Tokenizer
Demos
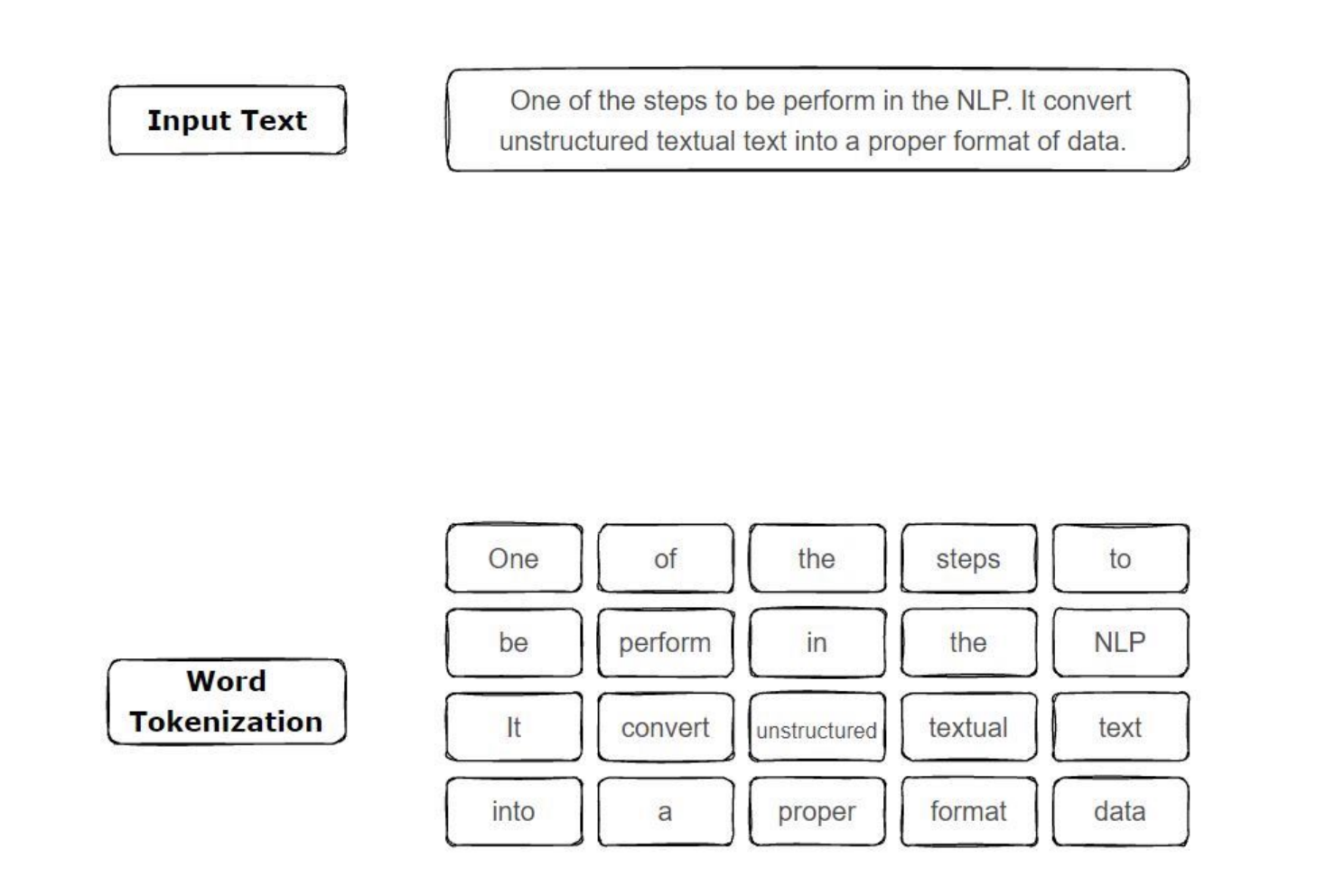
Why do we need tokenizers?
Like why can’t we just do a character based tokenizer?
- the problem is that the sequence becomes way too long for the model. the model has to learn spelling, morphology, and meaning all from very long chains
Are tokenizers hard coded or learned? Both exist:
Rule-Based (Hard-Coded) Tokenizers- Examples: Whitespace tokenizers, simple punctuation-based splitters
- Learned (Trained) Tokenizers:
- Byte Pair Encoding (used for GPT-4o) → tiktoken
- SentencePiece by Google, a library
By learned, it's not necessarily a neural network
It’s just doing it on large corpus of text, running some sort of mapreduce job, doing a frequency count of pairs, and then merging those pairs to introduce a new token.

https://watml.github.io/slides/CS480680_lecture11.pdf
Special tokens
[CLS]- Prepended to the beginning of the sequence in BERT-style models.[SEP]- Marks the end of a sentence/segment, or separates two segments.[MASK]- For masked language modeling[PAD- to pad so that sequences in a batch are the same length