GPU Optimization
GPU optimization is the craft of pushing a CUDA workload closer to peak hardware throughput by identifying which of memory, compute, or kernel overhead is the current bottleneck, then applying the technique that attacks that bottleneck. Domain-specific stacks like LLM Optimization are really specialized applications of this taxonomy.
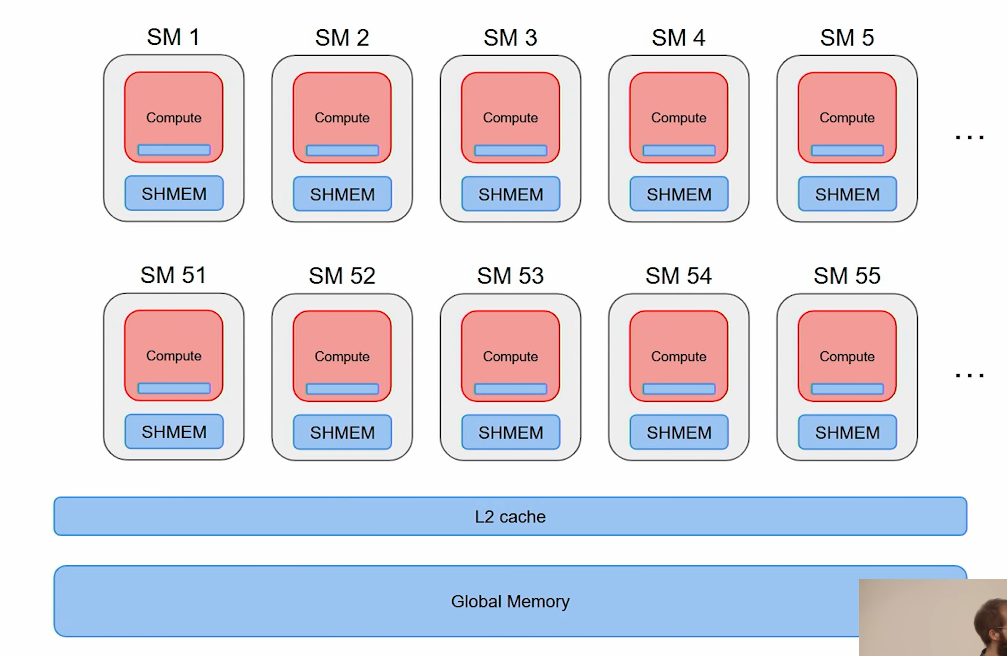
- Source: Jane Street ML Talk
Why does this taxonomy matter?
Naive C of a 2048×2048 matmul on an Apple M2 hits ~0.005% of peak. Hand-vectorized + cache-blocked across all CPU cores: ~1%. The Neural Engine: ~80%. Six orders of magnitude on the same chip (MIT 6.S894 Lec 1, slides 13-23). Every rung you climb is a memory, compute, or kernel-overhead win, and you can’t reason about which one without knowing where the workload currently sits. See MIT 6.S894 for the framing.
Guiding principles
- data reuse, keep data in registers and shared memory as long as possible, load once and use many times
- Latency hiding, overlap slow memory transfers with computation via prefetching and CUDA streams
The 3 bottlenecks
- Memory: GPU is busy moving data around, very little time on compute. Lots of HBM ↔ SRAM traffic relative to FLOPs. Attack with locality
- Compute: most time is actual computation. Generally a good state, but may still be pushable with Tensor Cores or better algorithms. Profile with Nsight Compute
- Kernel overhead: launch overhead dominates, especially with many short kernels. Attack with fusion or CUDA Graphs
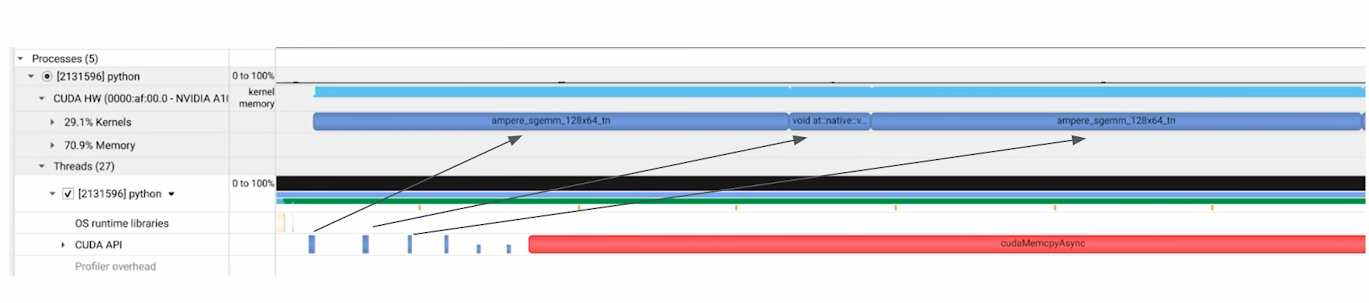
- visualization of kernel launching
- Memory bottleneck (within GPU):
- Compute Bottleneck:
- Kernel Overhead:
- Kernel Fusion
- Leverage CUDA Graph
More techniques inside LLM Optimization.
CUDA optimization checklist (PMPP Table 6.1)
A list of techniques taken from the PMPP book:
- Maximize occupancy
- Enable memory coalescing by being aware of RAM access order
- Minimize control divergence within warps
- Tiling
- Privatization, each thread works on its own copy, reduce at the end
- Thread coarsening, do more work per thread to amortize per-thread overhead
Profiling
Use Jupyter Nsight and Nsight Systems to see which bottleneck you’re actually hitting before picking a technique.