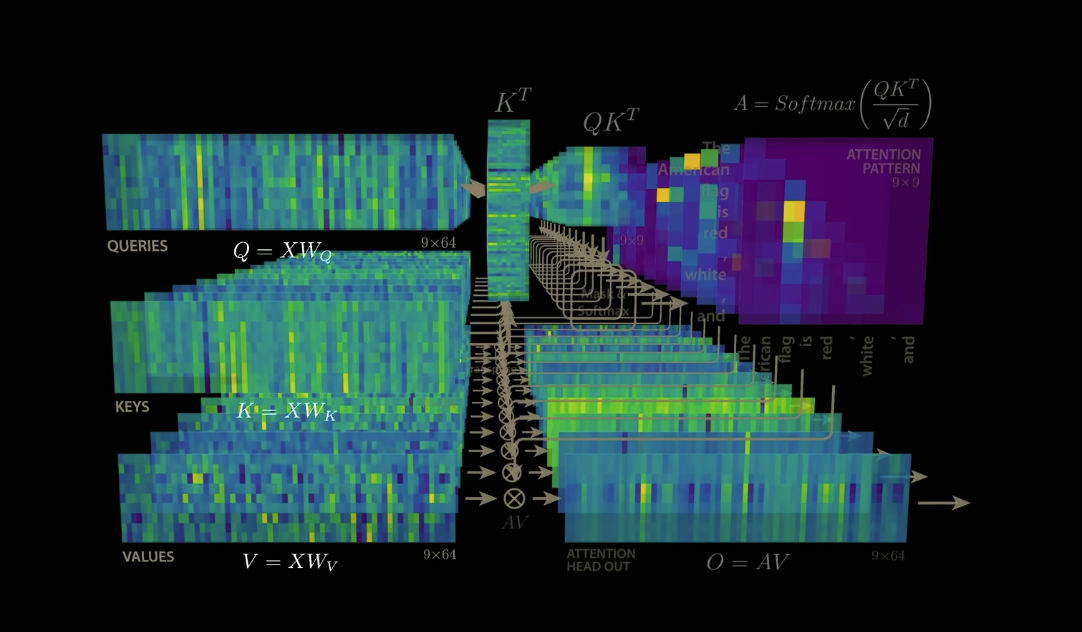
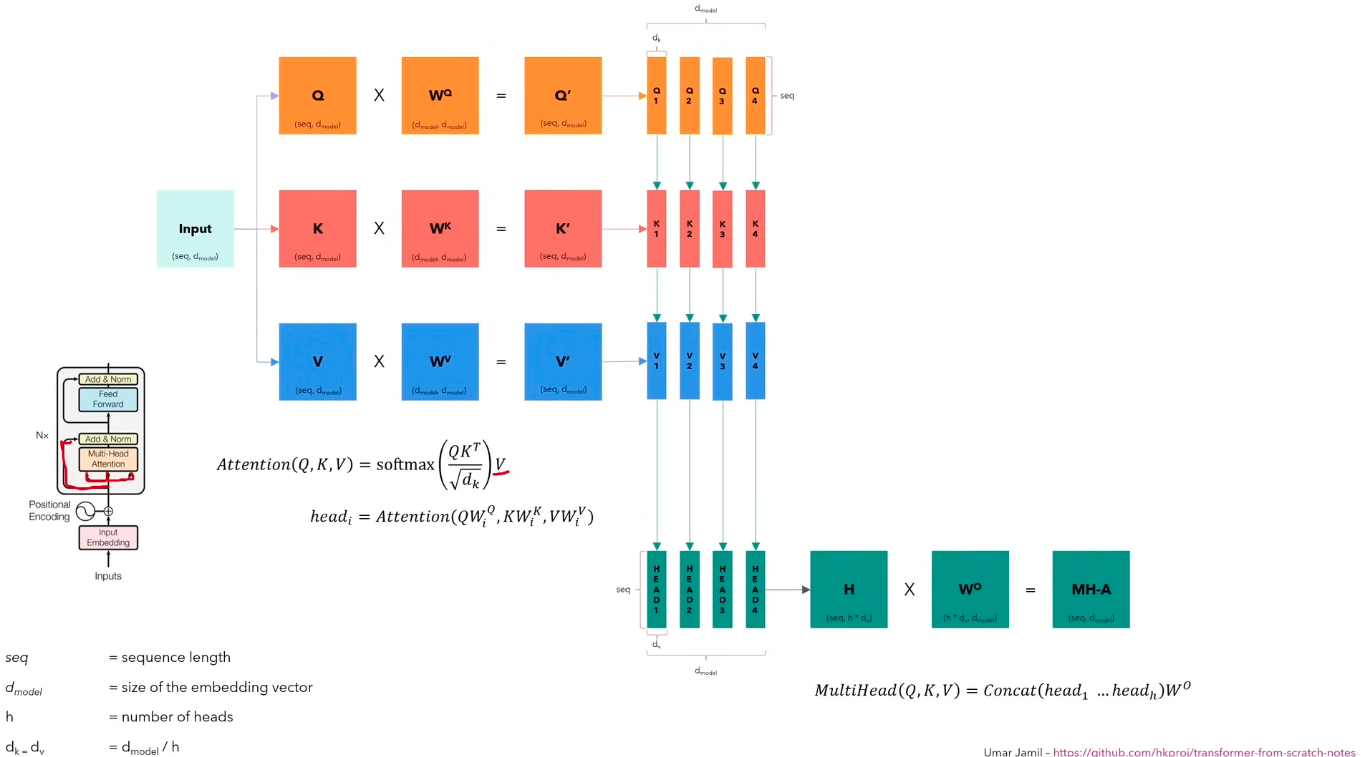
Multi-Head Attention
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
where
Where the projections are parameter matrices
In the original paper, they employ h = 8 parallel attention layers, or heads. For each of these we use .
Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality
I don't understand, don't the heads just end up doing the same things?
Intuitively, it could happen. But here’s why it usually doesn’t:
- Each head has its own , , matrices, all initialized differently.
- During training, if two heads start doing the same thing, they don’t both get rewarded equally — gradients nudge them to specialize and reduce redundancy.
- Why? Because doing the same thing doesn’t reduce the loss as effectively as learning different complementary patterns.
Each head learns to watch different aspects of the same word.
Does the head dimension need to be the same?
Usually people make sure that
n_embed = n_heads * head_dim. But this doesn’t have to be. Your weight matrix for Q,K,V just projects from n_embed to head_dim.