Learning Transferable Visual Models From Natural Language Supervision (CLIP)
CLIP was trained on a huge number of image-caption pairs from the internet.
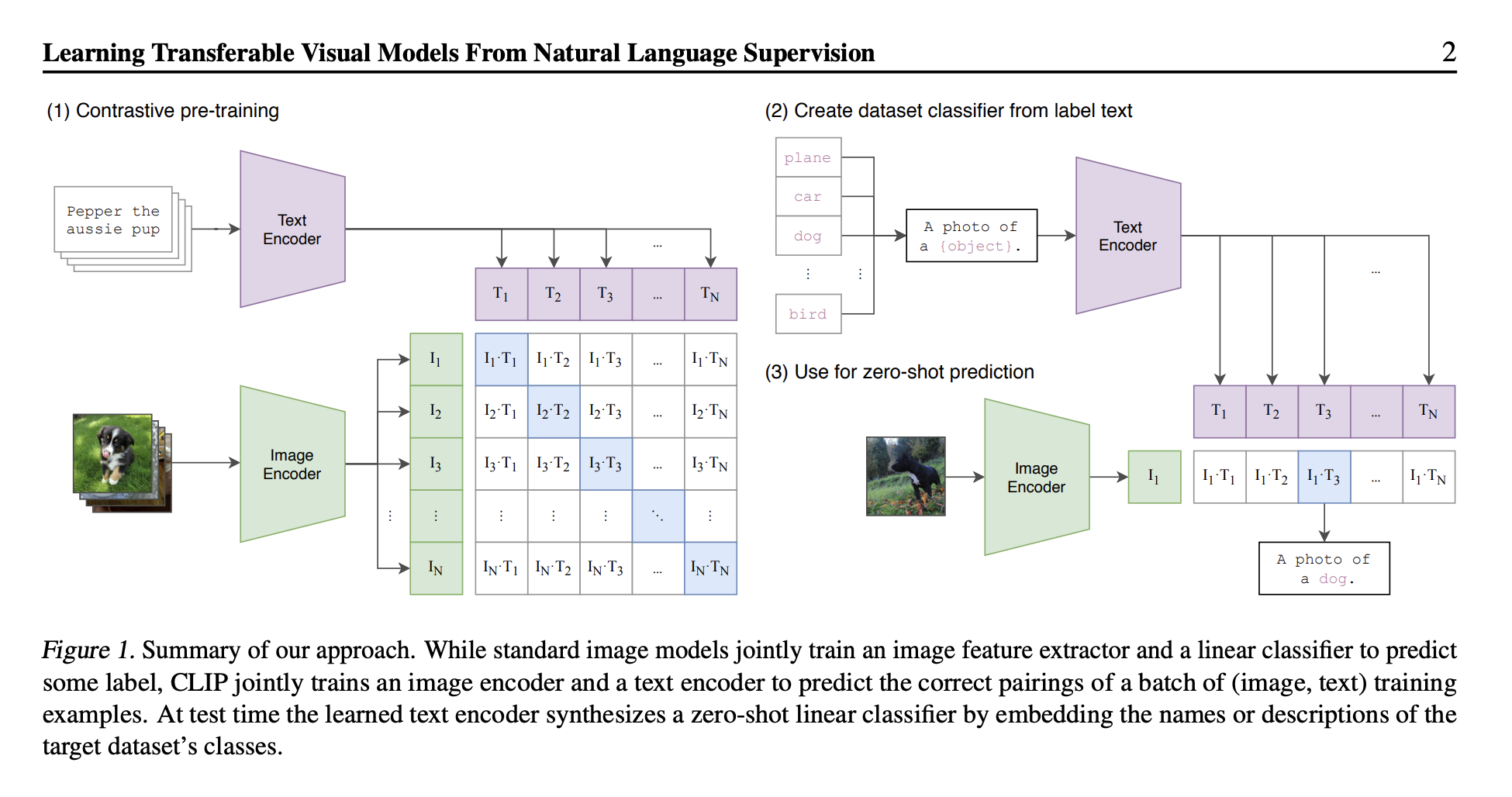
Implementation details:
- Image Encoder is implemented with ResNet-50 / Vision Transformer
- Text encoder is implemented with text transformer
- Contrastive Loss
Pseudocode
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned projection of image to embedding
# W_t[d_t, d_e] - learned projection of text to embedding
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t) / 2
# Figure 3. Numpy-like pseudocode for the core of an implementation of CLIP“At test time the learned text encoder synthesizes a zero-shot linear classifier by embedding the names or descriptions of the target dataset’s classes.”
