Horizon Reduction Makes RL Scalable
Pretty important paper that addresses some of the scaling limitations. They found that everything (including model architecture) doesn’t scale as well as reducing the horizon.

minimal set of techniques (e.g., flow behavioral cloning and SARSA) that address the horizon issue in a scalable manner (see Section 6.1 for further discussions).
One interesting experiment that they did is the combination lock, and i was talking to grok. We see the results, but we need to understand why it doesn’t work. It makes sense why -step return works better, because the reward signal can propagate back a lot faster to the earlier states.
- So we should just use monte-carlo
There’s a similar idea in sutton’s RL book, and they actually show how TD is way more sample efficient
“n! In practice, however, TD methods have usually been found to converge faster than constant MC methods on stochastic tasks”
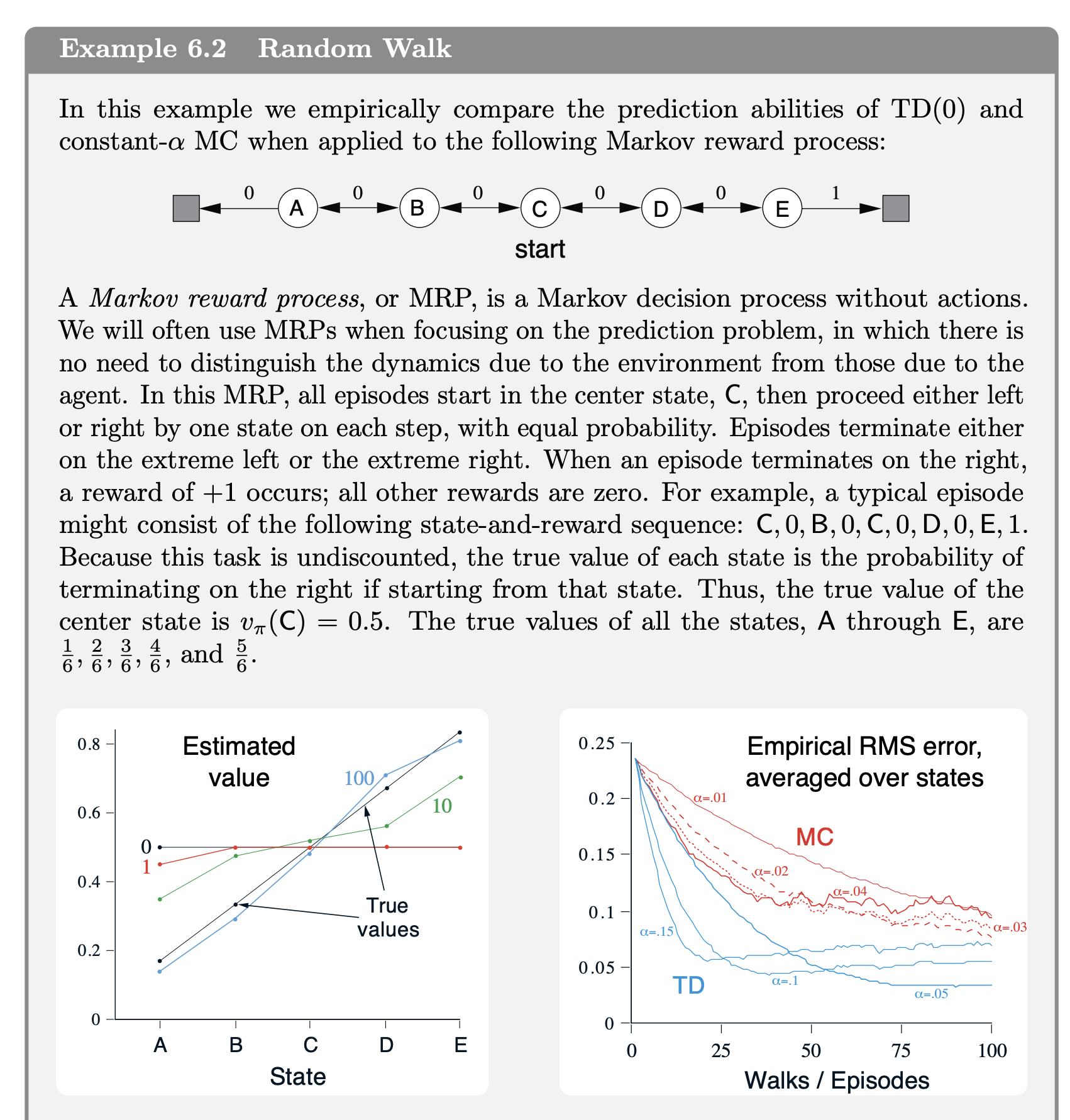
law of large numbers bail you out