OpenVLA
Takeaways
There’s no concept of an action head. They use a out-of-the-box VLM (Prismatic VLM, which combines DINOv2 and SigLIP), and introduce new tokens for actions (256 different tokens), and then train the VLM to predict those actions.
Compare that to pi0 and you’ll see something quite different.
Resources
- https://openvla.github.io/
- https://github.com/openvla/openvla/blob/main/prismatic/models/vlas/openvla.py
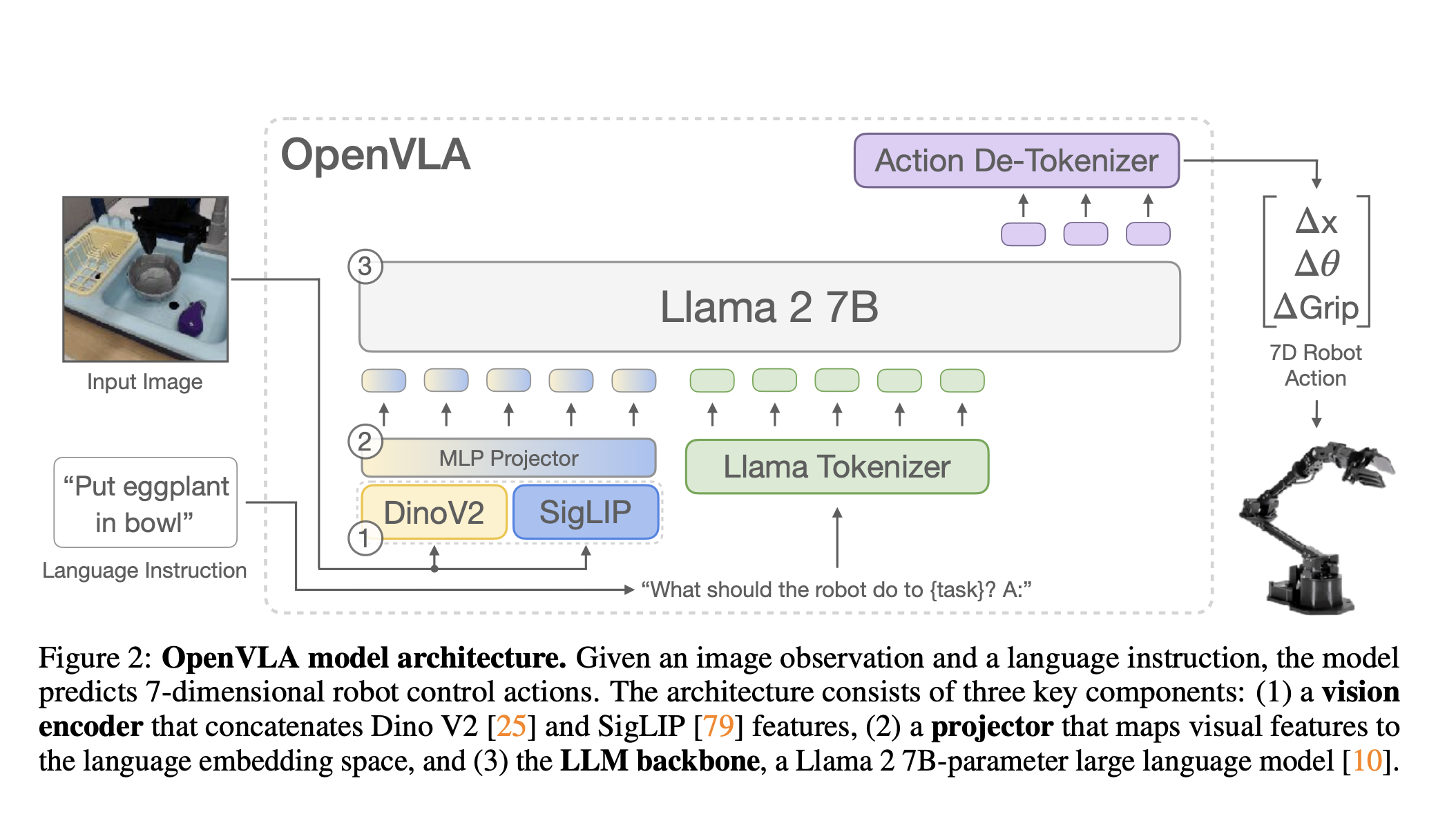
They “train OpenVLA by fine-tuning a pretrained Prismatic-7B VLM” (Prismatic VLM). Prismatic follows the same standard architecture described above.
Uses:
“Note that on many VLM benchmarks, increased resolution does improve performance [44, 86, 87], but we did not see this trend (yet) for VLAs”
They generate a 7D robot action:
- 3 degrees for position
- 3 for orientation
- 1 for gripper
No use of action chunking
Seems like it only predicts 1 action.
To enable the VLM’s language model backbone to predict robot actions, we represent the actions in the output space of the LLM by mapping continuous robot actions to discrete tokens used by the language model’s tokenizer.
- “we discretize each dimension of the robot actions separately into one of 256 bins”
How are the tokens implemented?
- The Llama tokenizer only reserves 100 “special tokens” for tokens newly introduced during fine-tuning, which is too few for the 256 tokens of our action discretization. Instead, we again opt for simplicity and follow Brohan et al. [7]’s approach by simply overwriting the 256 least used tokens in the Llama tokenizer’s vocabulary (which corresponds to the last 256 tokens) with our action tokens.