Is Value Learning Really the Main Bottleneck in Offline RL?
-
For future algorithms research, we emphasize two important open questions in offline RL:
- (1) What is the best way to extract a policy from the learned value function? Is there a better way than DDPG+BC?
- (2) How can we train a policy in a way that it generalizes well on test-time states?
-
Takeaway: Do not use weighted behavior cloning (AWR); always use behavior-constrained policy gradient (DDPG+BC). This enables better scaling of performance with more data and better use of the value function.
-
Takeaway: Test-time policy generalization is one of the most significant bottlenecks in offline RL. Use high-coverage datasets. Improve policy accuracy on test-time states with on-the-fly policy improvement techniques.
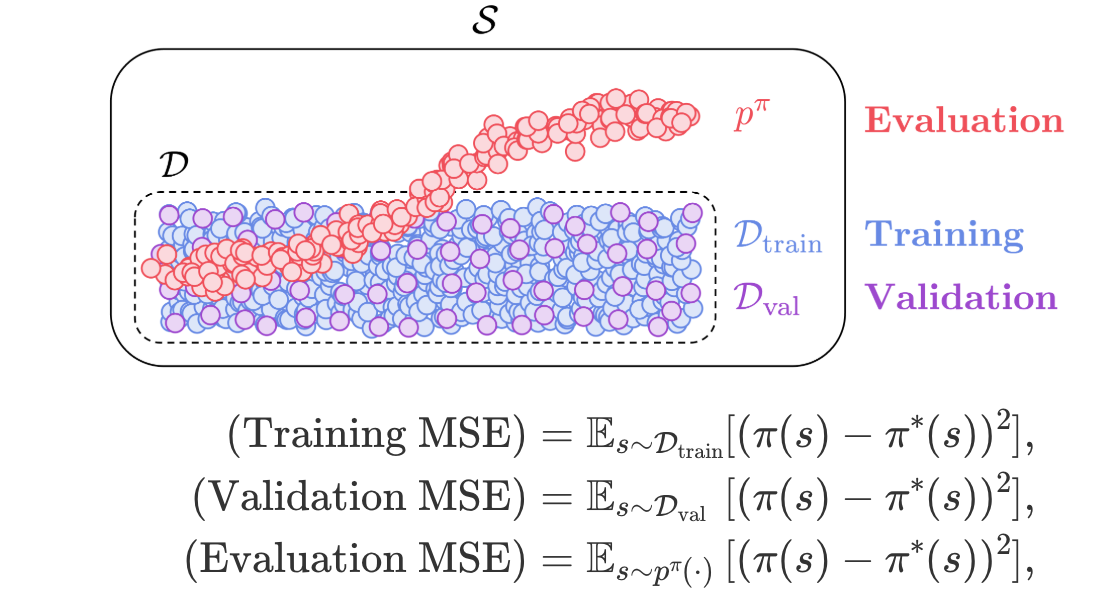
- I find this image to be quite helpful
Cited by Flow Q-Learning when it comes to value learning.
- First,we find that the choice of a policy extraction algorithm often has a larger impact on performance than value learning algorithms
- Second, we find that the performance of offline RL is often heavily bottlenecked by how well the policy generalizes to test-time states, rather than its performance on training states
They mention that DDPG + BC almost always does better.