Gemini Robotics: Bringing AI into the Physical World
Builds on top of the Gemini A Family of Highly Capable Multimodal Models paper.
Takeaways
- Focus on robotics safety, which was really imprortant
We also introduce Gemini Robotics-ER, a version of Gemini 2.0 Flash that has enhanced embodied reasoning.
Gemini 2.0’s embodied reasoning capabilities make it possible to control a robot without it ever having been trained with any robot action data. It can perform all the necessary steps, perception, state estimation, spatial reasoning, planning and control, out of the box.
So how do we get it to work on a robot?
- Zero-shot robot control via code generation
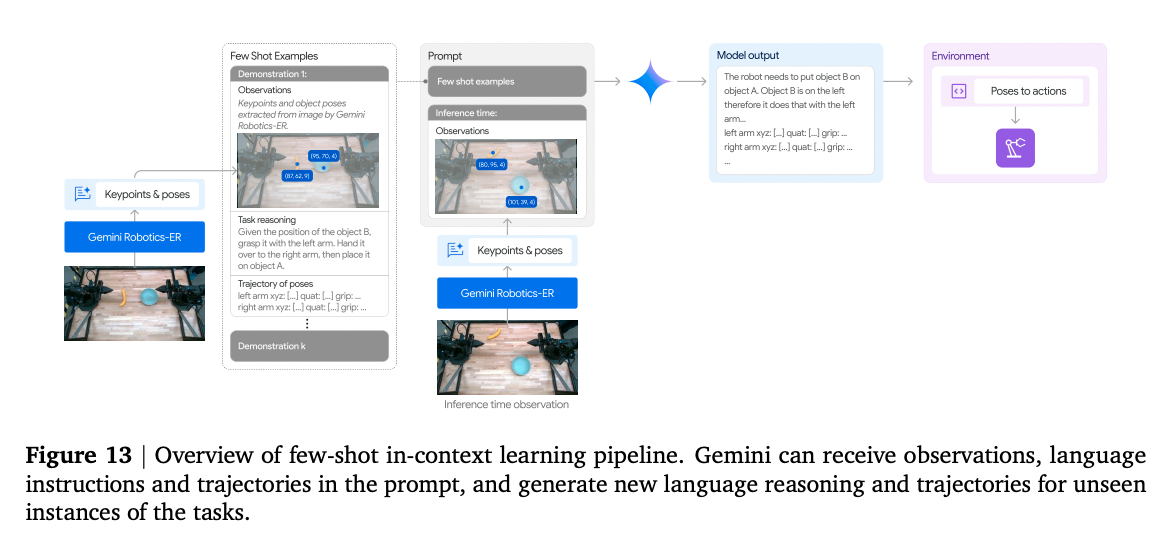
- Fewshot control via in-context learning (also denoted as “ICL” below)
Gemini Robotics-ER
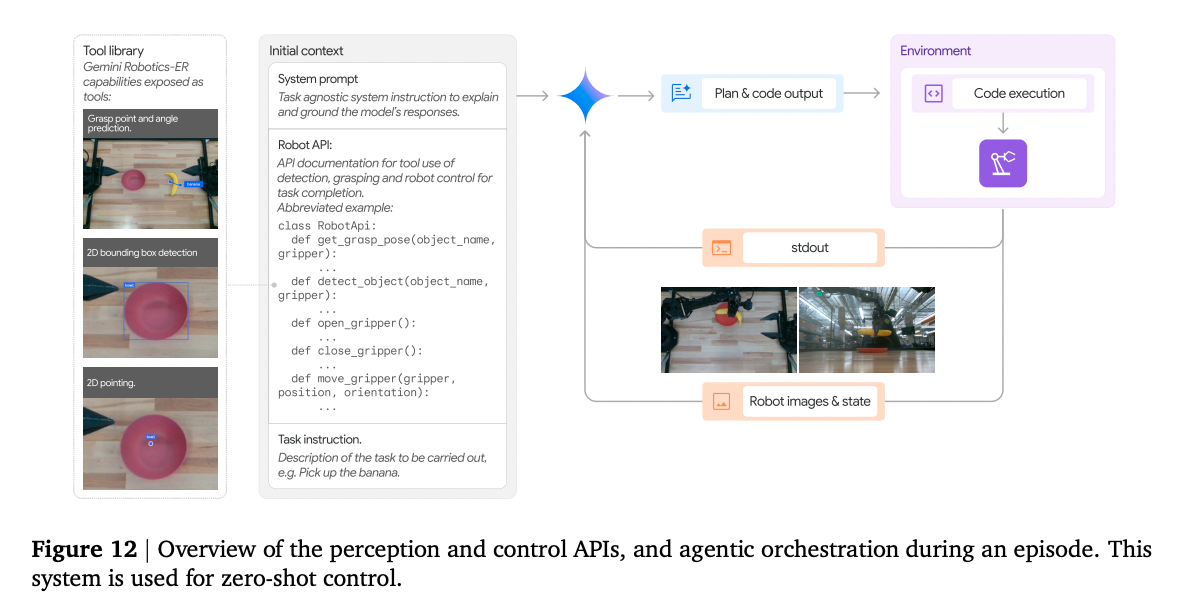
- Seems similar to MCP lol
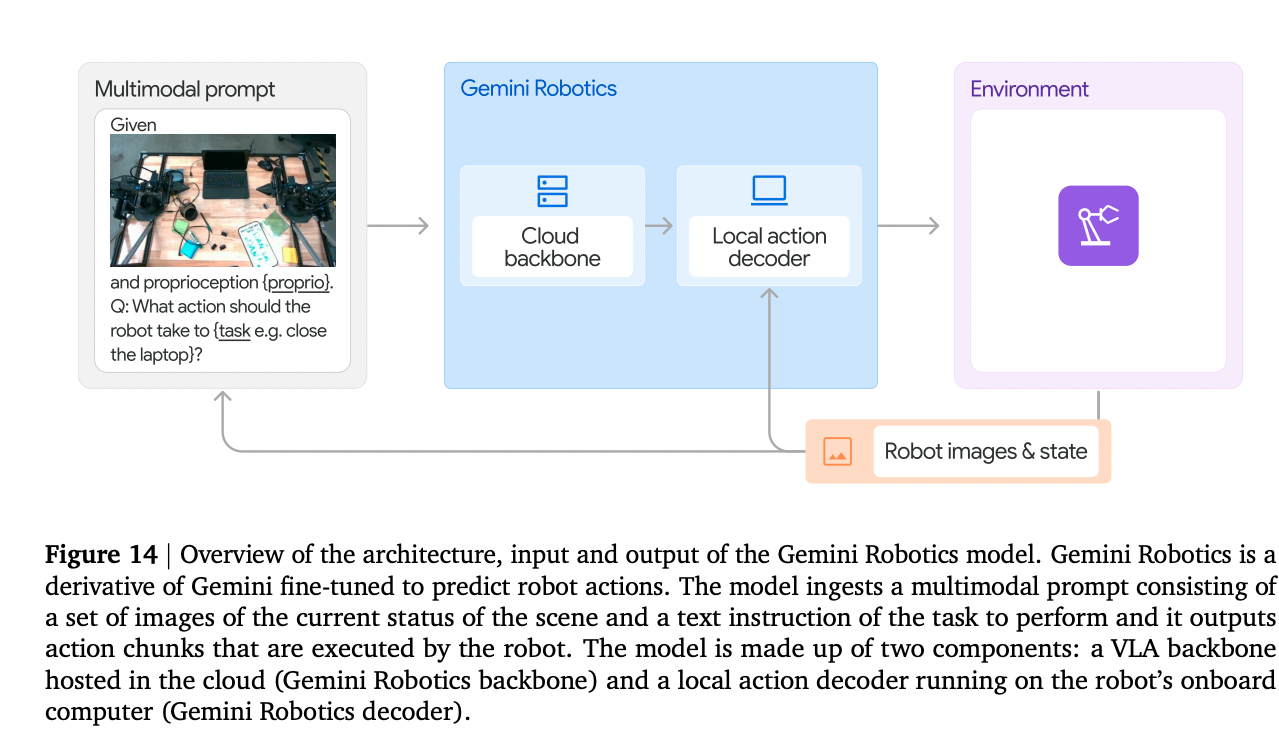
Gemini Robotics
However, as a VLM, there are inherent limitations for robot control, especially for more dexterous tasks, due to the intermediate steps needed to connect the model’s innate embodied reasoning capabilities to robotic actions. In the next section, we will introduce Gemini Robotics, an end-to-end Vision-Language-Action Model that enables more general-purpose and dexterous robot control.
