Date: May 4, 2020
Introduction to Reinforcement Learning and Q-Learning with Flappy Bird
Reinforcement learning is an exciting branch of artificial intelligence that trains algorithms using a system of rewards and punishments. It’s the type of algorithm used if you want to create a smart bot that can beat virtually any video game.
In this article, I will try and demystify reinforcement learning by showing how one goes about building a Flappy bird AI using Q-Learning.
Part 1. Understanding Agent-Environment interactions
Before we actually dive into the algorithm that drives the bot’s “intelligence”, we first need to understand how the AI, also known as the agent, interacts with its environment.
Most Reinforcement Learning games are all built on top of the Markov Chain model, and it’s really important to understand this concept before we move on to reinforcement learning because it serves as the foundation of the entire AI algorithm.
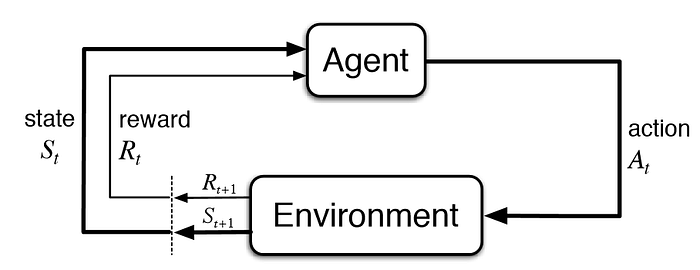
A Markov Chain.
In essence, a Markov chain tells us the continuous relationship between an agent and its environment. The agent (i.e. the AI) takes in a state and a reward from the environment, and based on these two variables, the agent chooses the optimal action. Then, the environment returns a new state and a new reward to the agent based on the action chosen. The process continually loops itself, and this is exactly how the agent and the environment interact with each other. It might not sound as intuitive at first, but let’s see how this applies in the context of Flappy Bird to get a better understanding.
Flappy Bird Environment built using Markov Chains
Before we go ahead and build a Flappy Bird AI, we need to build our own Flappy Bird Environment. The code used in this article was built with the PyGame library. Let’s see how we can build a Markov Chain environment.
States and Observations
We start by initializing our Flappy Bird environment (practically speaking, the environment will be a Python class) with an initial state (S_t), composed of different observations.
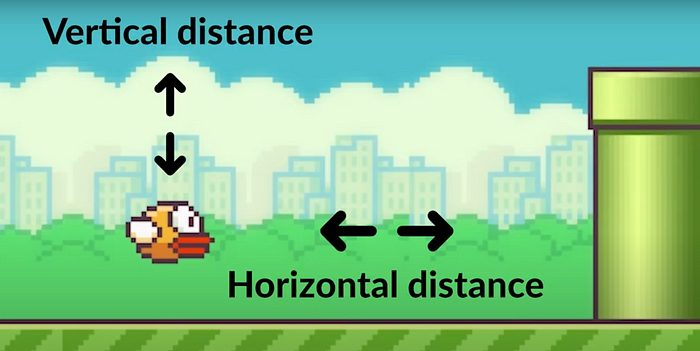
In our custom Flappy Bird environment, we defined 2 observations per state, the bird’s horizontal and vertical distance to the lower pipe. This state composed of the 2 observations will provide the agent with enough information to learn and optimize its actions later on. Equipped with the state, the agent will choose one of two possible actions, to flap or not to flap. The action that is chosen gets fed back to the environment, which will either give back a reward or a penalty to the agent, as well as a new state composed of new observations.
Take a look again at the diagram below in order to better internalize the logic that I’ve just explained behind a Markov Chain.
Rewards
The key to making a “smart” agent lies in the rewards. Since the goal of Flappy Bird is to obtain the highest score possible, we would adjust our rewards to encourage the AI to stay alive as long as possible.
In our case, for each good action that the bot chooses (i.e. it stays alive), the agent will get rewarded with 15 points, but if it chooses a bad action (i.e. hitting the green pipe and ending the game), it will get a negative reward, a penalty of -1000 points. Note that these are constants that we defined ourselves, we can change them to any value we want, but 15 and -1000 points as parameters gave back solid results after experimenting with different values. The agent chooses a new action for every new frame that we see (every time that the game gets refreshed), so a new reward is passed to the agent for every frame.
Hopefully, this first part was clear enough. We are going to jump into Q-Learning, which is the algorithm that the agent uses to learn and improve at the game!
Part 2. Q-Learning
There are quite a few complex algorithms out there for reinforcement learning, but I’ll be explaining basic Q-Learning, a technique that is aimed at choosing the best action for a given state.
