Stabilizing Off-Policy Deep Reinforcement Learning from Pixels
Might have some good insights into why things don’t work. In the lines of Horizon Reduction Makes RL Scalable.
“Visual Deadly Triad”
“We propose Local SIgnal MiXing, or LIX, a new layer specifically designed to prevent catastrophic self-overfitting in convolutional reinforcement learning architecture”
This is a good plot to have
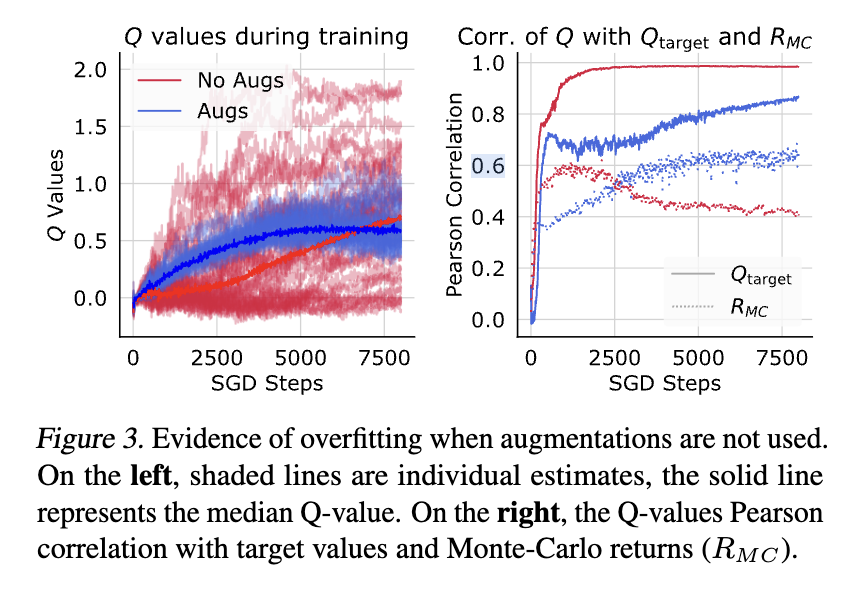
- You can clearly see the variance of the q-values is much lower when we apply image augmentation