“The Gemini Robotics backbone is formed by a distilled version of Gemini Robotics-ER and its query-to-response latency has been optimized from seconds to under 160ms.”
“The on-robot Gemini Robotics decoder compensates for the latency of the backbone“.
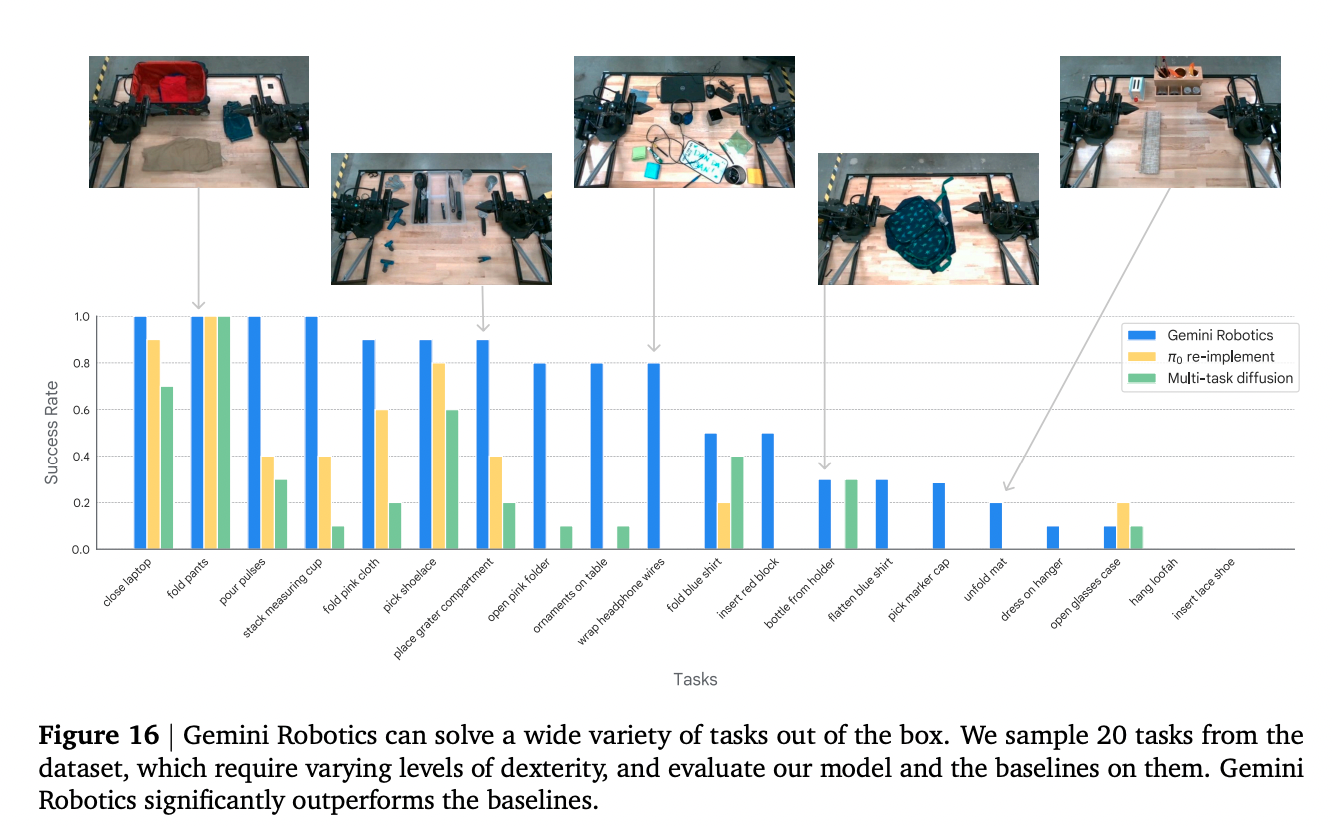
Better out of the box performance
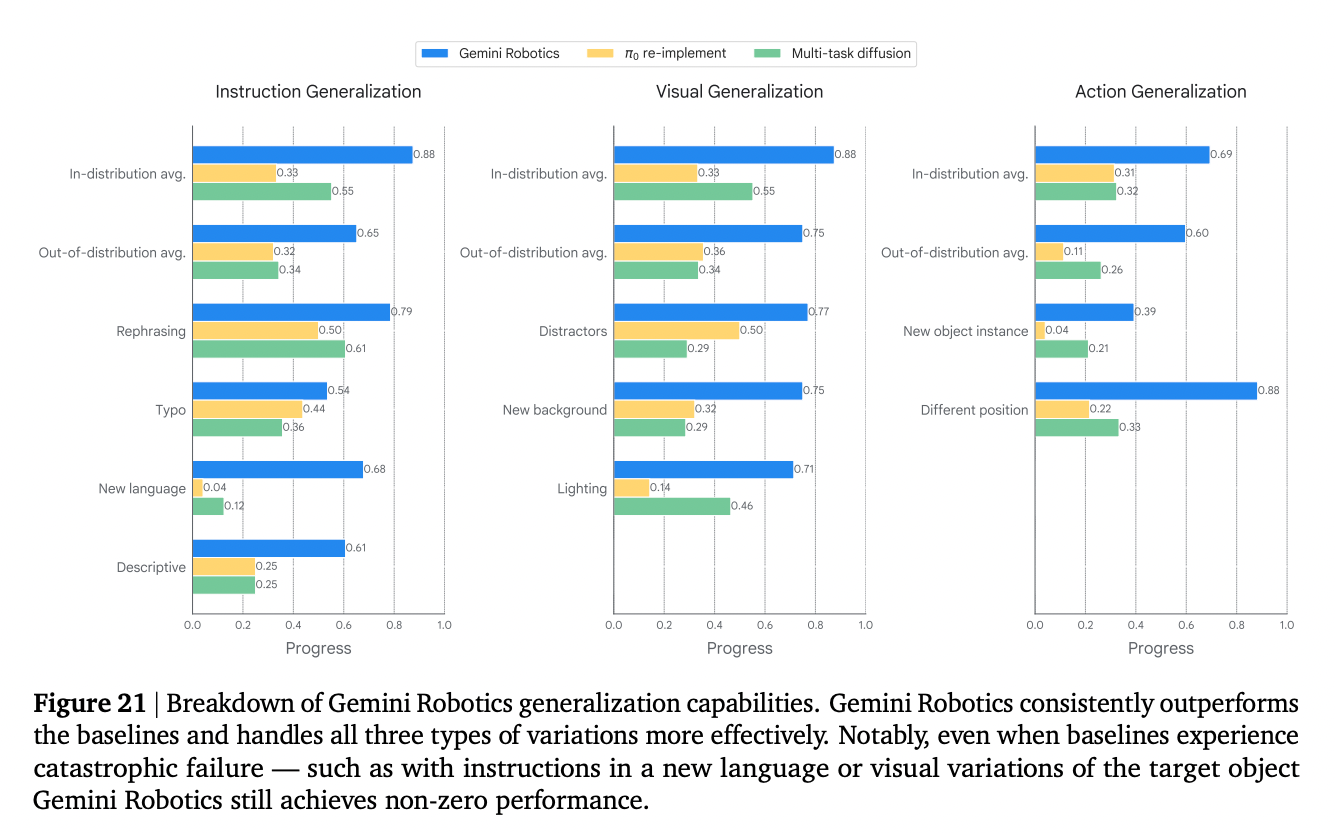
- Very interesting, related note on Robot Generalization