Here’s the formal notation, but it won’t mean much to most people.

Essentially, the goal of the Q-Learning algorithm is to maximize the value function Q, where Q stands for ‘quality’ of an action taken in a given state. The quality of an action in a given state is determined by the rewards used to provide the reinforcement. In the end, for any finite Markov decision process (FMDP), Q-learning can find an optimal set of actions starting from an initial state to maximize the expected value of the total reward over any and all successive steps. In other words, Q-Learning is able to look into the future in order to maximize its total rewards rather than just the immediate reward. This is what makes Q-Learning so powerful.
Let’s break it down into how this applies practically for building our Flappy Bird AI.
Step 1. Build a Q-table
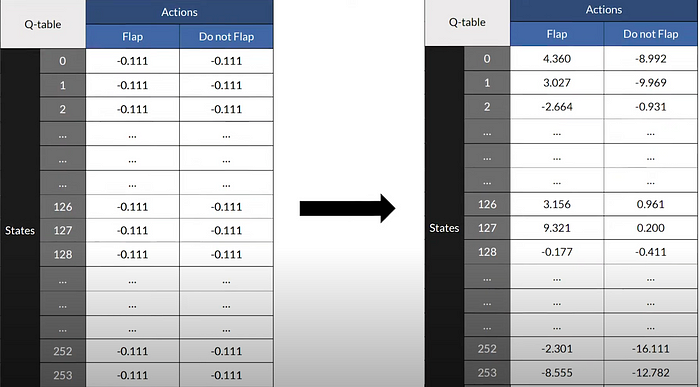
Firstly, we need to build a Q-table, which simply consists of all possible Q-values. Let’s see how Flappy Bird’s q-table looks like.
On the left, each row represents a possible state in game. Remember that in our Flappy Bird environment, we have 2 observations per state. The total number of states in our q-table is simply the total number of observations possible. For this environment, the horizontal distances vary between -2 and 14, while the vertical distances vary between 0 and 14. Since the values are rounded to integers there’s 17x15 possible states, which is 255.
The columns represent all possible actions in game. In our case, there are two possible actions, to flap or not to flap.
The end result is a Q-table of dimensions 255 by 2, which relatively speaking, is pretty small compared to Q-tables of other games.
We start by initializing our Q-table with uniform values. Our hope is to fully populate this q-table with exact values so that we know the ‘quality’ of all actions given a state, ultimately allowing the agent to make the optimal decisions.
Step 2. Q-Learning
Now that we have initialized our q-table, we can use our Q-Learning algorithm to update our q-table.
An agent chooses its actions using its q-table. For a given state, the best action is the one with the highest q-value. Since the table has initially been randomized, the actions will be randomized.
Then, the q-value gets updated using the formula

which, in code, is:
new_q = (1 - LEARNING_RATE) * current_q + LEARNING_RATE * (reward + DISCOUNT * max_future_q)
Learning-rate and discount factor are fixed parameters that do not change, they are calculated using trial and error.
The learning rate controls how quickly the model is adapted to the problem, and is often in the range between 0.0 and 1.0.
The discount factor is a measure of how much we want to care about future rewards rather than immediate rewards. It is usually fairly high (because we put greater importance on long term gains) and between 0 and 1.
We know the value of current_q (obtained from the q-table), we know the reward which is either 15 or -1000 depending on whether or not the bird stays alive, and we can obtain max_future_q also by looking at our q-table, except the state will be the state at t+1, and taking the maximum Q-value of both possible actions.
This is why we say that in Q-Learning, we’re not just interested in the present. We also want to look in the future.
Finally, we update the current_q of that action given a state with a new_q
q_table[state + (action, )] = new_q
Step 3. Repeat
The process of q learning and updating the q-table is repeated until the agent has explored all possible states with all possible actions, allowing it to make extremely smart decisions. One thing to note is that whenever an agent dies, the game simply resets, but the q-table doesn’t reset, so the agent is able to make smarter and smarter decisions over time because of this.
Conclusion
A simple Q-Learning approach performs relatively well in simple games such as flappy bird, but in more complex games, this approach won’t work well. This is because in Q-learning, all states must be explored for the AI to make good decisions, since if the state has not been seen before, the agent will just make a random decision. When we look at other algorithms for reinforcement learning such as Deep Q-Learning, these are much more powerful because agents are still able to make smart choices on unknown data.
That’s it for this article, I hope you enjoyed!
Steven Gong