Transformer
The Transformer is an attention-based architecture that processes sequential data in parallel, replacing recurrence with self-attention over tokens.
Why attention over RNN?
RNNs process tokens sequentially, limiting parallelism. Transformers let every token see every other in one matmul.
Architecturally, there’s nothing about the transformer that prevents it from scaling to longer sequences. The limit is that attention produces an matrix, which becomes huge.
Intuition
A Transformer block does exactly two things: mix tokens (self-attention) and think per token (MLP). Attention decides who talks to whom; the MLP then does the actual per-token computation. Stack this, and you get a model where any token can reach any other in one hop.
![]()
A rough draft of the dimensions (inspo from Shape Suffixes)
B: batch size
L: sequence length
H: number of heads
C: channels (also called d_model, n_embed)
V: number of models
input embedding (B, L, C)
Components
- Feedforward
- LayerNorm
When you compute attention, is it (L,C) * (C,L) or (C, L) * (L,C)?
- We want to model the relationship between every token to every other word in the sequence i.e. (L, L)
You get a matrix of shape
(B, h, L, d_k) @ (B, h, d_k, L) → (B, h, L, L)
From 3B1B: There’s masking, so that your current word doesn’t affect the previous word.

- Really good visualization from 3b1b
Resources
- Annotated transformer
- Illustrated transformer
- LLM Visualization
- Original paper Attention Is All You Need by Vaswani et. al.
- https://goyalpramod.github.io/blogs/Transformers_laid_out/
- Attention is all you need (Transformer) - Model explanation (including math), Inference and Training by Umar Jamil
- the slides
- Just read this blog
- I really liked these slides from Waterloo’s CS480
Some really good videos:
- History of Transformers
- The Transformer Architecture
- Vision Transformer (An Image is Worth 16x16 Words) video
- Swin Transformer
- Vision Transformers
Attention computes importance.
So the left is the attention block.
Think of it as a multi-class classification for 32K tokens.
Nis the number of layersDon’t be confused. it’s NOT the number of layers of the feedforward network. This is the number of blocks.
- is like 40 for LLama
- can be 512
Transformer block (CS231n 2025 Lec 8)
A Transformer is a stack of identical Transformer blocks. Each block takes a set of vectors and returns of the same shape, via two sub-layers:
- Multi-head self-attention: the only place vectors interact
- MLP applied independently to each vector (also called FFN / feed-forward network)
Each sub-layer wrapped in a residual connection and followed by LayerNorm:
x → SA → +x → LayerNorm → MLP (per-vector) → +x → LayerNorm → y
The MLP is usually two linear layers with . Most of the compute is 6 matmuls: 4 from self-attention + 2 from the MLP. Because SA is the only token-mixing step and everything else is pointwise, the block is highly parallelizable.
The widening is a sparse memory: the model projects into a wider space, picks out nonlinear features with the activation, then projects back. Think of it as “per-token lookup table” that runs after tokens have just mixed information.
Scale over time (same architecture, bigger numbers)
| Model | blocks | heads | seq | params | |
|---|---|---|---|---|---|
| Vaswani et al. 2017 | 12 | 1024 | 16 | 512 | 213M |
| GPT-2 (2019) | 48 | 1600 | 25 | 1024 | 1.5B |
| GPT-3 (2020) | 96 | 12288 | 96 | 2048 | 175B |
Transformer LM architecture
- Embedding matrix at the input: lookup table from token id to -dim vector
- Stack of Transformer blocks with masked self-attention (each token sees only earlier tokens)
- Projection matrix at the output: project each -dim vector to -dim logits over the vocab
- Train with softmax + cross-entropy on next-token prediction
Modern tweaks to the 2017 block
The architecture has barely changed since 2017, but a few modifications have become standard:
- Pre-Norm (Baevski & Auli 2018): move LayerNorm inside the residual path. Original (post-norm) has LN outside the residual, meaning the model can’t even learn the identity function. Pre-Norm training is noticeably more stable. With pre-norm the residual stream flows unmodified from input to output; each block only has to learn what to add
- RMSNorm (Zhang & Sennrich 2019) replaces LayerNorm: with . No mean-centering, no bias, slightly more stable
- SwiGLU MLP (Shazeer 2020) replaces the classic with . Setting inner dim keeps the param count the same. Shazeer: “we attribute their success, as all else, to divine benevolence.”
