Coroutine
Going to learn this in CS343. Actually introduced in SE350.
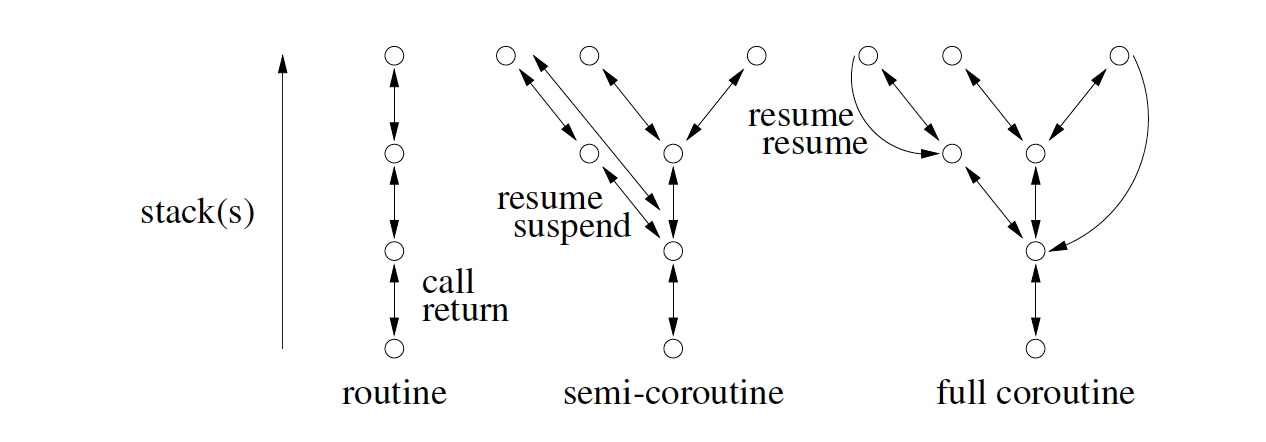
A coroutine is a routine that can also be suspended at some point and resumed from that point when control returns.
The state of a coroutine consists of:
- an execution location, starting at the beginning of the coroutine and remembered at each suspend.
- an execution state holding the data created by the code the coroutine is executing. ⇒ each coroutine has its own stack, containing its local variables and those of any routines it calls.
- an execution status—active or inactive or terminated—which changes as control resumes and suspends in a coroutine.
Difference between Routine and Coroutine?
A coroutine can suspend its execution and return to the caller without terminating, a coroutine cannot.
- A coroutine is activated at the point of last suspension.
- A routine always starts execution at the beginning and its local variables only persist for a single activation.
Coroutines are designed to be able to pass execution control back and forth between themselves.
Semi-Coroutine
Semi-Coroutine
A semi-coroutine acts asymmetrically, like non-recursive routines, by implicitly reactivating the coroutine that previously activated it.
Full Coroutine
Full Coroutine
A full coroutine acts symmetrically, like recursive routines, by explicitly activating a member of another coroutine, which directly or indirectly reactivates the original coroutine (activation cycle).
Semi vs Full — it's about who gets
resume()dWhen a semi-coroutine calls
resume(), it resumes itself at its lastsuspend().A full coroutine can call
resume()on another coroutine, forming an activation cycle between multiple coroutines.
PingPong — two full coroutines passing control back and forth:
_Coroutine PingPong {
const char * name;
const unsigned int N;
PingPong * part;
void main() {
for ( unsigned int i = 0; i < N; i += 1 ) {
cout << name << endl;
part->cycle(); // resume the OTHER coroutine
}
}
public:
PingPong( const char * name, unsigned int N, PingPong & part )
: name(name), N(N), part(&part) {}
PingPong( const char * name, unsigned int N )
: name(name), N(N) {}
void partner( PingPong & part ) { PingPong::part = ∂ }
void cycle() { resume(); }
};
int main() {
enum { N = 20 };
PingPong ping("ping", N + 1), pong("pong", N, ping);
ping.partner(pong);
ping.cycle(); // kick off the cycle
}Fibonacci Sequence
So the teacher’s motivation for this is first, let’s consider using global variables. But then that isn’t extendible super well to multiple instances.
- You want to encapsulate global variables into structure variables, and then pass these into each coroutine
Ahh i understand, so the state is stored.
resume()transfers to the lastsuspend()`.
