Automatic Mixed Precision (AMP)
Mixed precision trains (or runs inference) with some tensors in FP16 or BF16 while keeping a master copy of weights in FP32 for numerical stability.
Why not just use all in FP16?
Gradients in FP16 often underflow to zero, and some reductions (softmax, loss, variance) lose too much precision. Keeping the master weights and loss scaling in FP32 avoids those failure modes while still letting the bulk of matmuls run in FP16.
How it works
- Weights stored FP32 (master copy)
- Matmul inputs / activations cast to FP16 before the op
- Matmul output accumulation in FP32, written back as FP16
- Loss scaling: multiply loss by a large constant before backward, unscale gradients before
optimizer.step(), prevents small gradients from underflowing- Ops kept in FP32: softmax, layer norm, loss computation
Why it’s so fast
- FP16 matmul runs on Tensor Cores at 2-4× the FP32 throughput
- Half the memory bandwidth per weight access
- Half the activation memory, enabling bigger batches
for epoch in range(0): # 0 epochs, this section is for illustration only
for input, target in zip(data, targets):
# Runs the forward pass under ``autocast``.
with torch.autocast(device_type=device, dtype=torch.float16):
output = net(input)
# output is float16 because linear layers ``autocast`` to float16.
assert output.dtype is torch.float16
loss = loss_fn(output, target)
# loss is float32 because ``mse_loss`` layers ``autocast`` to float32.
assert loss.dtype is torch.float32
# Exits ``autocast`` before backward().
# Backward passes under ``autocast`` are not recommended.
# Backward ops run in the same ``dtype`` ``autocast`` chose for corresponding forward ops.
loss.backward()
opt.step()
opt.zero_grad() # set_to_none=True here can modestly improve performance"# Backward passes under
autocastare not recommended." Why?
What operations gets autocasted to float32? See links below https://docs.pytorch.org/docs/2.12/amp.html#cuda-ops-that-can-autocast-to-float16 https://docs.pytorch.org/docs/2.12/amp.html#cuda-ops-that-can-autocast-to-float32
- Some ops, like linear layers and convolutions, are much faster in
float16orbfloat16 - Other ops, like reductions, often require the dynamic range of
float32.
Mixed precision tries to match each op to its appropriate datatype, which can reduce your network’s runtime and memory footprint.
But how does it actually work, under the hood?
https://pytorch.org/blog/what-every-user-should-know-about-mixed-precision-training-in-pytorch/
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html
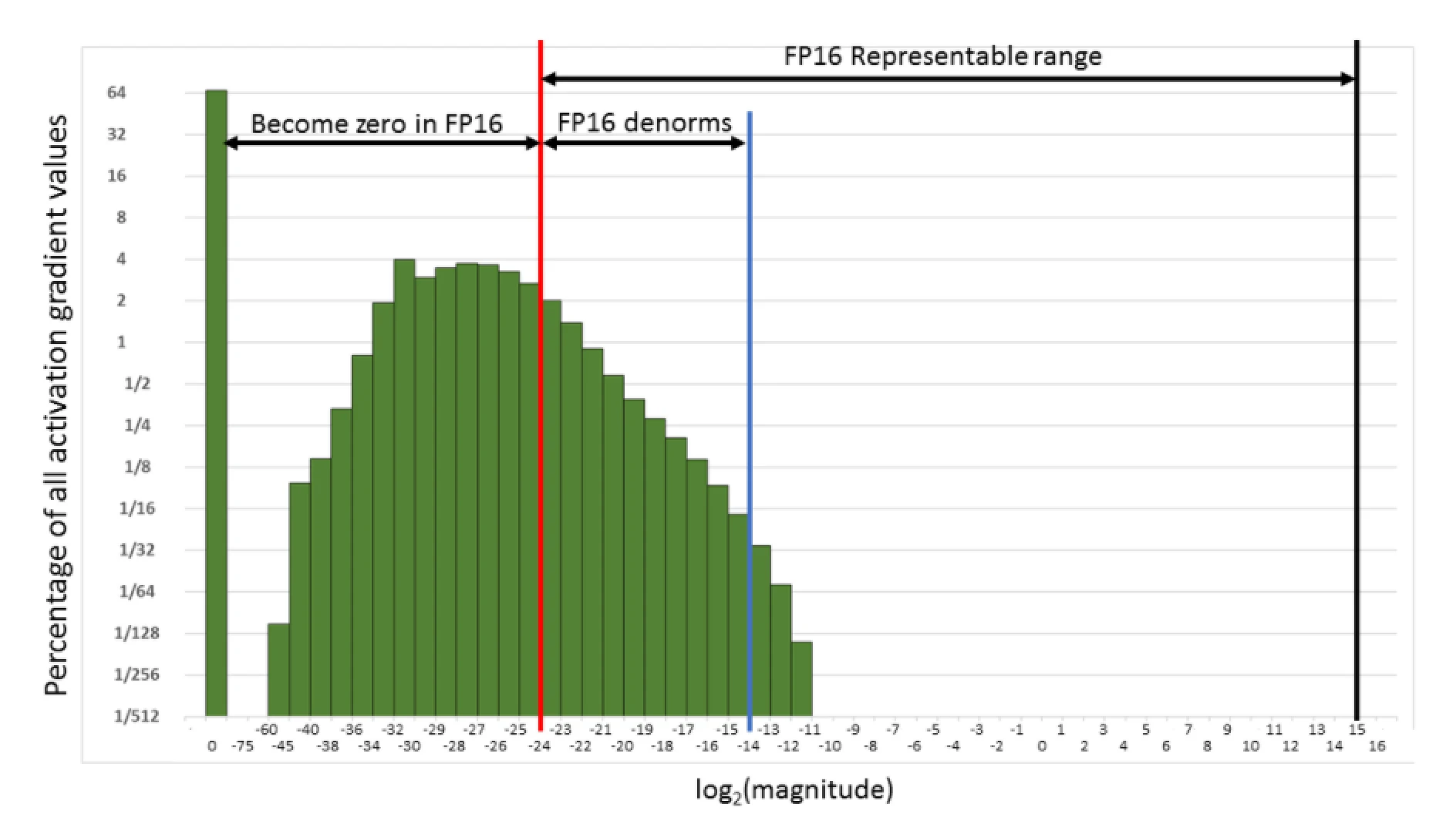
- “Consider the histogram of activation gradient values (shown with linear and log y-scales above), collected across all layers during FP32 training of the Multibox SSD detector network (VGG-D backbone). When converted to FP16, 31% of these values become zeros, leaving only 5.3% as nonzeros which for this network lead to divergence during training.”