- Mixture of Experts (MoE) (Shazeer 2017): learn separate MLPs per block; route each token to active experts. Increases total params by , compute by only . Almost every frontier LLM today (GPT-4o, Claude, Gemini) is believed to be MoE with >1T params. Intuition: most parameters are “dormant” for any given token. Each token only pays for the handful of experts relevant to it, so total capacity scales without paying FLOPs for every parameter
Implementation Details
The part about how training is fed got me choked up, from reading Annotated transformer (reading it is really really helpful though).
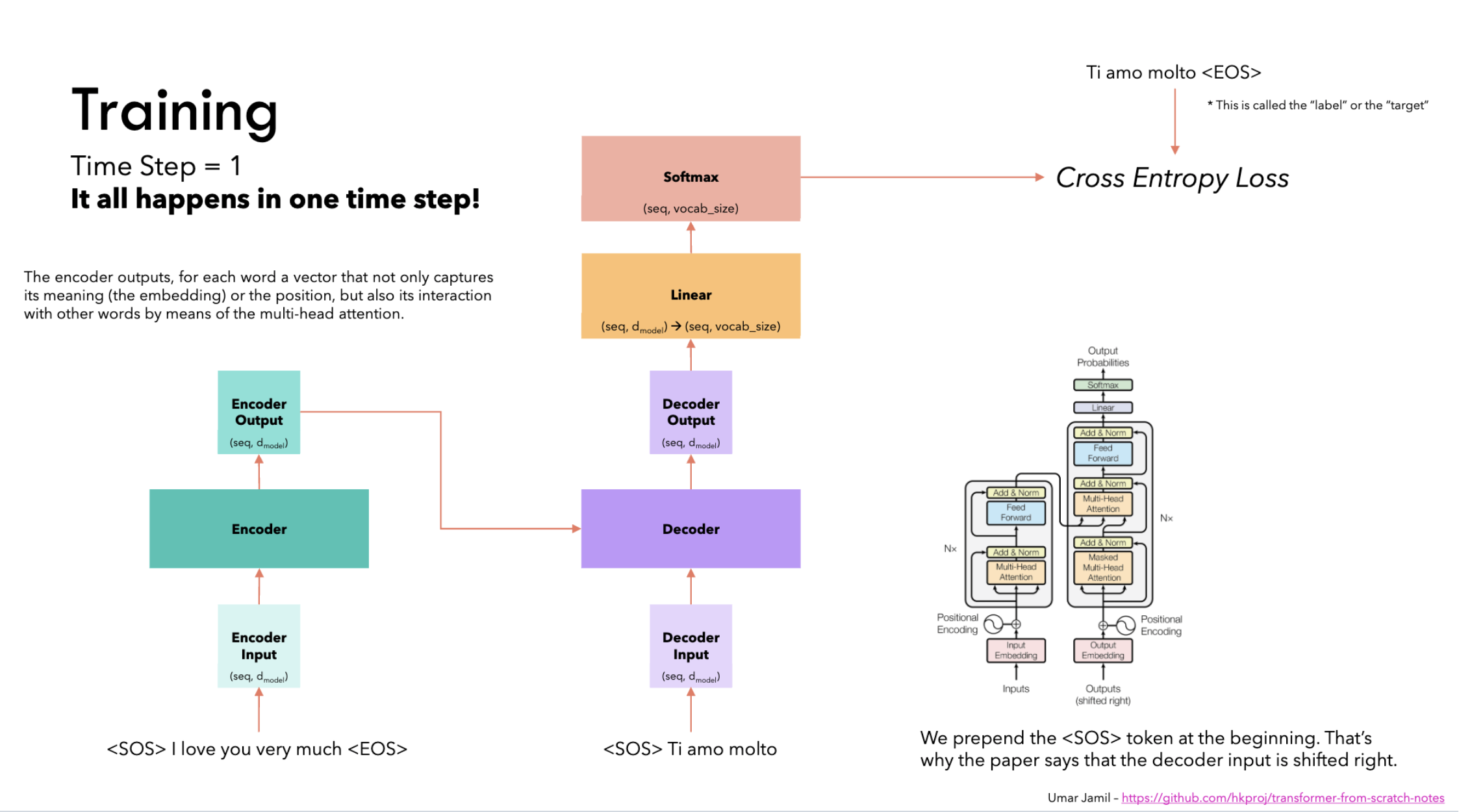
Gold target:
<bos> I like eating mushrooms <eos>
When we build inputs/labels:
- labels (trg_y) =
I like eating mushrooms <eos>
So the very first training example is:
- Input to decoder at position 0:
<bos> - Label at position 0:
I
That means: the model is explicitly trained to predict the first word (“I”) given only <bos> and the encoder context.