Reinforcement Learning (RL)
Reinforcement Learning (RL) was invented as a way to model and solve problems of decision making under uncertainty.
The goal is to maximize the expected sum of discounted rewards:
- where gives the likelihood of a trajectory under
Links
- RL Tips
- RL Papers: https://github.com/yingchengyang/Reinforcement-Learning-Papers
- Benchmarking: https://github.com/automl/CARL
- https://github.com/deepmind/open_spiel → Seems like an alternative to OpenAI Gym??
- https://stable-baselines3.readthedocs.io/en/master/guide/algos.html
Cool links to projects I found:
- https://github.com/eleurent/highway-env → Look at the README!!
- The default is
CarRacing-V0
- The default is
- https://github.com/clvrai/awesome-rl-envs
- https://github.com/bulletphysics/bullet3/ (alternative to MUJOCO?)
- https://github.com/DLR-RM/rl-baselines3-zoo (i sent this to Soham, but I don’t know how good it is)
Learning RL
- Honestly I feel like Foundations of Deep RL by Pieter Abbeel is all you need to a good introduction
- Course by David Silver (LEGENDARY) on YouTube
- Stanford CS234 on YouTube
- Spinning Up by OpenAI
- Sutton Book Solutions here
- Also on practice on Github, use your fork
- Extra Practice Problems, see here,
- Super helpful blog by Lilian Weng, OpenAI Lead for applied research
Why RL?
What makes reinforcement learning different from other machine learning paradigms?
- There is no supervisor, only a reward signal
- Feedback is delayed,
- not instantaneous
- Time really matters (sequential, non i.i.d data)
- Agent’s actions affect the subsequent data it receives
RL is like a one-size fits all solution.
Limitations
It seems, however, that sometimes RL doesn’t work yet. RL is sample inefficient. It requires millions of samples before it can learn something.
Deep RL is popular because it’s the only area in ML where it’s socially acceptable to train on the test set. I don’t care, so that’s great news for me!
I have this thought that RL is like at the intersection of many disciplines, and it feels so fascinating. Similar to my thoughts for Planning.
Sequential Decision Making
Goal: select actions to maximize total future Reward, which we call the expected return.
- Actions may have long term consequences
- Reward may be delayed
- It may be better to sacrifice immediate reward to gain more long-term reward
The main categories of RL algorithms are Value-Based vs. Policy-Based Methods.
Terms
- Markov Decision Process
- Reinforcement Learning Terminology
- Reward
- Agent-Environment Interface
- State
- RL Agent
- Bootstrapping (Reinforcement Learning)
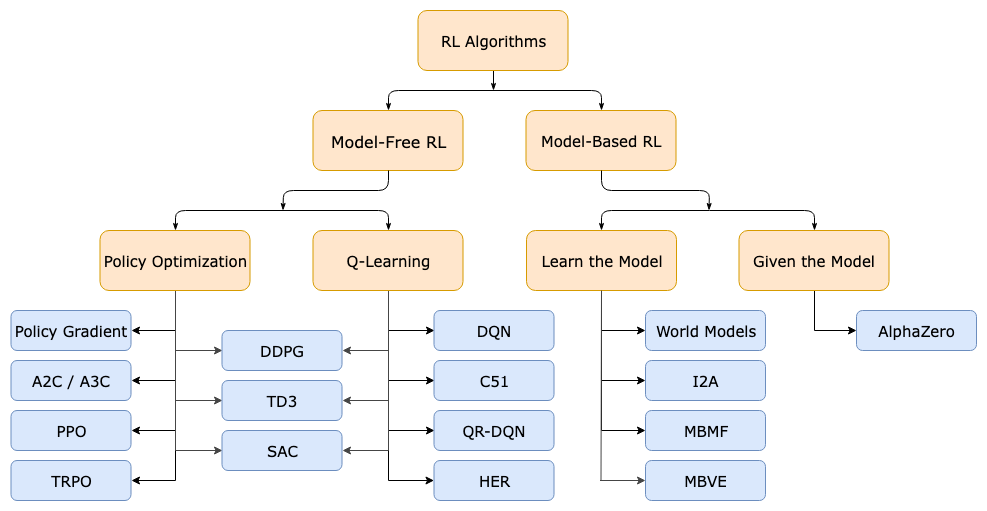
- Model-Based vs. Model-Free RL
- Evaluation and Control
RL vs. Planning
They are difference problem setups. In planning, we are already told in advance the setup of the game.
In reinforcement learning, the environment is initially unknown, the agent interacts with the environment and the agent improves its policy.
This is in contrast with planning. A model of the environment is known, and the agent performs computations with its model.
Incremental Implementation
This form occurs frequently throughout RL, where
Topics
Foundation of RL is this process called Generalized Policy Iteration, and all RL methods can be described as GPI (umm, only Q-learning ones).
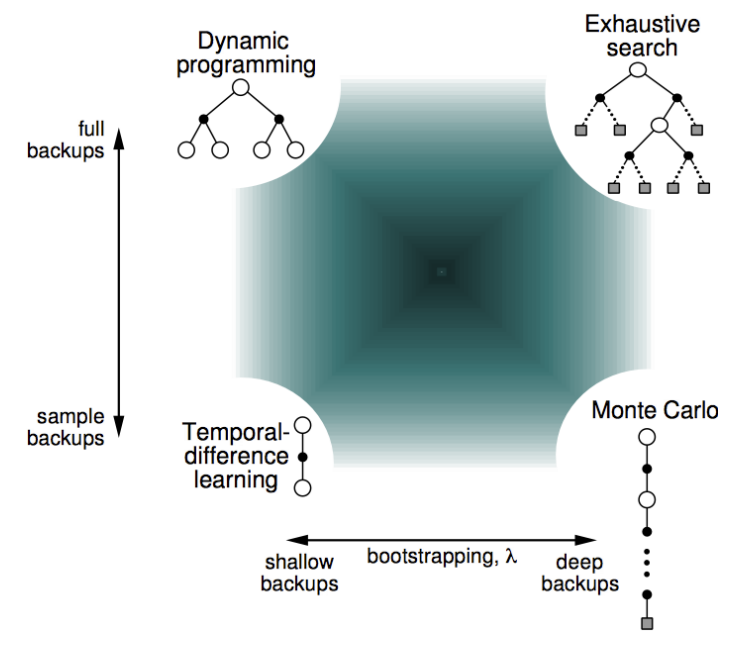
In Model-based, you can just use exhaustive search, and then optimize with Dynamic Programming in Reinforcement Learning.
- Value Function, introduced with Dynamic Programming in Reinforcement Learning
- Model-Free Policy Evaluation
- Using Dynamic programming
- Using Monte-Carlo Learning
- Using Temporal-Difference Learning
- Model-Free Control
- Monte-Carlo Control
- TD Control
- Sarsa (on-policy)
- Q-Learning (off-policy)
- Value Function Approximation
- Policy Gradient Methods Eligibility Trace
Online vs Offline Updates
Online: We modify the value function during the episode Offline: We only modify the value function after the episode has ended
Evolutionary Algorithms vs RL
See Page 8. Evolutionary methods ignore much of the useful structure of the RL Problem: they do not use the fact that the policy they’re searching for is a function from states to actions.
General Topics
- Searching Algorithms
- Knowledge Engineering
- Probability
- Optimization
- Research
- Exploration and Exploitation
- Imitation Learning
Questions I have
- So with this value function, the state representation, does it encapsulate time? I think it should encapsulate that yes, like say you win more points the faster you run, then that is captured in the state representation.