Embedding
An embedding is a mapping from Tokens to vectors.
- An embedding refers to the vector representation of a single token (word, subword, or other unit)
- An embedding matrix is a collection of embeddings for the entire vocabulary
This is in the first pass, before we can apply attention.
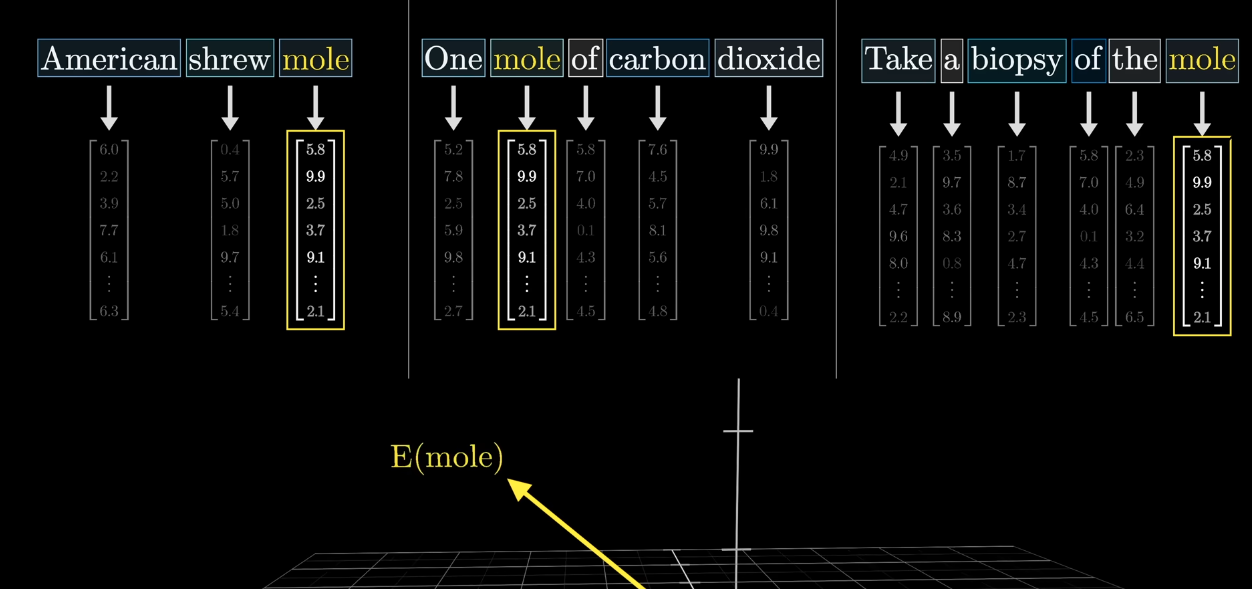
We map a token to its embedding by looking up the embedding matrix.
Ex: The word “cat” can be represented by an embedding [0.25, -0.17, 0.8, 0.33, ...]
Is the embedding a higher level or lower level representation of the token?
You can think of embeddings as just a learned mapping from a one-hot vector (huge, sparse, vocab-sized) to a dense vector (with a dimension like 768 or 12k).
Thus, we go from very high-dimensionality (dimension = vocab size) to lower dimensionality (dimension = embedding size).
The embedding visualized:
The vector representation depends on the context in which the token appears if the model uses contextual embeddings (like BERT, GPT).
After the process of tokenization, say a word "model" is tokenized, will it always be the same vector?
Yes, initially it is taken from the lookup table. After going through attention and MLP layers, the embedding will change.
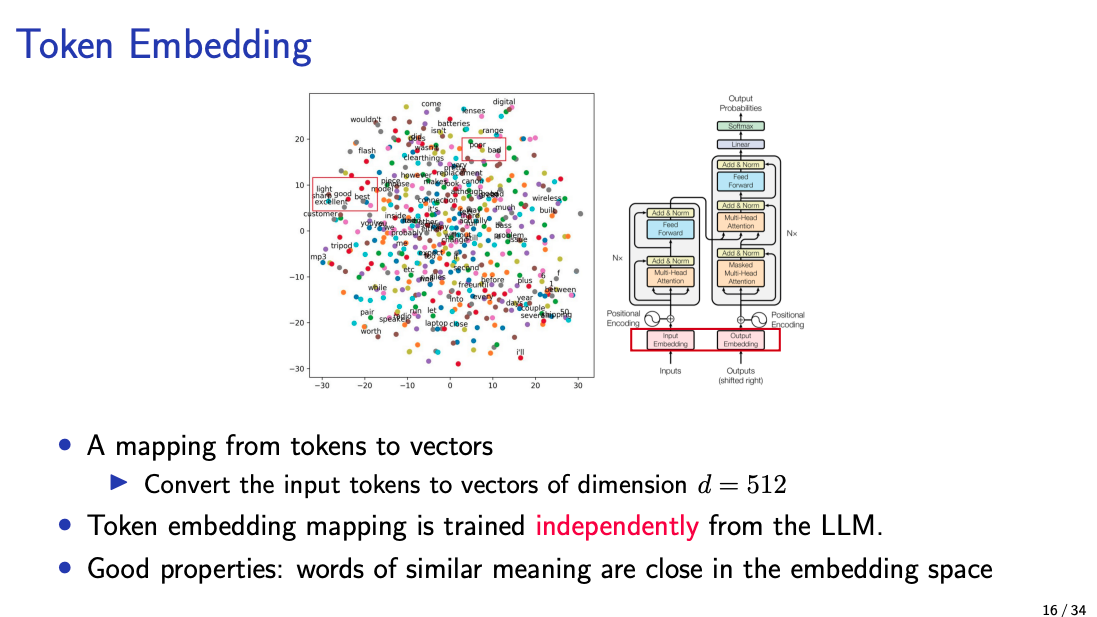
- “Token embedding mapping” here refers to how Tokens are selected