KV Cache
https://www.youtube.com/watch?v=80bIUggRJf4
This is a really good explanation by a guy who was explaining LLamA:
https://medium.com/@joaolages/kv-caching-explained-276520203249
Cursor team explaining KV cache: https://www.youtube.com/watch?v=PncVSWbxdWU
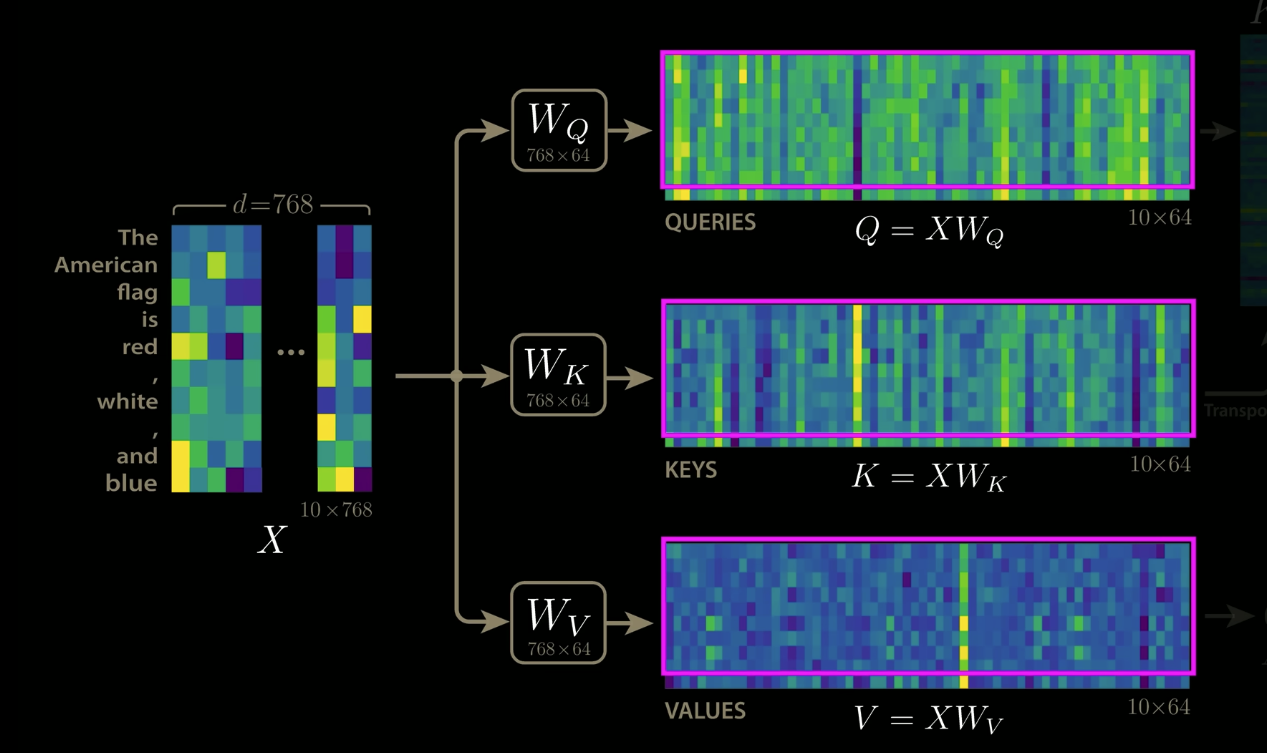
- A new row gets added for query, key and value matrices
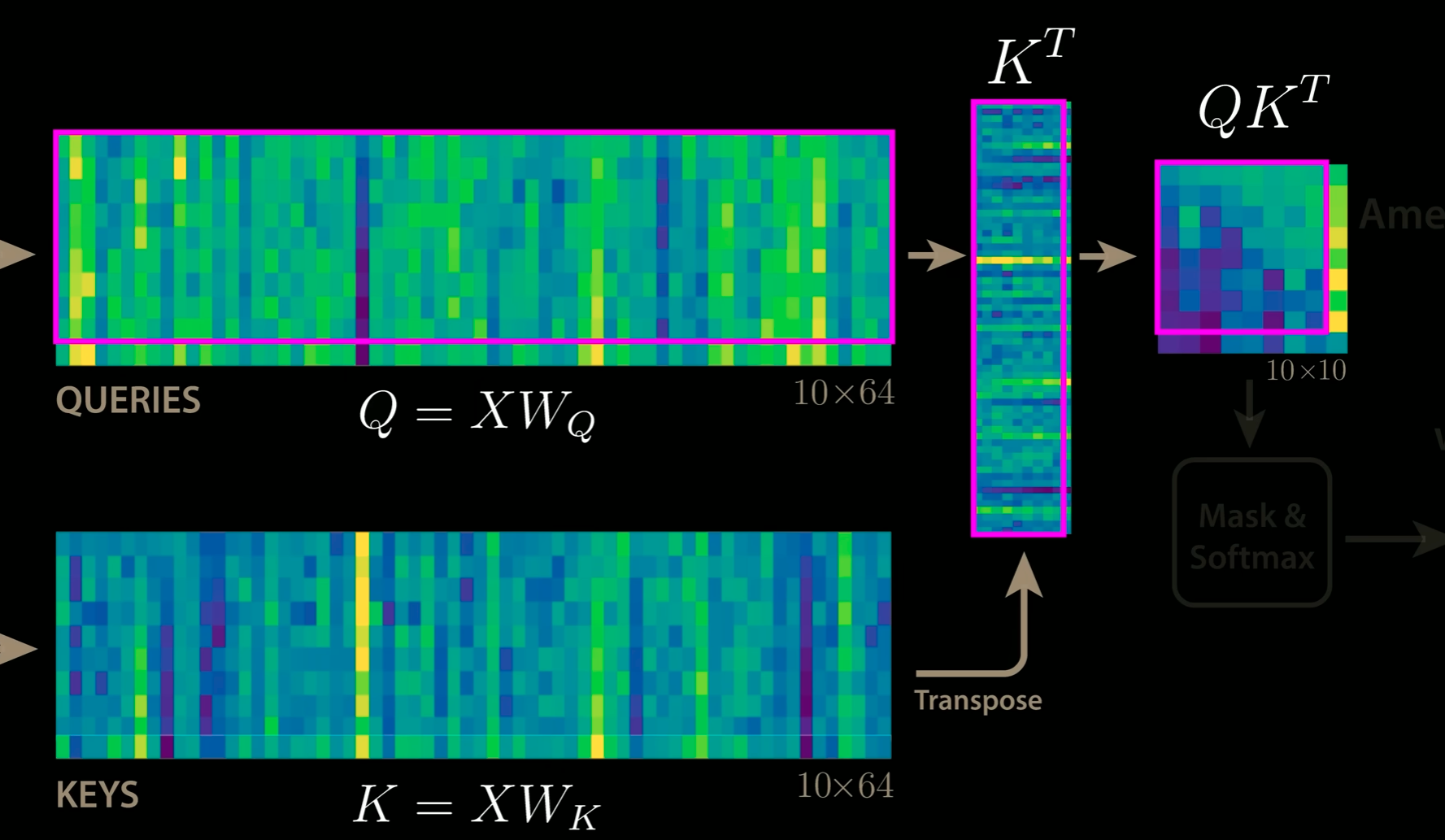
