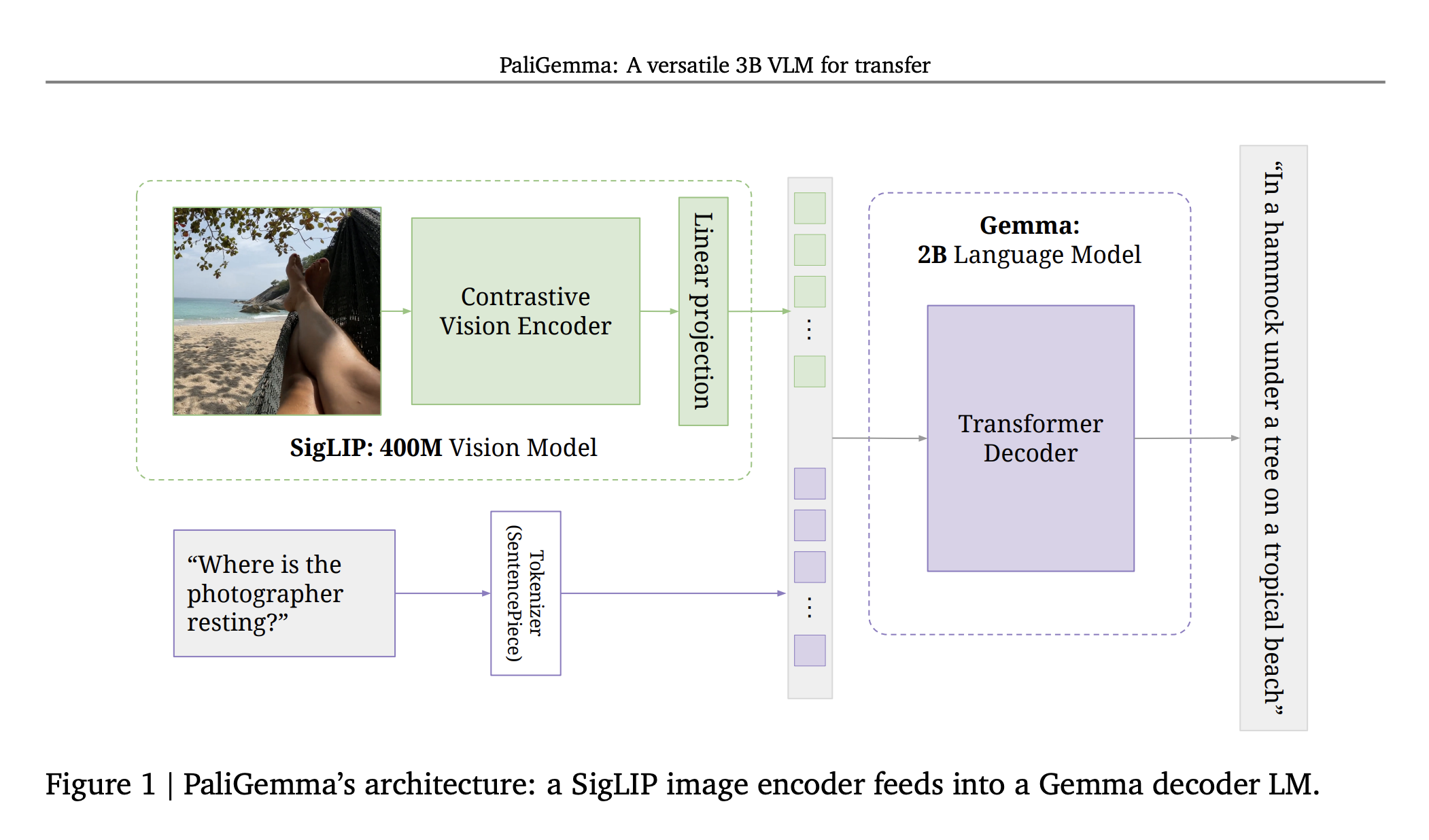
VLM, Gemma PaliGemma By GoogleDeepMind Resources https://arxiv.org/pdf/2407.07726 pi0 uses this model I don’t understand what this contrastive vision encoder refers to? It’s just SigLIP The images get mapped into the same embedding space as the text tokens. Also see pi0 for how I explain this