Example for fibonacci
Coroutine Fibonacci { // : public uBaseCoroutine
int fn; // used for communication
void main() { // distinguished member
int fn1, fn2; // retained between resumes
fn = 0; fn1 = fn;
suspend(); // return to last resume
fn = 1; fn2 = fn1; fn1 = fn;
suspend(); // return to last resume
for ( ;; ) {
fn = fn1 + fn2; fn2 = fn1; fn1 = fn;
suspend(); // return to last resume
}
}
public:
int operator()() { // functor
resume(); // transfer to last suspend
return fn;
}
};The main program:
int main() {
Fibonacci f1, f2; // multiple instances
for ( int i = 1; i <= 10; i += 1 ) {
cout << f1() << " " << f2() << endl;
}
}Important
Eliminate computation or flag variables retaining information about execution state.
This is because the variables might change (?) No, because its bad
- In coroutine-based programming, you want to avoid such explicit logic and let the coroutine’s suspension and resumption naturally guide the flow of execution.
The purpose of coroutines is to simplify the flow, making it more linear and removing state-related logic.
- It’s a way to think about the problem
for ( int i = 0; i < 10; i += 1 ) {
if ( i % 2 == 0 ) // even ?
even += digit;
else
odd += digit;
suspend();
}for (int i = 0; i < 5; i+=1) {
even += digit;
suspend();
odd += digit;
suspend();
}When possible, simplest coroutine construction is to write a direct (stand-alone) prog
Convert to coroutine by:
- putting processing code into coroutine main,
- converting reads if program is consuming or writes if program is producing to suspend,
- Fibonacci consumes nothing and produces (generates) Fibonacci numbers ⇒ convert writes (cout) to suspends.
- Formatter consumes characters and only indirectly produces output (as side-effect) ⇒ convert reads (cin) to suspends.
- use interface members and communication variables to to transfer data in/out of coroutine
This approach is impossible for advanced coroutine problems.
The tree traversal stuff
Implementation: Stackless vs Stackful
See Stackless vs Stackful Coroutine. uC++ is stackful, each coroutine instance gets its own stack, which is why the tree-walk below can suspend() from inside a recursive helper.
How _Coroutine is implemented (Buhr §3.6)
Every _Coroutine is a uBaseCoroutine subclass whose instance owns:
- a separately allocated stack (default 64 KB, configurable)
- a context block holding saved callee-save registers + stack pointer + instruction pointer for the last suspend point
- a status field (Start / Active / Inactive / Halt)
- a starter pointer to the coroutine that first
resumed it, for semi-coroutine return
resume() / suspend() are non-preemptive context switches between two coroutines:
resume() on caller side:
save caller's callee-save regs + SP + return address into caller's context block
load callee's context block into CPU (SP, PC, regs)
return jumps to callee's saved PC, now running on callee's stack
Because the switch just swaps stacks and a handful of registers, it’s orders of magnitude cheaper than a kernel thread switch, no TLB flush, no syscall, no scheduler.
First resume bootstraps
mainOn a coroutine’s first resume, the context block is synthesized so that the loaded PC points at a small trampoline that calls the coroutine’s
main(). Ifmainreturns, the coroutine transitions to Halt and control returns to whoever resumed it last. Subsequent resumes go to the saved PC of the lastsuspend().
Stack overflow is your problem
The per-coroutine stack is fixed size with a guard page. Deep recursion + large local arrays can blow it silently without the OS catching it cleanly, uC++ installs a guard but the diagnostic is “segfault in coroutine X”, not a nice overflow exception. Size stacks with
uBaseCoroutine::verify()in debug builds.
template <typename T>
class Btree {
struct Node {
...
};
... // other members
public : _Coroutine Iterator {
Node* cursor;
void walk(Node * node) { // walk tree
if (node == nullptr) return;
if (node->left == nullptr && node->right == nullptr) { // leaf?
cursor = node;
suspend(); // multiple stack frames
} else {
walk(node->left); // recursion
walk(node->right); // recursion
}
}
void main() {
walk(cursor);
cursor = nullptr;
}
public:
Iterator(Btree<T> & btree) : cursor(&btree.root) {}
T* next() {
resume();
return cursor;
}
};
... // other members
};
template <class T>
bool sameFringe(BTree<T>& tree1, BTree<T>& tree2) {
Btree<T>::Iterator iter1(btree1), iter2(btree2); // iterator for each tree
T *t1, *t2;
for (;;) {
t1 = iter1.next();
t2 = iter2.next();
if (t1 == nullptr | | t2 == nullptr) break; // one traversal complete ?
if (*t1 != *t2) return false; // elements not equal ?
}
return t1 == nullptr && t2 == nullptr; // both traversals completed ?
};