Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)
Quite a seminal paper.
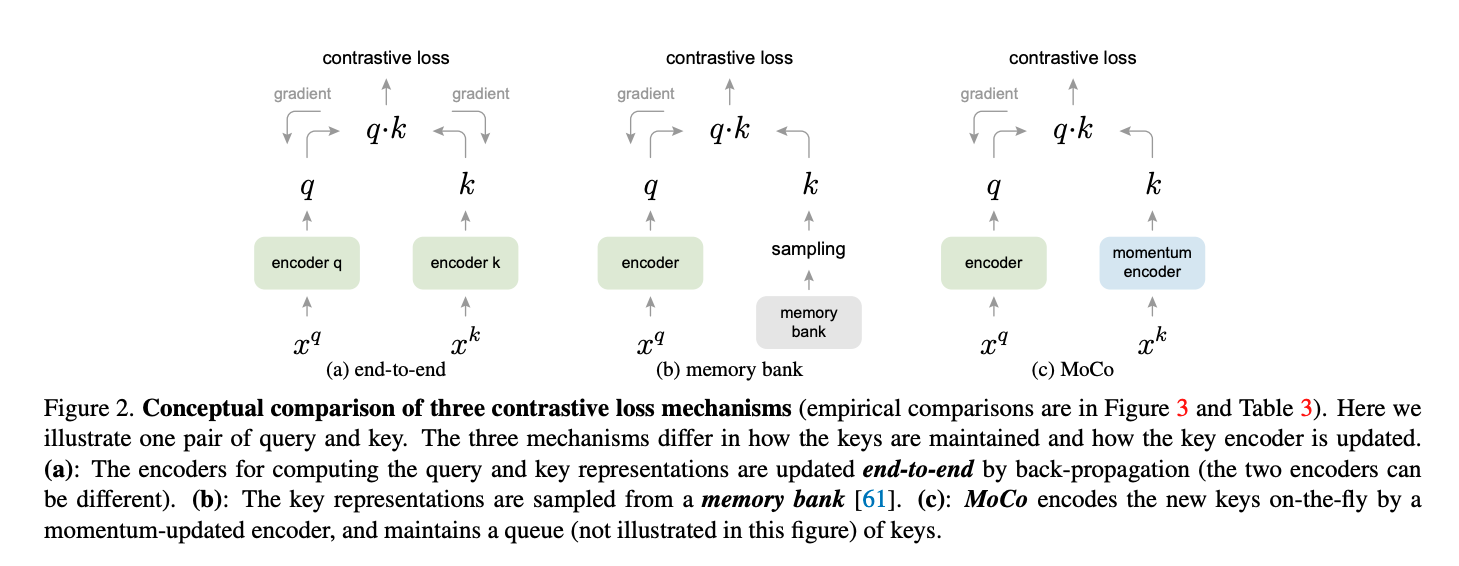
MoCo trains a feature encoder that maps images (or different augmented views of images) into a representation space in which:
- Two views (augmentations) of the same image are pulled close together (“positive pairs”)
- Views of different images are pushed apart (“negative pairs”)
This is the basic idea behind contrastive learning. However, there are some challenges.
CLIP doesn’t seem to suffer from these problems, or does it?
Walkthrough (CS231n 2025 Lec 12)
Key differences from SimCLR
SimCLR’s bottleneck: to get lots of negatives you need a huge batch (8k → TPU pods). MoCo sidesteps this by decoupling negative count from batch size:
| SimCLR | MoCo | |
|---|---|---|
| Source of negatives | other samples in current minibatch | FIFO queue of keys from many past minibatches |
| Key encoder | shared with query encoder | momentum encoder (no gradients) |
| Gradient flows | through both views | only through the query |
| Practical | needs batch 8192 on TPU | works at batch 256 on 8 V100s |
Queue mechanics
Maintain a dictionary of size (e.g. 65536). Each iteration:
- Encode current minibatch’s “key view” with the momentum encoder → enqueue.
- Dequeue the oldest minibatch’s keys.
The queue acts as a large, slowly-evolving dictionary of negatives. No gradients flow into it.
Momentum update
Let be query-encoder params, key-encoder params: changes slowly — essential for queue consistency, because the keys in the queue were encoded by slightly older and a fast-moving key encoder would make them stale.
Pseudocode (Lec 12 slide 89)
for x in loader:
x_q, x_k = aug(x), aug(x)
q = f_q.forward(x_q) # N x C
k = f_k.forward(x_k).detach() # N x C, no grad through key
l_pos = bmm(q.view(N,1,C), k.view(N,C,1)) # N x 1
l_neg = mm(q.view(N,C), queue.view(C,K)) # N x K
logits = cat([l_pos, l_neg], dim=1) # N x (1+K)
labels = zeros(N) # positive is at index 0
loss = CrossEntropyLoss(logits / tau, labels) # InfoNCE
loss.backward()
update(f_q.params)
f_k.params = m * f_k.params + (1 - m) * f_q.params # momentum update
enqueue(queue, k); dequeue(queue)MoCo v2 — hybrid with SimCLR
MoCo v2 (Chen et al. 2020) pulls SimCLR’s two best ideas into MoCo’s framework:
- Non-linear MLP projection head (SimCLR’s ).
- Strong data augmentation (+ Gaussian blur).
Ablation (Lec 12 slide 91, batch 256, 200 epochs):
| MLP | aug+ | cos LR | ImageNet acc | |
|---|---|---|---|---|
| MoCo v1 | 60.6 | |||
| +MLP | ✓ | 66.2 | ||
| +aug+ | ✓ | 63.4 | ||
| +all | ✓ | ✓ | ✓ | 67.5 |
| +800 ep | ✓ | ✓ | ✓ | 71.1 |
MoCo v2 beats SimCLR 8192-batch 66.6% while using batch 256 — no TPU required. Memory 5GB vs SimCLR end-to-end 93GB at batch 4096.
MoCo v3 (Chen, Xie, He 2021)
“This paper does not describe a novel method.” Adapts MoCo to ViT backbones, studies training stability. ViT-BN-L/7 hits 81.0% linear probe / 84.1% fine-tune.
Source
CS231n 2025 Lec 12 slides ~87–93, 102 (MoCo architecture, momentum update, pseudocode, MoCo-v2 ablation table, MoCo-v2 vs SimCLR table, memory comparison, MoCo-v3).