Data Communication
Motivating Concurrency and Distributed Systems.
How does data flow? These are notes from Hemal Shah that learned during my time at NVIDIA.
Understanding this will help you understand how to achieve Accelerated Computing.
Data communication can be broken into 3 categories:
- Intra process (Concurrency through Multithreading)
- Inter process - same machine (IPC, Distributed Systems)
- Inter process - different machine (IPC, Distributed Systems)
The problem with ROS is that they only make distinctions between 2 things: intra-process and inter-process communication.
The distinction is important for inter-process communication when we work on NITROS.
Let’s think about how memory works:
- With intra-process communication, you are essentially sharing memory across different threads, and since they are from the same process, you don’t need to worry about retrieving the same memory.
- With inter-process communication - same machine, you need to allocate Shared Memory, because the OS reserves memory on a per process level. If another process accesses memory that it is not allowed to access, it gets a Segmentation Fault. However, if you let the OS know ahead of time, it can allocate Shared Memory, and then both processes store pointers to the memory address
- Now, what about inter-process, different machines? These different processes are on completely different machines! You would be sending a memory address to another process on another machine, but think about what this means… this other process is not physically connected to the same Main Memory anymore. So you need to send it over some network, using something like protobuf.
- But recently, there’s something called RDMA, though I don’t fully understand…
Now, with inter-process communication - different machines, you also need to think about how this data is actually packaged and sent.
There are 2 things done together
- Serialization: convert its state into a byte stream in such a way that the byte stream can be converted back into a copy of the object.
- Marshalling: converting memory representation for transmission?
So what is the actual practical difference between Concurrency and Distributed Systems?
Distributed systems is a lot more worried about reliability. If one of your nodes die on a distributed system, the rest of the system is still up. But in concurrency, since all your nodes are part of the same process, if one of the nodes die, then the entire system dies.
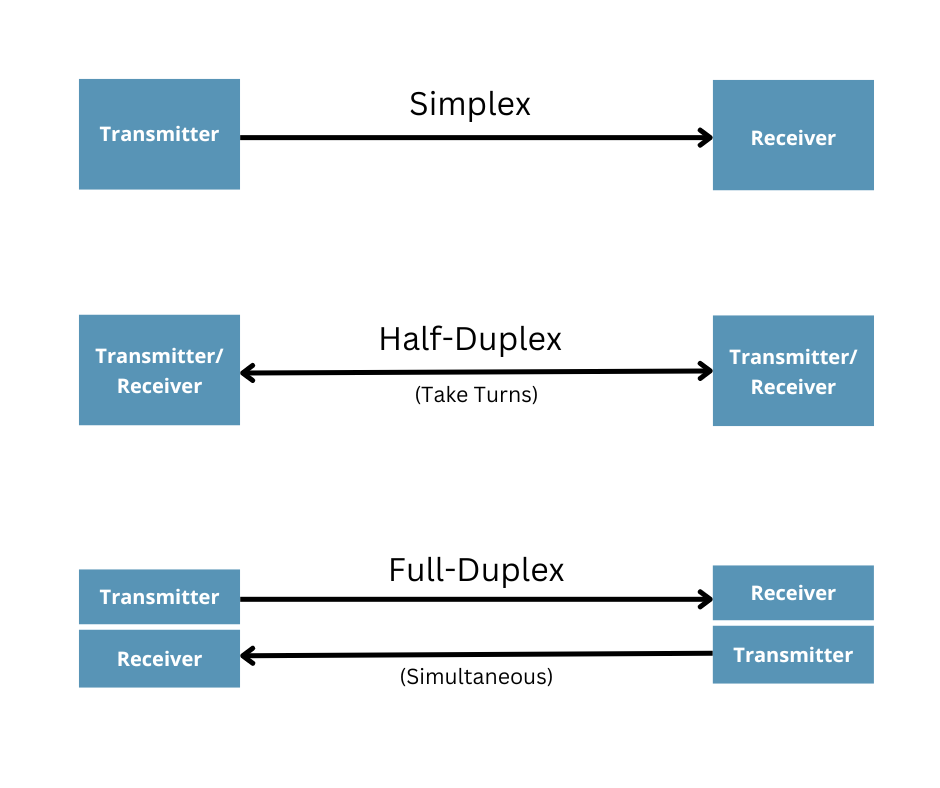
Data Flow Categories
Data Flow Categories
| Type | Communication | Example |
|---|---|---|
| Simplex | Unidirectional | Radio broadcast |
| Half-Duplex | Bidirectional but not at the same time | Walkie-Talkies |
| Full-Duplex | Bidirectional | Telephone-line |