Boolean Retrieval
Learned in CS451.
Sample implementation
A boolean retrieval is a query that is formed using boolean operators.
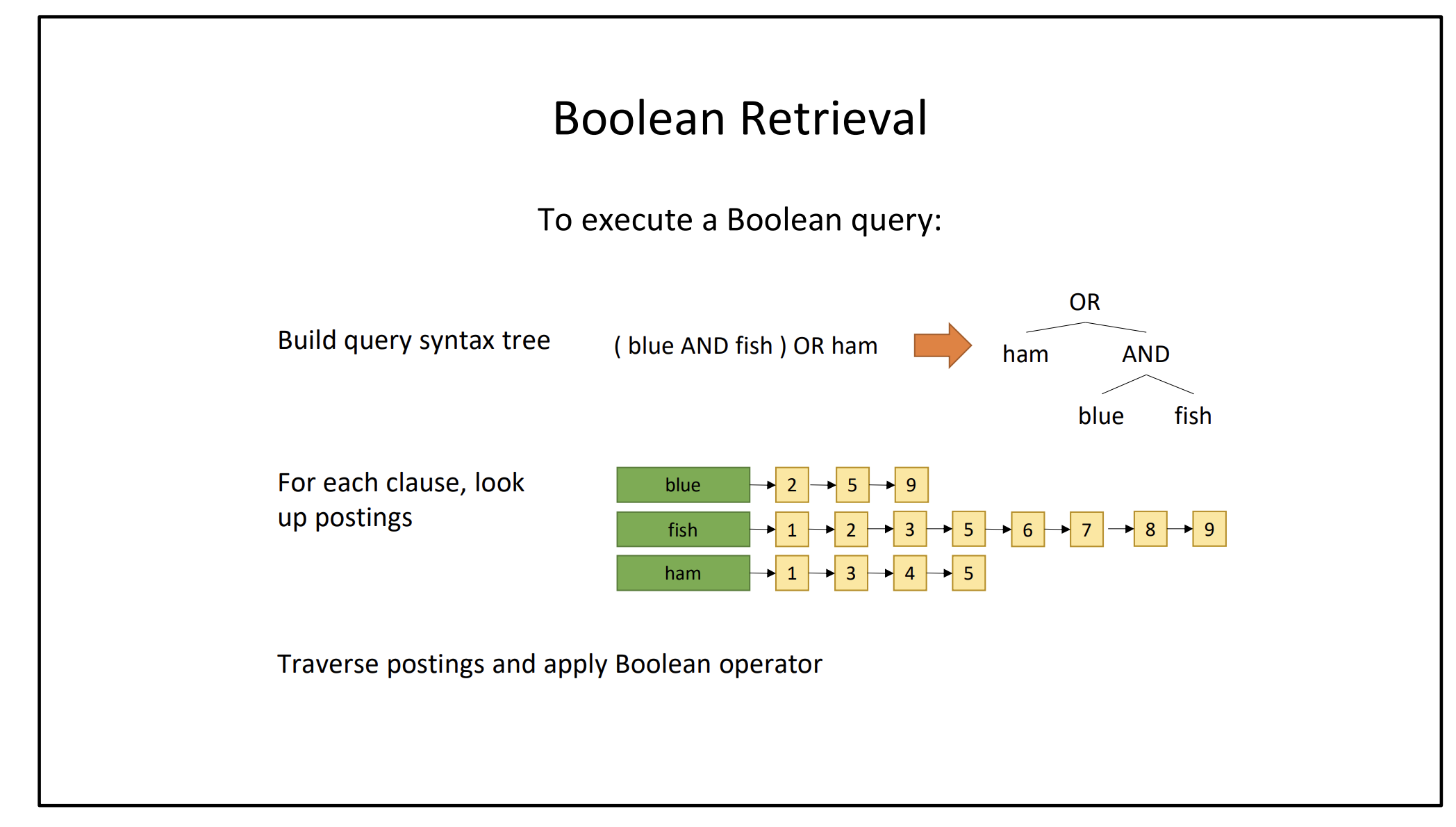
it will return the set of documents for which the query is true.
