π0: A Vision-Language-Action Flow Model for General Robot Control
Successor to Octo model.
Links:
- https://www.physicalintelligence.company/blog/pi0
- https://www.youtube.com/live/ELUMFpJCUS0?t=16866s kevin black motivating the architectural design (coming from Octo) starting at 04:41:06
- Me trying to explain how the architecture works: https://www.youtube.com/watch?v=NVS-7VJMA5c
Two main contributions:
- Applying VLM to VLA via flow matching
- Leverages large-scale internet pretraining from VLM
- Data recipe
” averaging over 10 trials per task”
- This is how many trials they do to get success rate
Model Architecture
It’s a MoE-style architecture composed of 2 experts:
- Expert 1 (VLM): PaliGemma (3 billion params) pre-trained from internet
- Expert 2(large transformer): Gemma action expert (300 million params) from scratch
- The Gemma expert is a dedicated transformer stack for actions
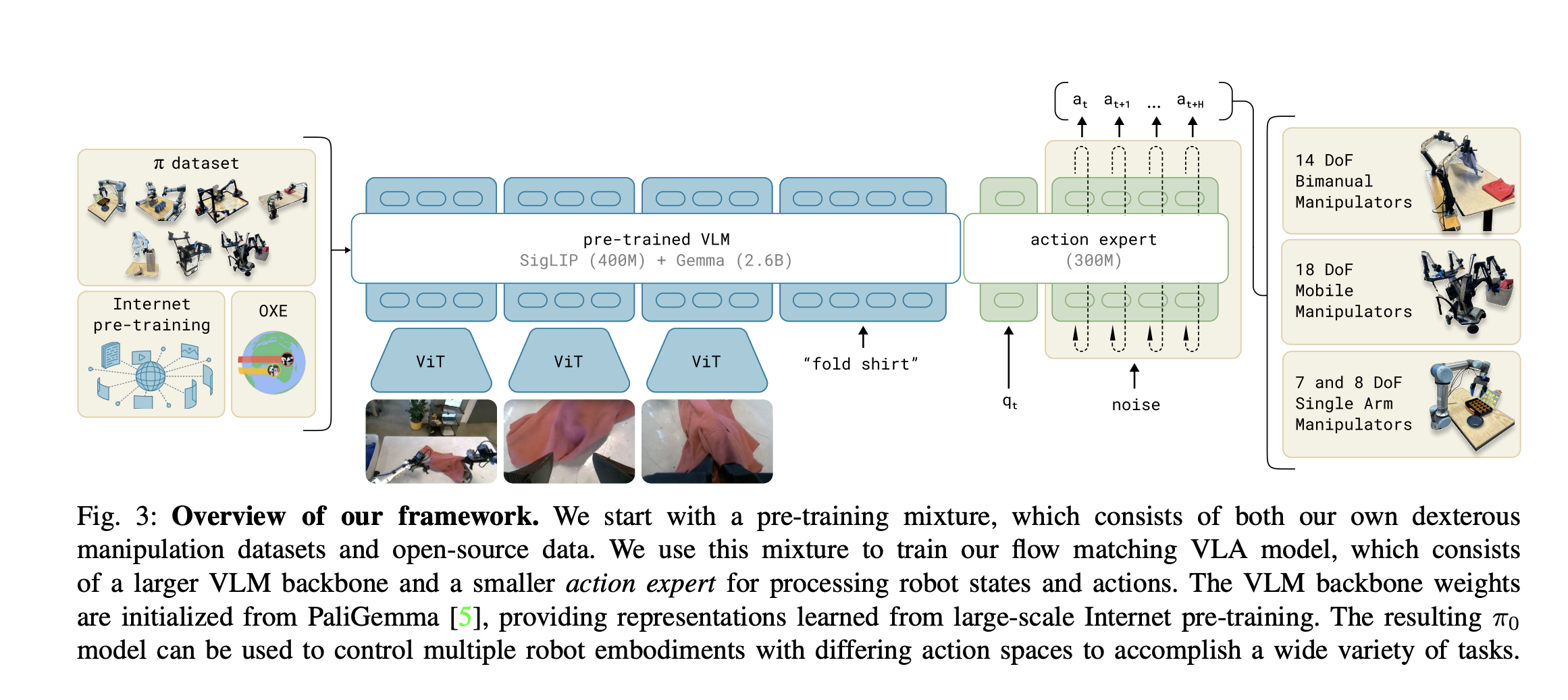
The two experts talk to each other via Blockwise causal attention.
- This is a really important detail that is not shown in the paper

