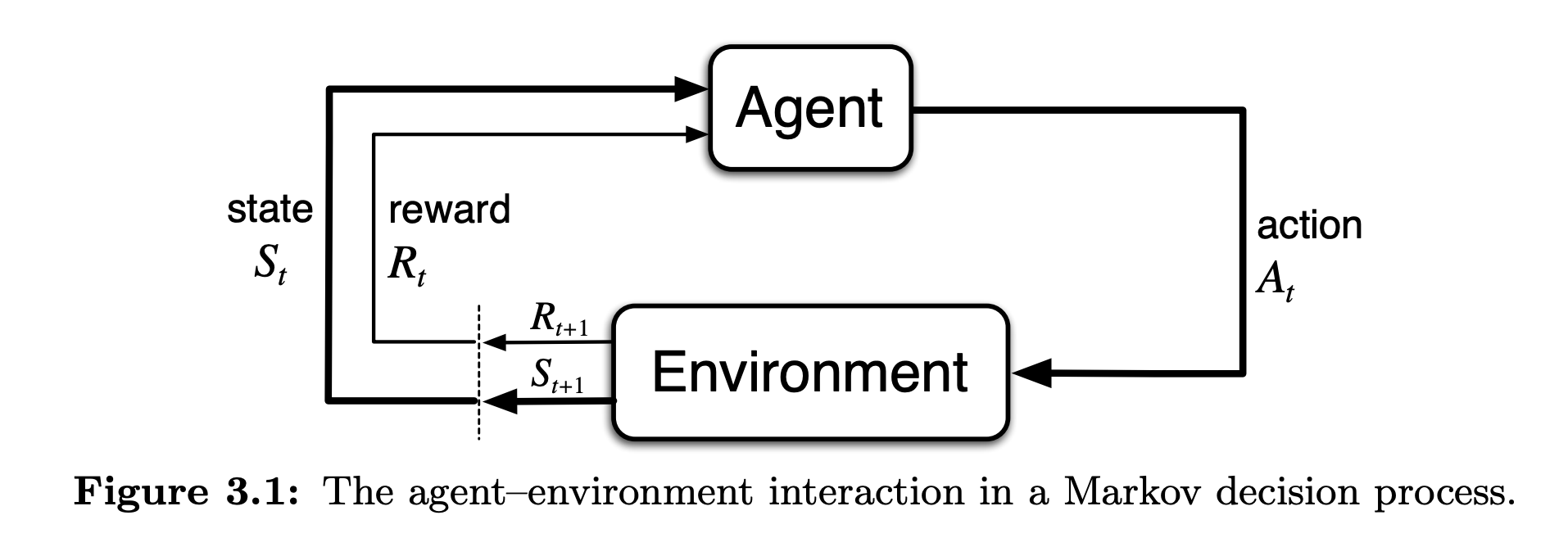 Agent: The learner and decision-maker
Environment: The thing the agent interacts with
Agent: The learner and decision-maker
Environment: The thing the agent interacts with
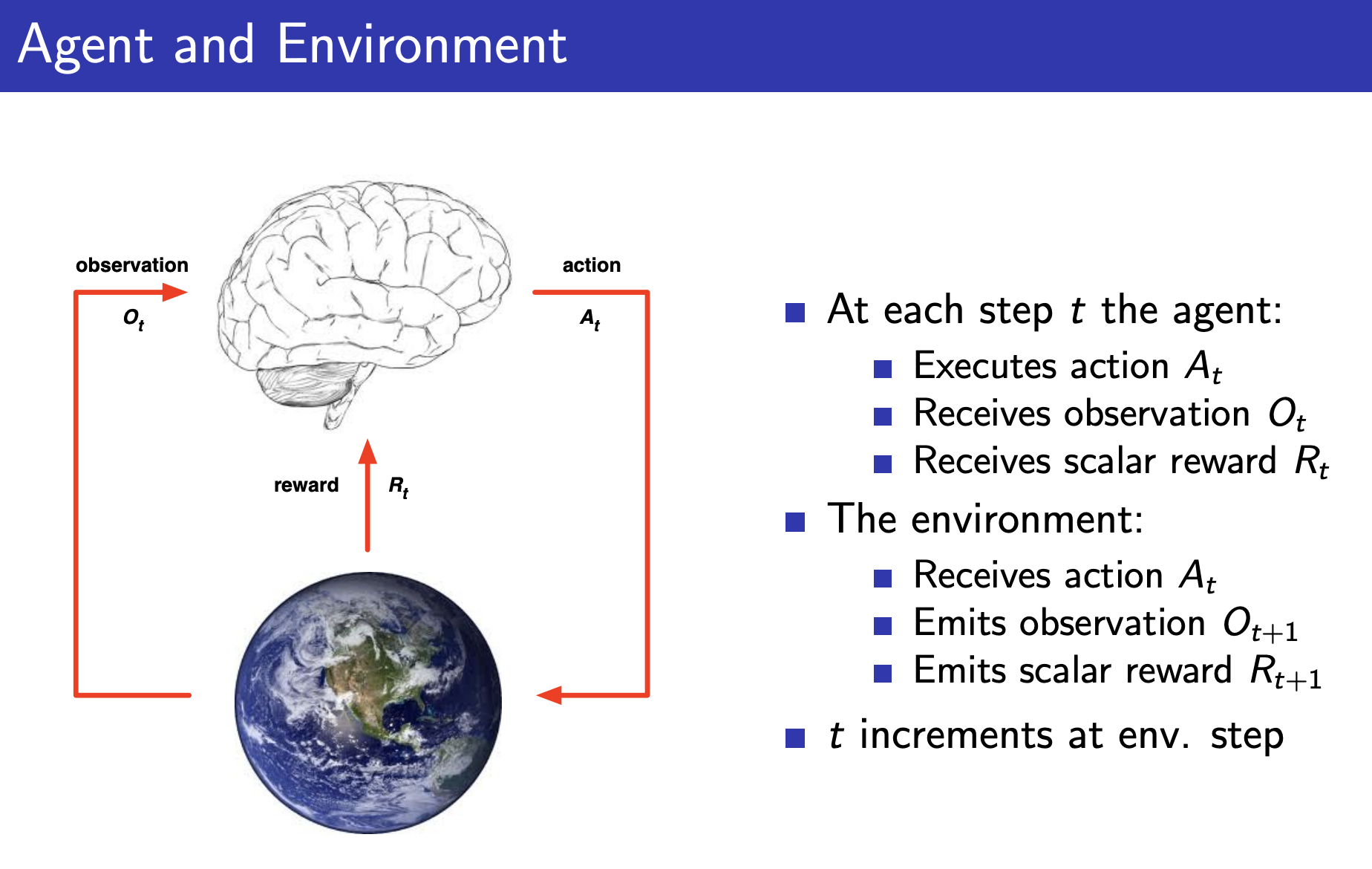
In a finite MDP, the sets of states, actions, and rewards are finite. So we have well defined discrete probability distributions.
specifies a probability distribution for each choice of and , tells us how likely we are to end up in a new state .
is decided by the environment, agent cannot modify this.
Instead, the agent modifies , the policy.