- Yes, so you take the embeddings, and then you take the image, and the image that has the highest value will be the correct answer
Resources:
CLIP is a model for telling you how well a given image and a given text caption fit together.

- Blue - Initially trying a CNN text encoder + transformer decoder, predicting the caption of the image
- Orange - Using bag of words, see Bag of Tricks for Efficient Text Classification. Essentially at eval time, it will be presented with all the correct classes, and try to predict the correct one
- Green - CNN text encoder + transformer encoder, simply using a contrastive loss
Follow up
Walkthrough (CS231n 2025 Lec 16)
Symmetric InfoNCE
Per batch of image–text pairs with image embeddings and text embeddings (both -normalized), the loss is symmetric over rows and columns of the similarity matrix: The diagonal is the positive pair; everything off-diagonal is an in-batch negative. Trained on 400M pairs (vs ResNet-50’s 1.28M ImageNet labels).
Zero-shot trick
At test time, embed every class name through the text encoder (“A photo of a {class}”), then 1-NN against the image embedding. The text encoder is the classifier — no per-task head, no fine-tuning. Prompt engineering matters:
- “A photo of a {class}” alone: +1.3% vs raw class name
- Mean of multiple prompts (“A photo of a big {class}”, “A photo of a small {class}”, …): +5%
OOD robustness (the main result)
ResNet101 and CLIP-ViT both hit 76.2% on ImageNet, but diverge sharply on distribution shift:
| Dataset | ResNet101 | CLIP |
|---|---|---|
| ImageNet | 76.2 | 76.2 |
| ImageNet V2 | 64.3 | 70.1 |
| ImageNet Rendition | 37.7 | 88.9 |
| ObjectNet | 32.6 | 72.3 |
| ImageNet Sketch | 25.2 | 60.2 |
| ImageNet Adversarial | 2.7 | 77.1 |
Same in-distribution accuracy, dramatically better OOD. Linear-probe CLIP averages ~85% over 27 datasets.
Scale
ResNet101: 44.5M params. CLIP-ViT-L/14@336px: 307M params. Best CLIP variant uses ViT-L/14 at 336px input.
Disadvantages
- Batch-size dependence for fine-grained classes: “animal” works at batch 4, “dog” needs batch ~100, “Welsh Corgi” needs batch ~32K to see meaningful negatives.
- Compositionality fails (Winoground / CREPE / ARO / SugarCREPE): CLIP can’t reliably distinguish “a horse eating grass” from “grass eating a horse.” Bag-of-words behavior.
- NegCLIP collapse: training with hard negatives makes hard positives collapse onto each other.
- Image-level captions are too coarse to teach object-level grounding.
- CSAM contamination found in the 5B-scale follow-up datasets (LAION-5B).
CoCa (Contrastive Captioners, 2022)
Immediate follow-up: keep the contrastive base, add a Multimodal Text Decoder with cross-attention and a captioning loss on top. Hits 86.3% ImageNet zero-shot, 91.0% finetuned.
Source
CS231n 2025 Lec 16 slides ~1–110 (CLIP setup, symmetric loss, zero-shot, prompt engineering, OOD comparison, fine-grained / compositionality / CSAM disadvantages, CoCa follow-up).