- There are 18 transformer blocks (i.e. depth in the paper)
- Width = the model’s hidden size (a.k.a. embedding dim, model dim).
- For the VLM expert (PaliGemma backbone): width = 2048
- For the Action expert: width = 1024
- Note that the width doesn’t have to match between the two experts, just during attention, the head dim needs to be the same
- Both experts map into the same attention head space ( heads hidden dim = ).
- Concatenate tokens → do one global attention.
- Split results → project back into each expert’s private width (2048 vs 1024).
- Enables cross-attention between VLM and Action tokens, while keeping parameters separate.
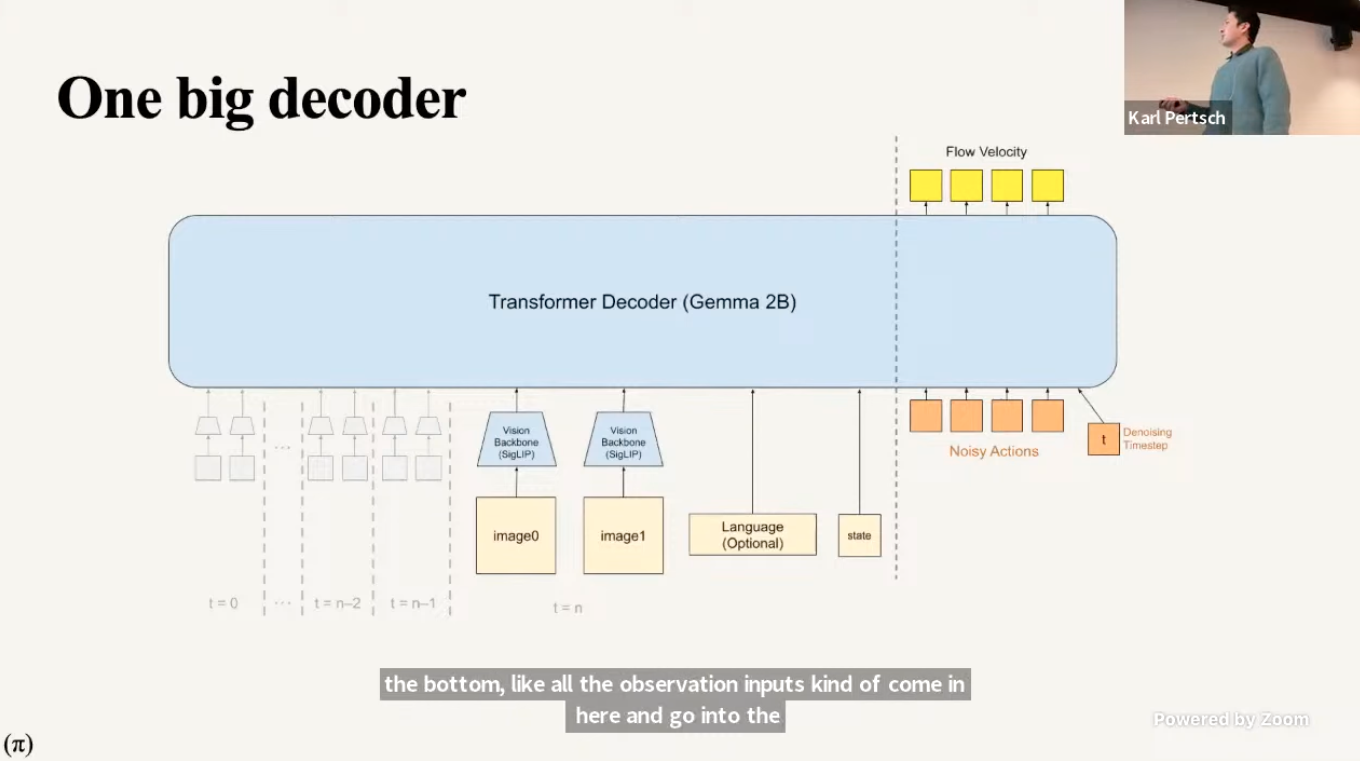
Why use separate expert as opposed to just introducing new tokens to the VLM?
That makes it a giant decoder, and is what Kevin black actually originally tried for the pi0 model. However, convergence is really slow, and distribution shift. it will make the model super confused ( explained at ~5:01:31 of the talk)
Idea: use a whole set of different weights for the action expert, which is trained from scratch.
Also another thing kevin pointed out: leveraging pre-training is super-duper important!!

Flow Matching
At training time, the Flow Matching loss to train the policy is given by
Where
- (Note: this should be ?)
Potential source of confusion
Notice that is always learning to predict , even though it is conditioned on . You might think really it should be learning , but that would be learning the distance vector - We are trying to learn the velocity field, which stays constant through (the first derivative).
- This multiplication by will be done at inference time to control “step size”

What's the point of
\tau?Without , where you just start from and directly predict , that’s essentially a denoising autoencoder view.
allows you to better capture multi-modal behavior, else you end up with mode-collapse, think about this scenario:
Background on flow matching
ChatGPT conversation: https://chatgpt.com/share/68c5b5fa-7db4-8002-9708-ef4e953533f9
The idea: we want to turn noise into a data sample (here, an action ). We can describe this transformation as continuous process over time , i.e. an ODE:
with initial condition and at the end, . Flow matching tries to learn this vector field .
To train such a model, we choose reference path between and and differentiate over it. The simplest path between and is a straight line (i.e. straight line interpolation):
- At , you are at pure noise, and at , you’re at the action
Taking the derivative with regards to , we see that:
- The derivative of a straight line is a constant slope, so we just need to learn this constant!
We learn to predict this gradient (a constant) so that at inference time, we learn this mapping for any arbitrary
At inference time, we start with random noise and integrate the learned vector field from to , and use forward Euler integration rule:
- where is the integration size ( in paper)
Why is 10 steps better than 1 step?
Because at the end of the day, we are trying to learn multi-modal distributions.
- ChatGPT answer: If you take 10 smaller steps, each step only needs to be locally correct. Integration keeps pulling you back onto the line. So error doesn’t explode; it averages out