An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
original image: 224x224x3 patch size: 16x16x3 total number of patches: 14x14 = 196
Each flattened patch is a vector of length 768.
Why is the linear projection layer needed? just pass the raw flattened image patch as the embedding?
This lets the model reweight and mix the 768 raw pixel values into a better representation (e.g. combining color channels, edges, local contrasts).
Like if you think about how the original Transformer is implemented, the embeddings in the embedding table can all change for a given token. We want the same here, which is why letting the model learn an Affine Transformation () is useful.
In the end, you end up with this that gets fed into the transformer encoder
[CLS], patch1, patch2, [MASK], patch4, [MASK], ...
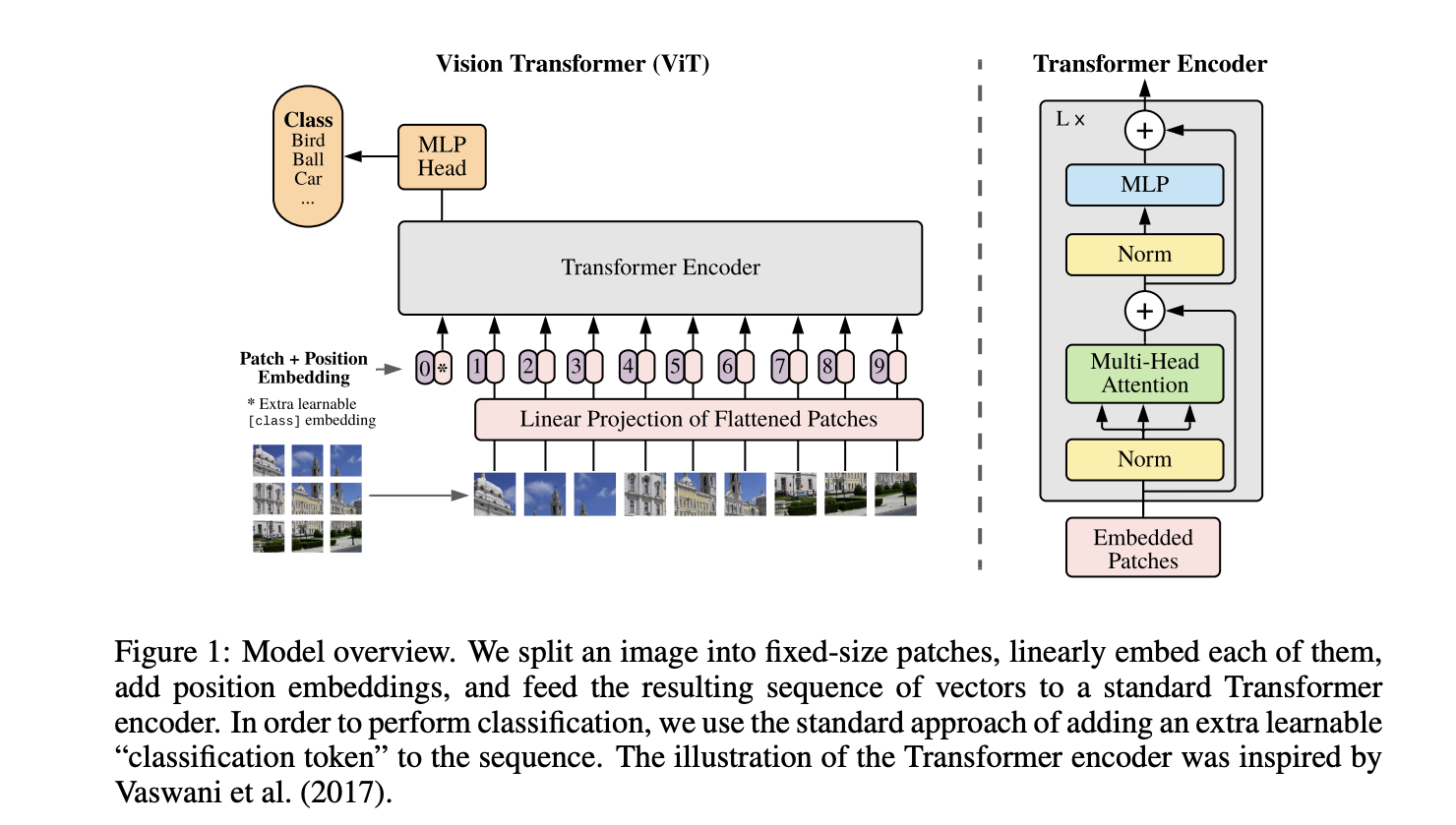
Each patch is like a token. The smaller the patch, the longer the sequence length required
![]()