Notice that for QK^T, we only need to compute the new column and row.
- BUT ACTUALLY, we mask out the right column before applying softmax, so we don’t even need to compute the right column!! only the bottom row, which requires multiplying the new Q entry by K (so K needs to be cached)
This is actually the best explanation:
The same logic applies to the value matrix.
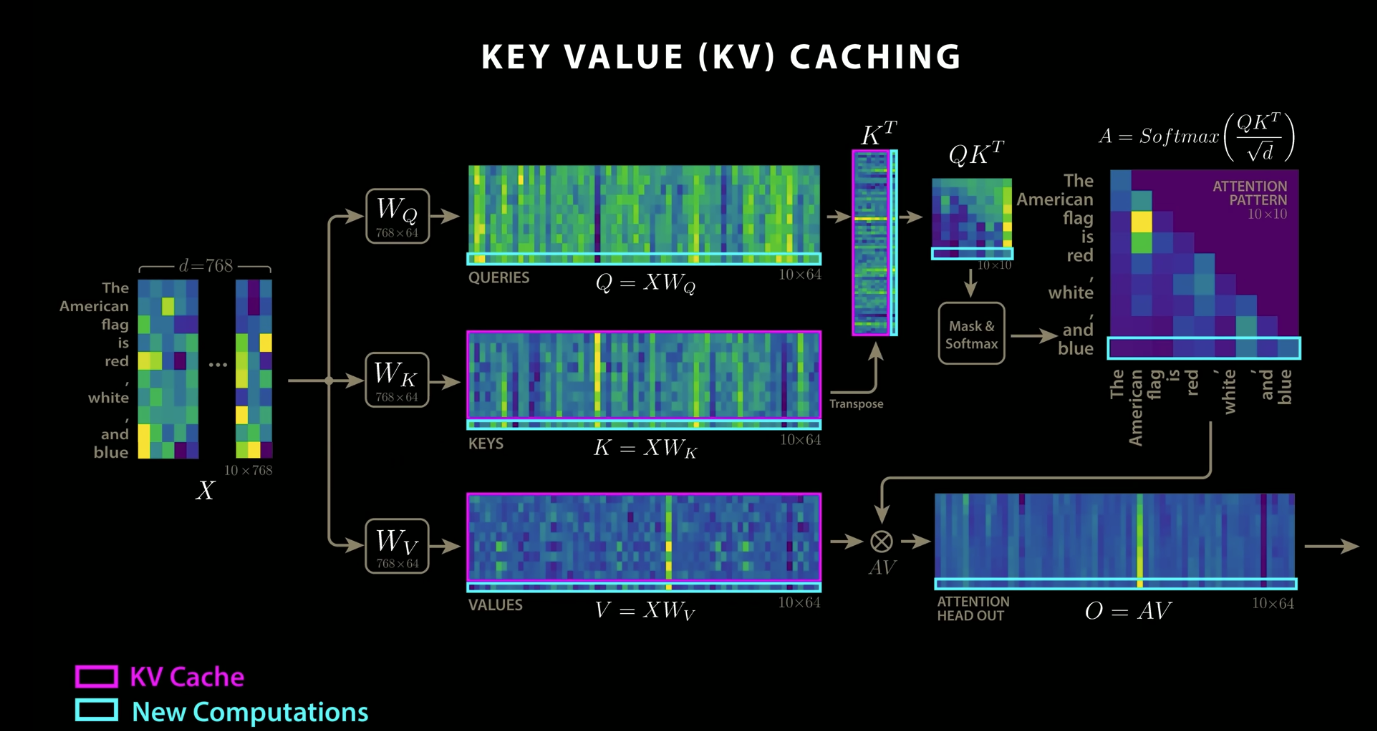
- This is such a great visualization explanation