Layer Normalization
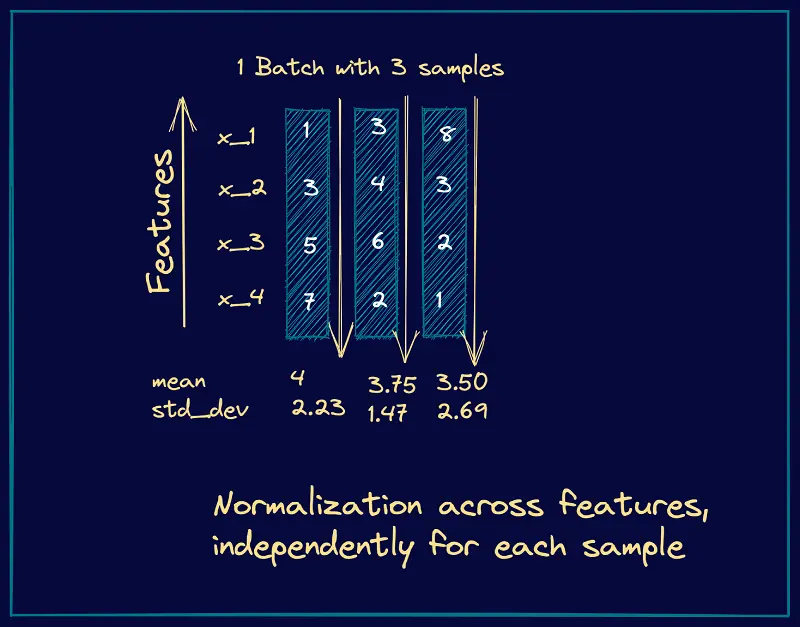
Layer normalization applies normalization across features instead of across batches in the case of BatchNorm.
First introduced from CS480 teacher at UWaterloo while learning about transformers.
Why layer norm?
LayerNorm was originally proposed as an alternative to Batch Normalization that doesn’t depend on batch statistics and works well for recurrent networks.
Why do transformers use layer norm?
Resources
- Original paper Layer Normalization
- Pytorch https://pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html
- https://www.pinecone.io/learn/batch-layer-normalization/
Refer to Transformer.
In NLP tasks, the batch size is often very small. Batch normalization might not be a good choice. Instead, layer norm is used.
Formula:
- and are learnable parameters
- is calculated via the biased estimator, equivalent to torch.var(input, unbiased=False).
- is for numerical stability
This formula is IDENTICAL to BatchNorm lol
We are just doing standardization across features, as opposed to across a batch.
The number of parameters learned remaining the same.
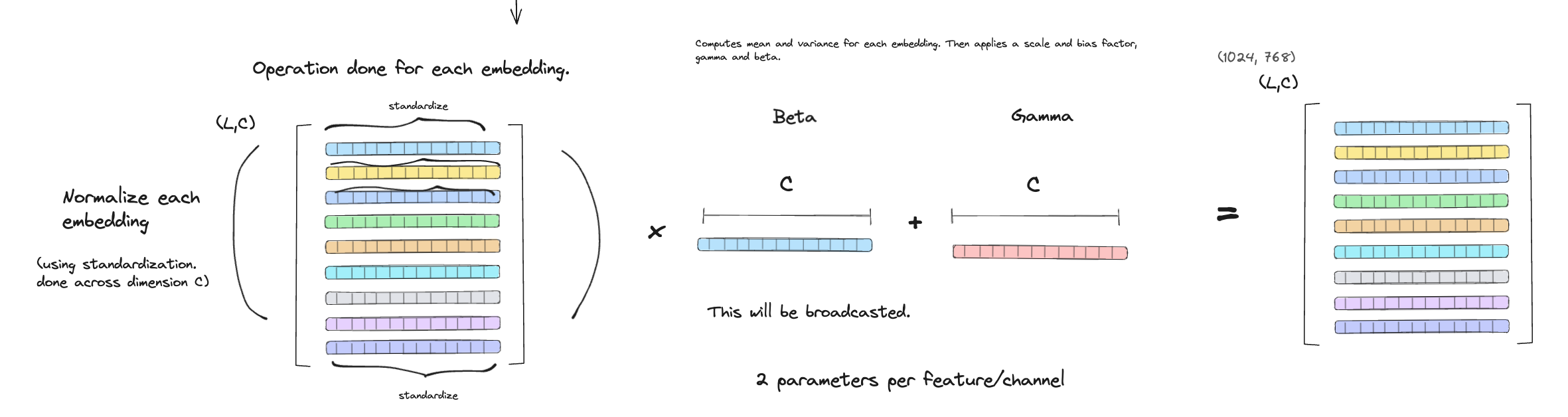
LayerNorm operates per token, meaning it normalizes across the D dimensions for each position in the sequence.
I was confused about this
gamma and beta of size d (the feature dimension), shared across all tokens/batch samples — just like in batch norm, it’s “one gamma per feature.”
- Even though you are normalizing across the embedding dimension, you will learn a and for each feature.
- It’s not a 2 parameters per axis of normalization, but rather 2 parameters per feature dimension
The mean and standard-deviation are calculated over the last D dimensions.
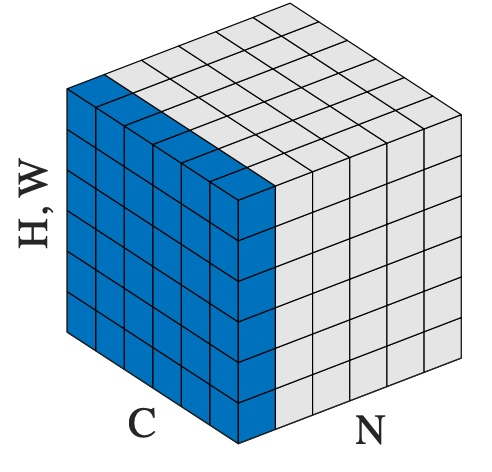
- From Pytorch link