World Models
The ideas are actually quite simple:
- (V) Images are encoded into latent representation
- (M) Memory RNN to predict future frames
- (C) Small MLP to predict actions, there’s a
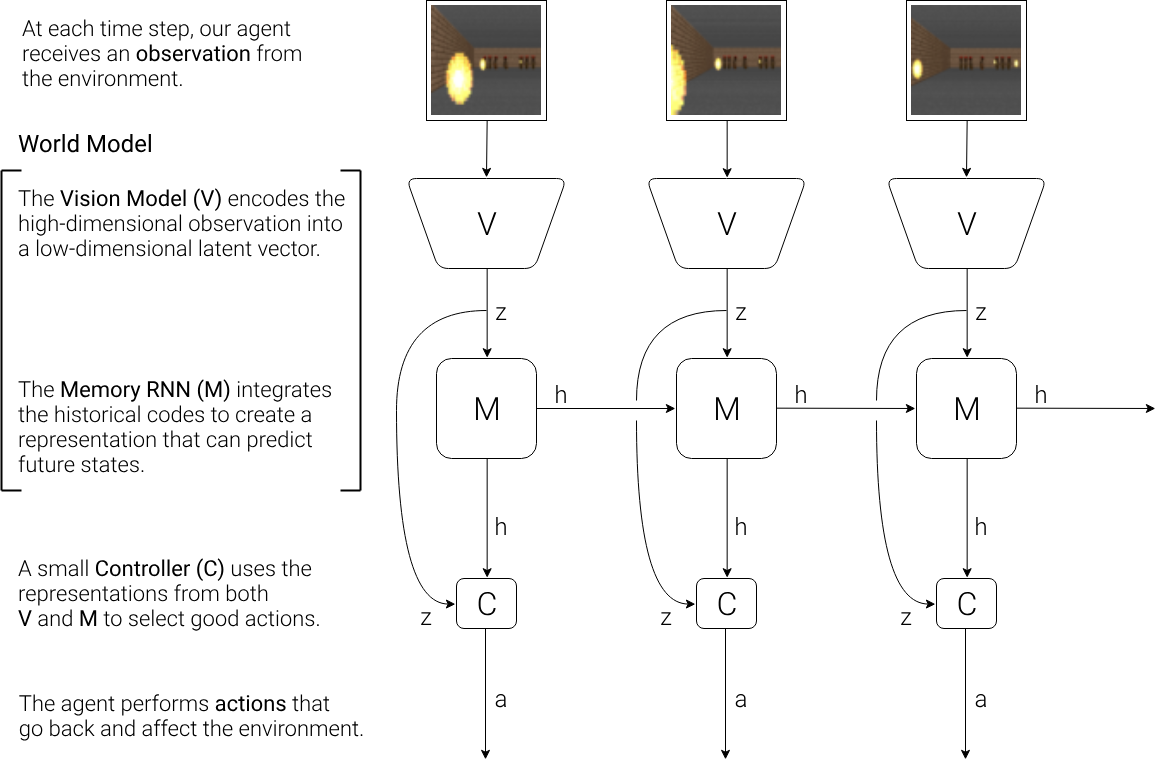
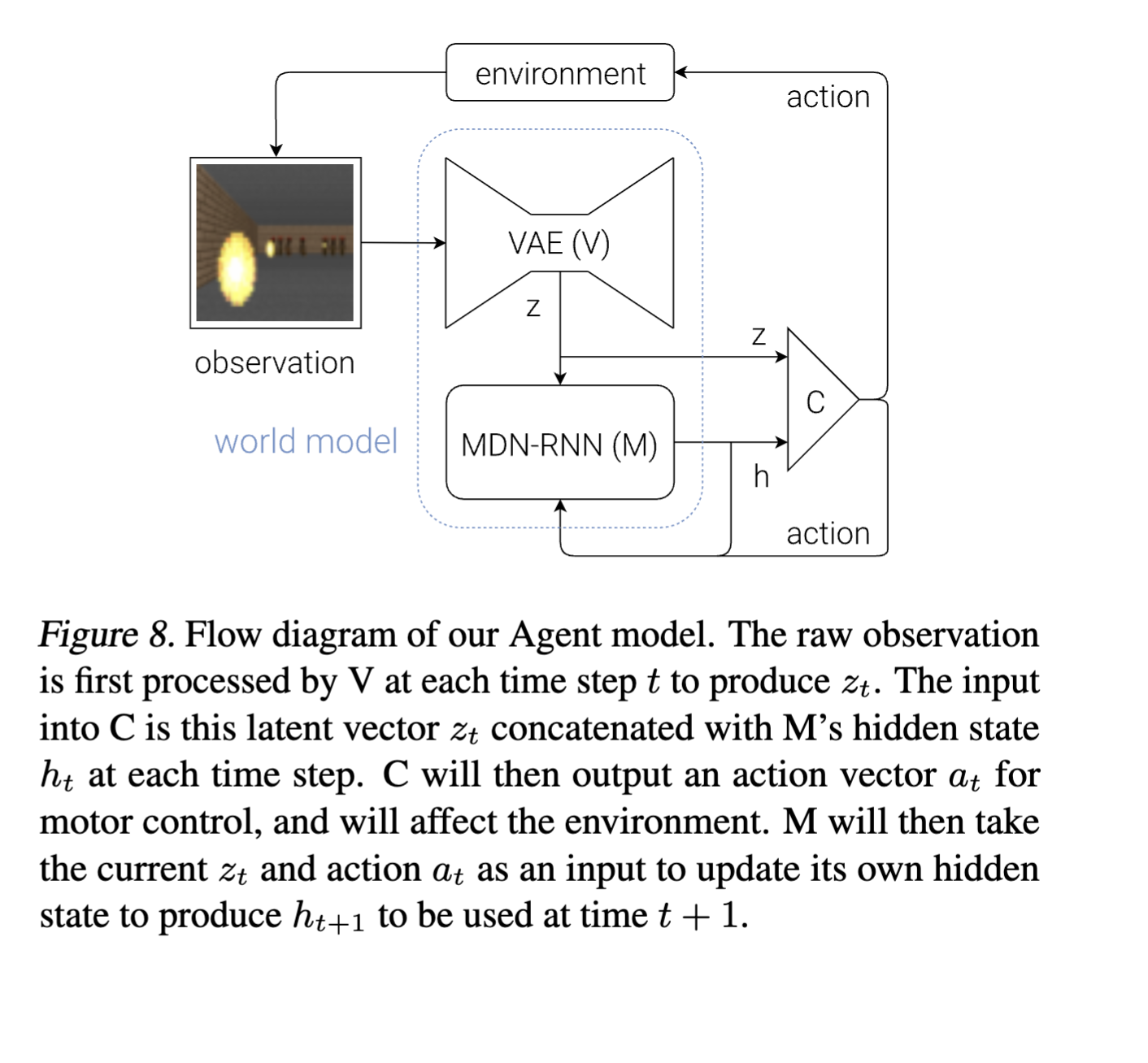
- Am a little confused about how the hidden state is actually passed, look at pseudocode below (we don’t call rnn.forward before using the controller)
- Why not? ummm cuz the M module needs to generate . The controller can’t use , cuz controller generates …
def rollout(controller):
’’’ env, rnn, vae are ’’’
’’’ global variables ’’’
obs = env.reset()
h = rnn.initial_state()
done = False
cumulative_reward = 0
while not done:
z = vae.encode(obs)
a = controller.action([z, h])
obs, reward, done = env.step(a)
cumulative_reward += reward
h = rnn.forward([a, z, h])
return cumulative_rewardTraining details: How is the RNN trained with Teacher Forcing?
- Essentially, we always use ground truth (outputs from VAE) as opposed to predictions from RNN as input to predict
Things to point out:
- All 3 are trained sequentially separately, i.e:
- V is trained first
- Then, M is trained with V’s latent output
- Then C is trained using M’s outputs
- predicts a probability distribution
- To train , they use the CMA-ES algorithm to try and maximize the expected return
Using V model only results in a poor policy (i.e only giving ). Giving it the history which is useful for predicting allows the model to learn.
“Since our world model is able to model the future, we are also able to have it come up with hypothetical car racing scenarios on its own. We can ask it to produce the probability distribution of given the current states, sample a and use this sample as the real observation. We can put our trained C back into this dream environment generated by M”