Quantization
Quantization is the process of constraining an input from a continuous or otherwise large set of values (such as the real numbers) to a discrete set (such as the integers).
https://newsletter.maartengrootendorst.com/p/a-visual-guide-to-quantization
- referenced from https://github.com/HandsOnLLM/Hands-On-Large-Language-Models
Using Fp8 (8-bit matrix multiplication)
- LLM.int8() paper → https://arxiv.org/pdf/2208.07339
This guy at Etched hackathon told me about how he sped up multiplication by simply doing a bit shift (basically a variation of int8). It’s an integer, and that just does bit shift.
This blog (found from Clive Chan tweet)
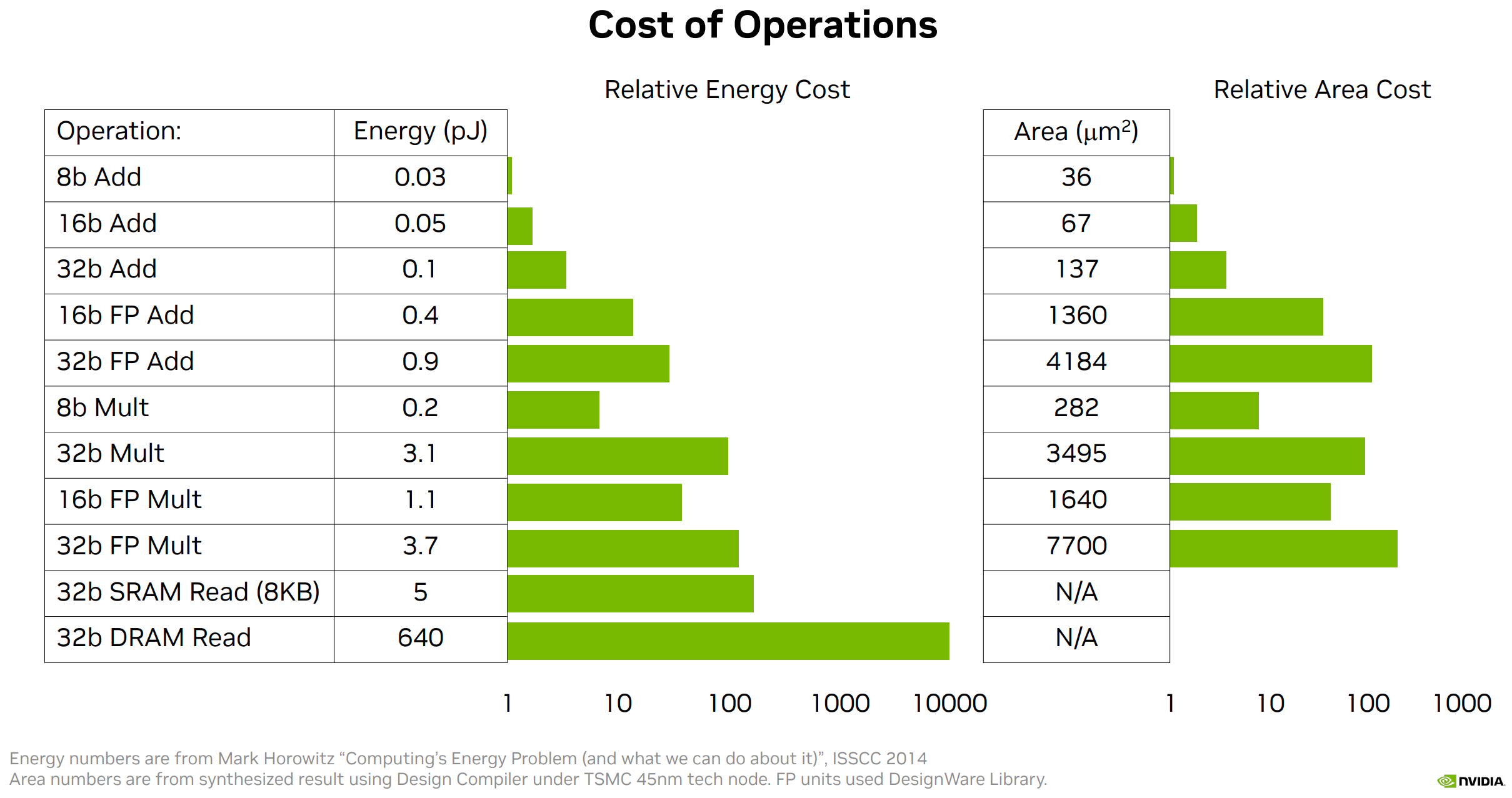
- It’s about the joules per FLOP that matters, silicon efficiency matters a LOT
Saw these terms from reddit thread reading about vLLM: https://www.reddit.com/r/LocalLLaMA/comments/1eamiay/vllm_vs_llamacpp/
- GPTQ (Generalized Post-Training Quantization)
- AWQ (Activation-aware Weight Quantization)
Bitsandbytes 8-bit LLM.int8() https://huggingface.co/blog/hf-bitsandbytes-integration
4-bit https://huggingface.co/blog/4bit-transformers-bitsandbytes
Quantization for neural networks
At Ericsson, Adam Cooke told me about the project that he had been working on for over a year now on Bit Quantization.
The idea is to reduce from like 24 bit to 8-bit. Ericsson is working on a “DIY Tensorflow” library that works on EMCA. Adam shared with me some of the logic he was going through.
Dequantization