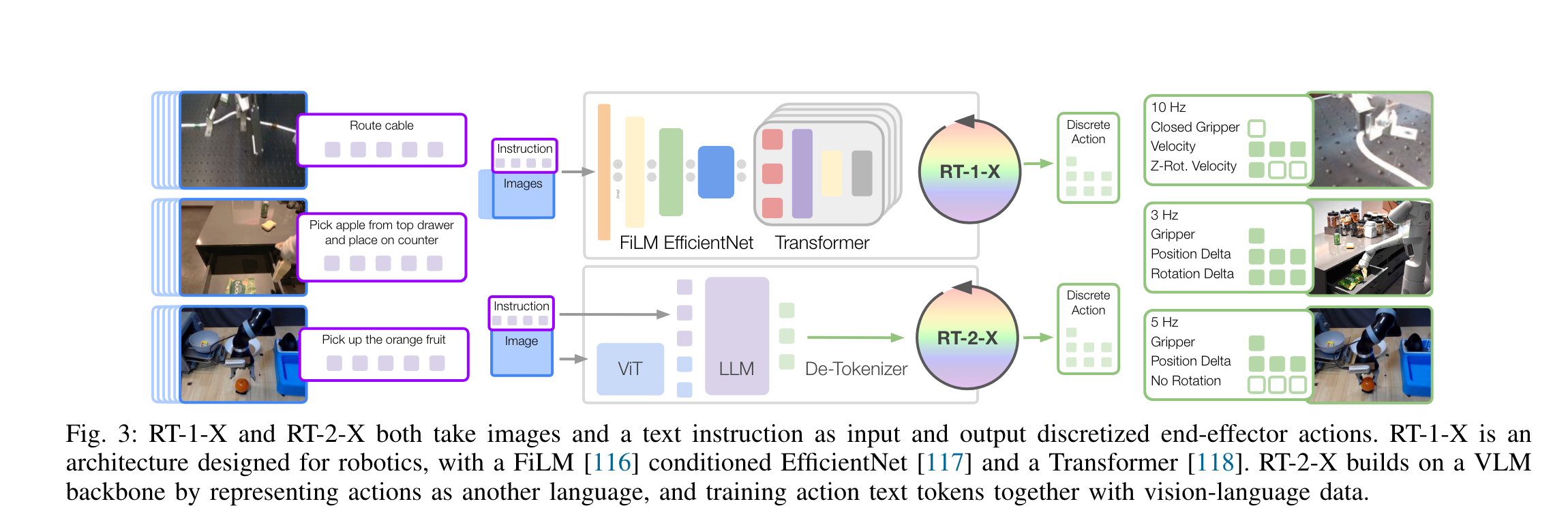
RT-1-X
My question is, how is it trained on some of the datasets where there are no instruction annotations??
- Then, the instruction is just empty
“It takes in a history of 15 images along with the natural language“.
This is essentially VLA.
My question is, how is it trained on some of the datasets where there are no instruction annotations??
“It takes in a history of 15 images along with the natural language“.
This is essentially VLA.