Pattern Matching for Strings
Formally learned in CS240.
Pattern Matching Definition
Search for a string (pattern) in a large body of text
- – The text (or haystack) being searched within
- – The pattern (or needle) being searched for
- Strings over alphabet
- Return smallest such that
- This is the first occurrence of in
- If does not occur in , return
FAIL
Applications:
- Information Retrieval (text editors, search engines)
- Bioinformatics
- Data Mining
How to solve
The easiest way to solve this is brute forcing, by checking every possible guess. But worst case performance is .
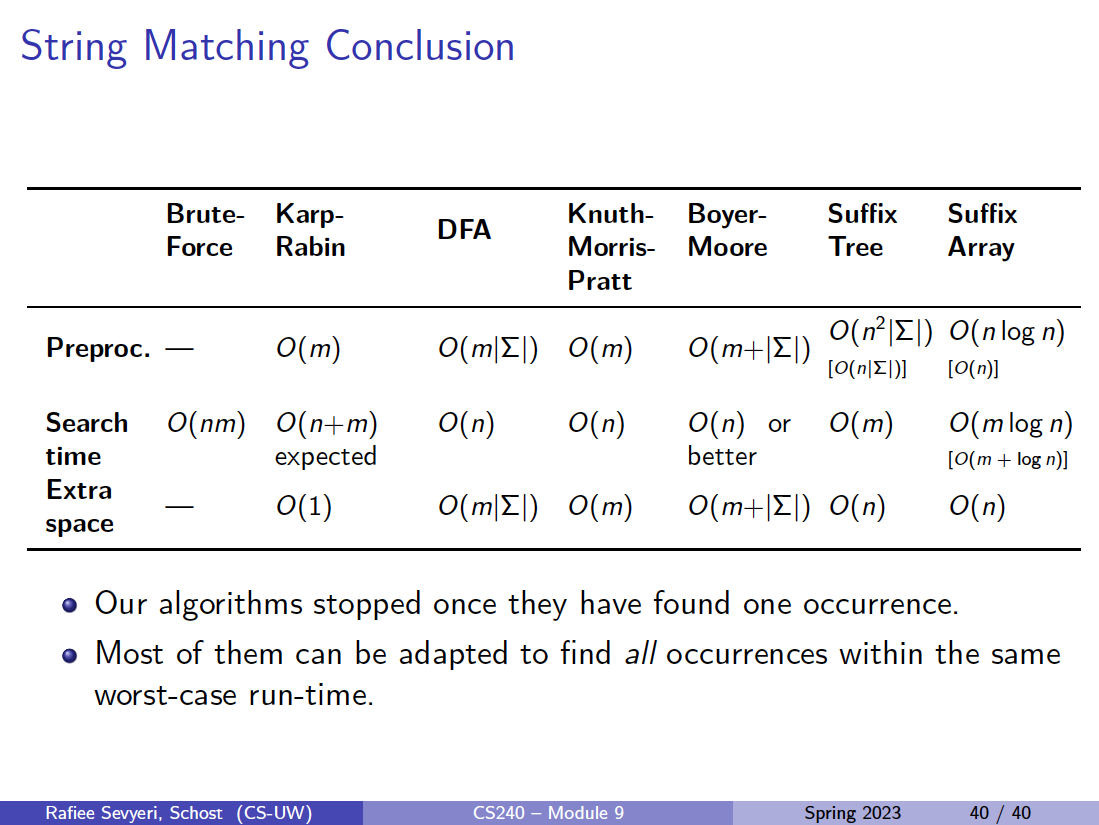
How to improve?
- Do extra preprocessing on the pattern
- Karp-Rabin Algorithm
- Boyer-Moore Algorithm
- Deterministic finite automata (DFA), KMP Algorithm
- We eliminate guesses based on completed matches and mismatches.
- Do extra preprocessing on the text
- Suffix Tree
- Suffix Array
- We create a data structure to find matches easily.