Branch Prediction
Branch prediction is the CPU’s guess about whether a conditional branch will be taken, made early so the pipeline can keep fetching instructions down the predicted path.
First saw this idea in ECE222; heard George Hotz talk about it.
Why don't GPUs have branch prediction?
Because GPUs are built around a different bet: run tons of threads in parallel and hide latency, instead of making one thread run as fast as possible. Classic branch prediction is mostly a CPU trick for single-thread performance.
Difference with Speculative Execution?
Branch prediction is the guess (“will this branch be taken?”). Speculative execution is what the CPU does with that guess: actually running instructions down the predicted path into a renamed register set, ready to roll back if the guess was wrong. Prediction feeds speculation.
Speculation is also broader: value speculation speculates on a load’s result, not a branch. Branch prediction is just the most important case.
From ECE459 L07
If a pipelined CPU hits a branch, it can’t know the next instruction until the branch nearly finishes. This breaks Pipelining, which gave us really really good speedup.
How branch prediction affects pipelining
- Guess right → save time
- Guess wrong → flush the pipeline. The deeper the pipeline, the higher the miss penalty.
Cartoon model (20% branches, 1 cycle for non-branch / correct branch, 20 cycles for misprediction):
- No prediction:
0.8·1 + 0.2·20 = 4.8cycles/inst. - Perfect:
1.0cycle/inst, a 4.8× speedup.
Evolution of branch predictors
All cycle counts come from the cartoon model above.
1. Predict taken (~70% → 2.14 cycles/inst). Just guess “taken” for every branch. No hardware state at all.
Why it works: loops dominate real programs, and loop branches are almost always taken.
2. BTFNT, Backwards Taken, Forwards Not Taken (~80% → 1.76). Look at the branch target address.
- Backwards branch (target < current) → predict taken (likely a loop back-edge)
- Forwards branch (target > current) → predict not taken (likely an error/exception path)
Used by PPC 601 (1993) and 603. Still static: same prediction every time.
3. 1-bit dynamic (~85% → 1.57). Start using runtime behavior. Each branch gets a 1-bit table entry: “was this taken last time?“. Predict same as last time. Indexed by low bits of the branch address (aliasing possible when two branches hash to the same entry).
Problem: a loop of N iterations mispredicts twice: once entering (the previous run ended “not taken”) and once exiting. DEC EV4 (1992), MIPS R8000 (1994).
4. 2-bit saturating counter (~90% → 1.38). Each entry is a counter 00–11. Taken → increment (saturate at 11), Not-taken → decrement (saturate at 00). Predict taken if counter ≥ 10.
state: 11 (strongly taken) → 10 (weakly taken) → 01 (weakly not) → 00 (strongly not)
Needs two wrong guesses in a row to flip prediction, so one anomaly (e.g.
TTTTNT) doesn’t cost a double misprediction. LLNL S-1 (1977) through Intel Pentium (1993).
5. Two-level adaptive, global (~93% → 1.27). The counter schemes still make the same prediction every visit to a branch. But some branches depend on recent history, e.g. for (i = 0; i < 3; ++i) has pattern TTN, TTN, TTN.... Solution: keep a shift register of the last N branch outcomes (the branch history), combine with the branch address to index the counter table.
(branch address | global history) → table of 2-bit counters → predict
Shared global history handles cross-branch correlations. Pentium MMX (1996, 4-bit global history).
6. Two-level adaptive, local (~94% → 1.23). Same idea, but keep a separate history per branch. Each branch’s own pattern indexes its own counter.
More accurate when branches have independent patterns, at the cost of more hardware. Pentium Pro (1996), II (1997), III (1999).
7. gshare. Instead of concatenating address + history (which uses bits inefficiently), XOR them. Same accuracy, cleaner hardware.
Modern branch prediction
After this point, more sophisticated predictors handle aliasing (different branches mapping to the same table entry) but gains are small; we’re close to the ceiling.
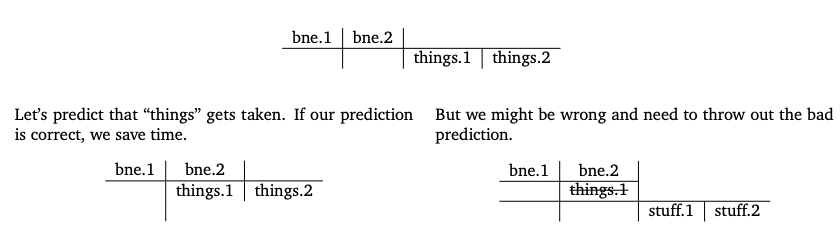
gcc’slikely()/unlikely()hints rearrange instructions per your prediction. Experiment in the slides: no measurable benefit, slight penalty when wrong. Don’t try to outsmart the compiler.
Aliasing in prediction tables (different branches mapping to the same entry) is still a concern but modern CPUs handle it well.