Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success (OpenVLA-OFT)
Paper that introduces finetuning for OpenVLA.
Links
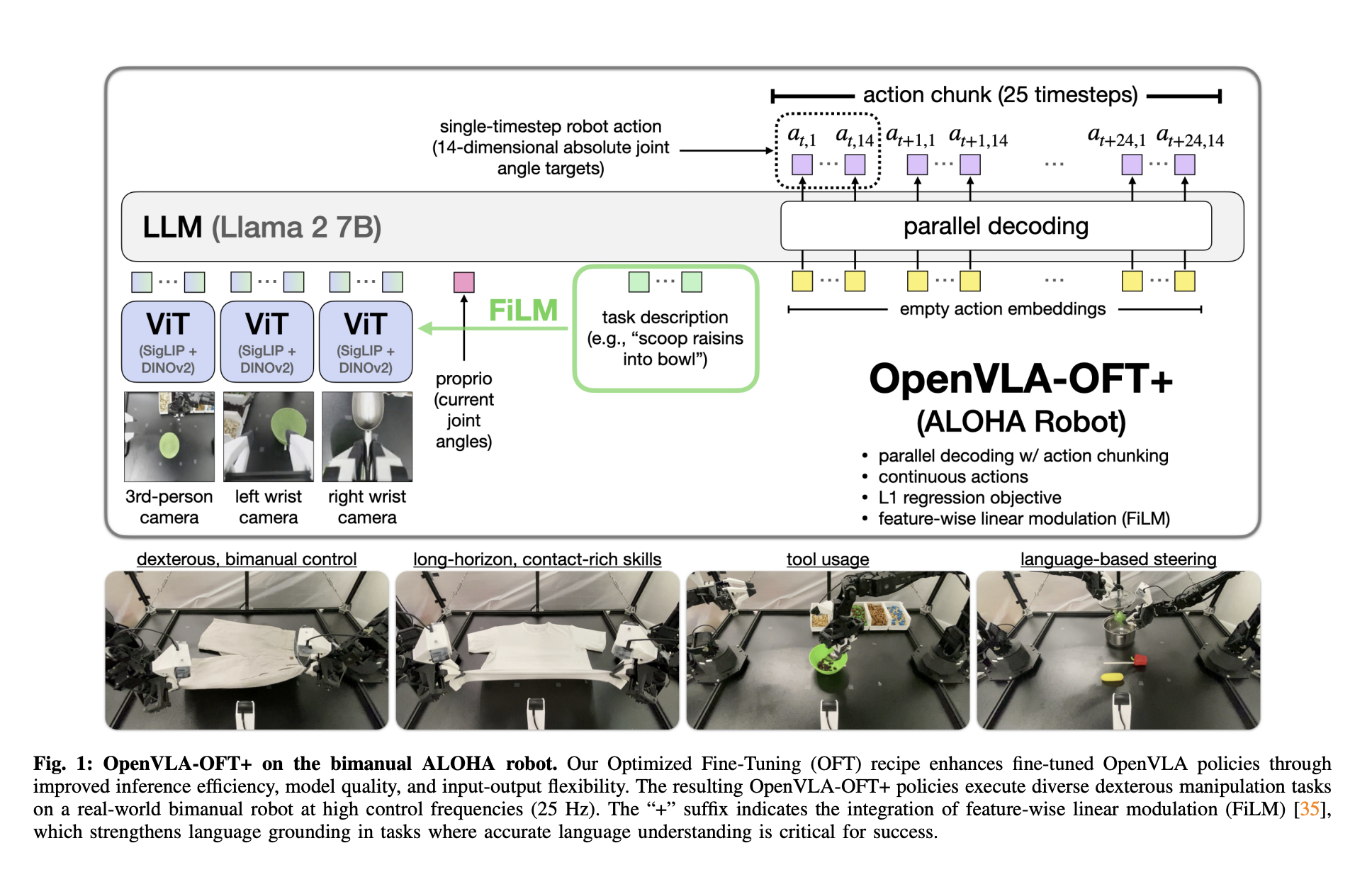
Architecture
Two main contributions:
- Add parallel decoding
- Film for better adherence to instructions
Parallel decoding seems like an interesting way to increase inference speed.
Has some really really good visualizations of different tasks and how they fail
