RT-H: Action Hierarchies Using Language
Really cool paper by Ted Xiao at Deepmind
Resources
“Belkhale and Sadigh”
- Mentioned from OpenVLA-OFT
- “Recent works by Belkhale and Sadigh [2] and Pertsch et al. [36] improve VLA efficiency through new action tokenization schemes,”
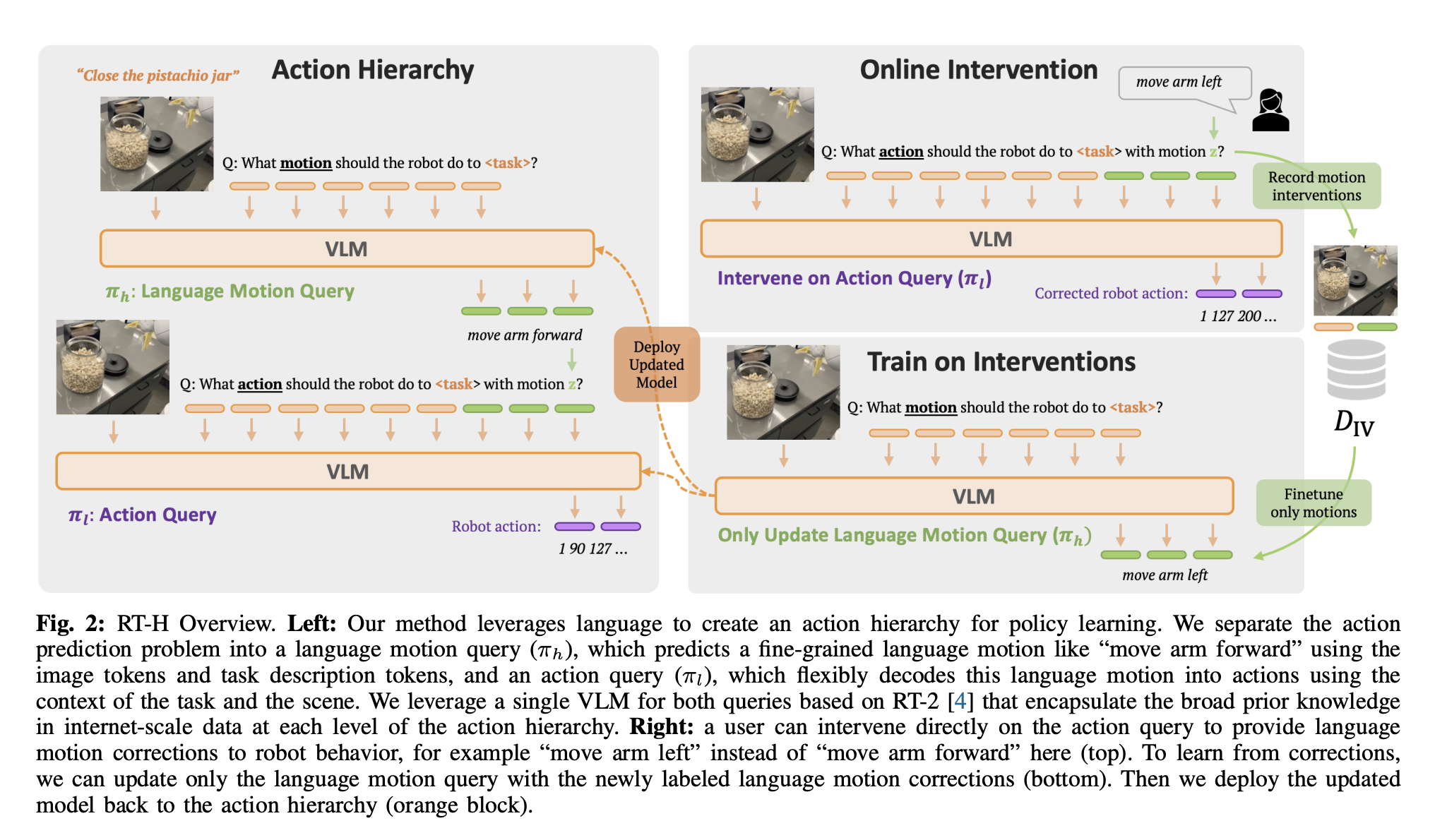
- This is the architecture
Doing this for all 9 action dimensions (3 dimensions for delta position, 3 dimensions for delta orientation, 2 dimensions for base movement, 1 dimension for gripper)
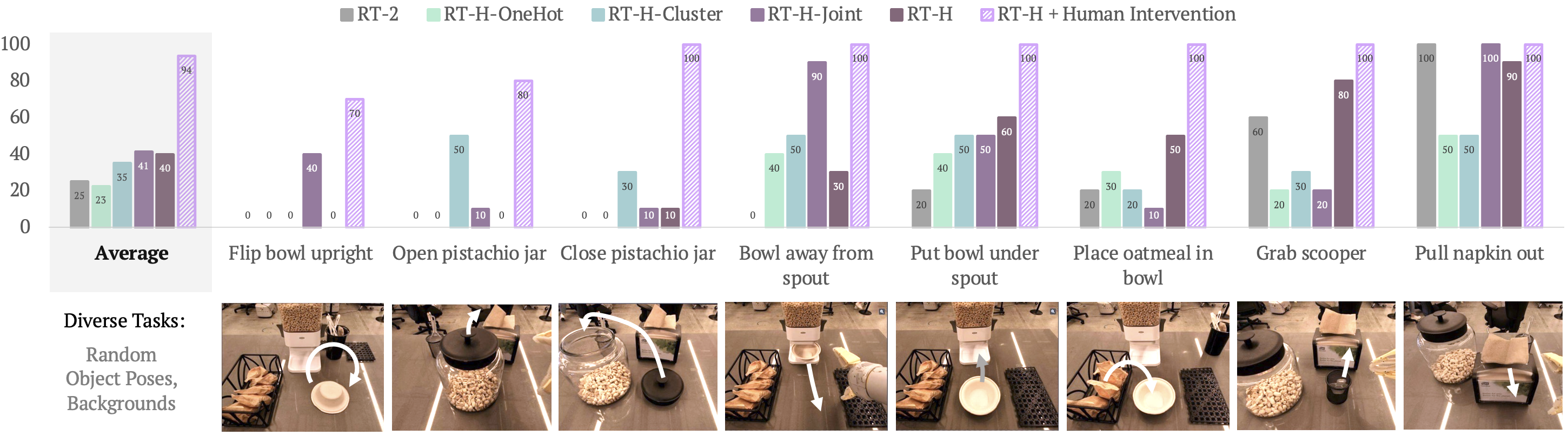
- Tasks: flip bowl upright
- Grab schooper