Two initial ideas:
- Term-at-a-time
- Document-at-a-time
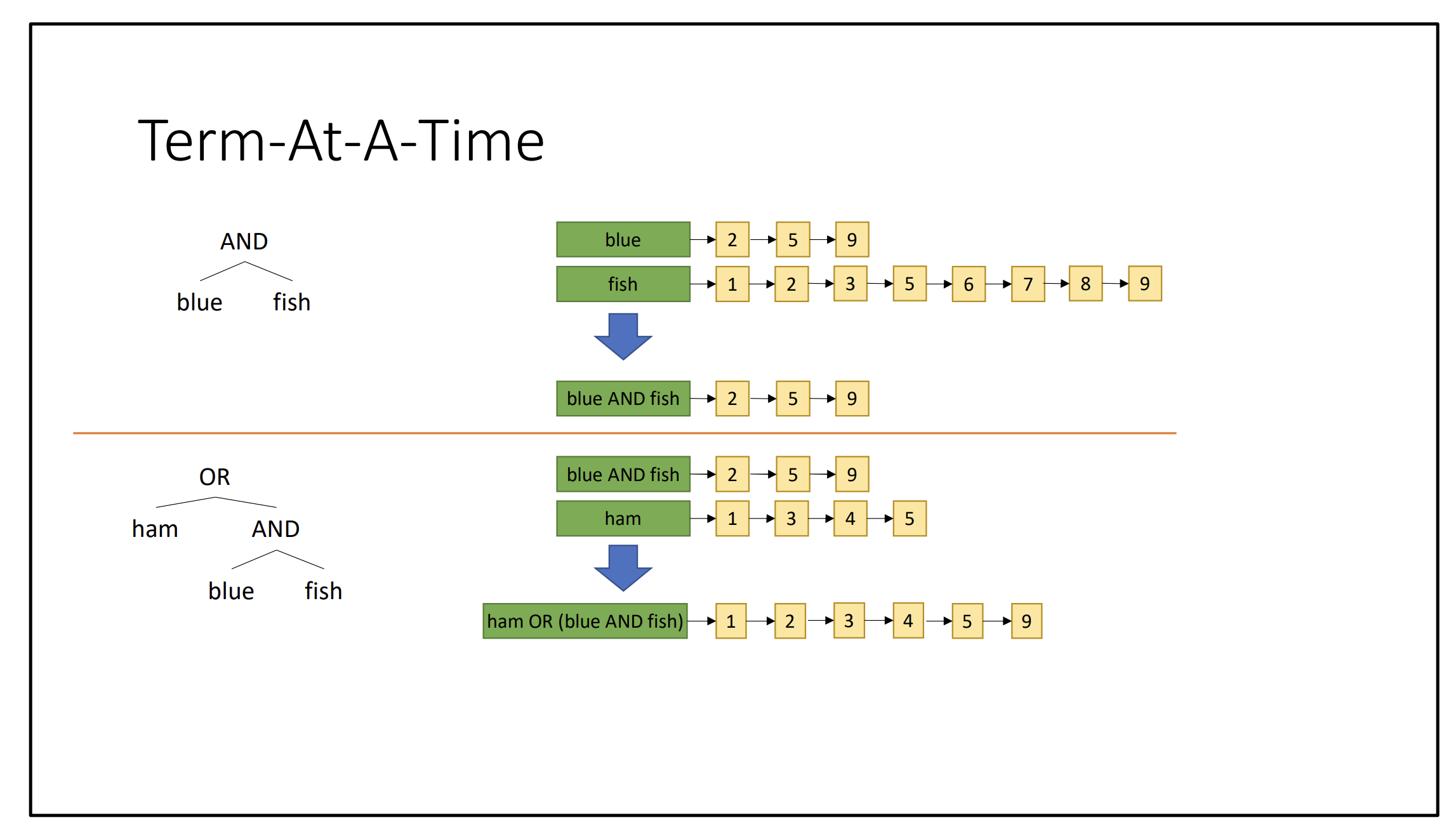
Term-at-a-time For each term, generate sets of documents
- AND = intersection
- OR = union
- NOT = negate
Document-at-a-time For each document, see if it passes the querySince documents are in sorted order, modified merge operation will work.

Doesn't this run out of memory? Since we're not doing map reduce?
The sample code doesn’t do it, but we can actually distribute lookup. We store inverted indices, and HDFS should partition by the words.

So there are 2 options to partition:
- Partition by term
- this makes sense in my head, but actually BAD. Because remember that the partition of the dataset directly determines which mapper it’s assigned to
- So if a word is in another partition, it’s like, how do you write map reduce for that?
- Partition by document ID
- Very easy! Just check the documents that have that word
Partition by document ID. Since all terms for a document are within the same partition, Boolean operations like “AND” or “NOT” can be processed locally for each partition. After processing, the results from all partitions can be combined (concatenated) efficiently.
No shuffle is needed, as operations are local to each partition.
Does this still work with term-at-a-time?
took some time to convince myself, but yes, it’s essentially a union of the results from the different partitions at the end.
You can think of term-at-a-time as starting from a set of documents, and then narrowing down the range.
- So you won’t need documents from elsewhere