AWS Deepracer
This seems like a great platform to put my Reinforcement Learning skills/knowledge in practice. Exciting!
Local Training: https://www.youtube.com/watch?v=aC7YuaUo_g4&ab_channel=AWSDeepRacerCommunity
Guide written by Justin Leung: https://docs.google.com/document/d/1QcoBlv7ALaznP69WrdWsklchxlmXTaYfVGjPP1oY1kk/edit?usp=sharing
Username: deepracer Password: deepracer
At home, it will automatically connect to the Elora-House internet, in which case you should
ssh deepracer@10.120.6.73
I was running into all these issues, but you just need to make sure you run ros2 stuff from sudo for the topics to show up.
sudo suros2 daemon stopfixed all of these issues? I couldn’t get a basic display to show up.
Preliminary Notes
Camera seems to be published at ~30fps
ros2 topic hz /camera_pkg/display_mjpegaverage rate: 30.002
min: 0.019s max: 0.046s std dev: 0.00498s window: 32
average rate: 29.999
min: 0.019s max: 0.046s std dev: 0.00475s window: 62
average rate: 29.981
min: 0.019s max: 0.046s std dev: 0.00419s window: 93
average rate: 29.990
min: 0.019s max: 0.046s std dev: 0.00386s window: 124
However, this seems to be publishing
Wall Follow
colcon build --packages-select wall_follow && . install/setup.bash && ros2 run wall_follow wall_follow_nodeConfusion
You can just directly interface with it in ROS2, which makes it a lot easier to use.
So I was getting really confused because for the reward function, they pass in this params as an input argument, and I just don’t know where it comes from.
Below is their Neural Network architecture, and I thought they got it from the output of the CNN. Like they would train it separately.
Because I don’t think you can get the params directly, there is like x,y position, so it basically is able to do Mapping…? Which is pretty hard.
- And how does that transfer to the real world? How does it just know where it is??
Check this repo out https://github.com/aws-deepracer/aws-deepracer-workshops/blob/master/Advanced%20workshops/400%20Level%20DeepRacer%20Workshop/content/400-level-workshop/modifyneuralnetwork.md
We can obtain the absolute position in the simulation, so maybe that works. It is a CNN that learns to do mapping, but it would only work on that given map. You train it on that map, and the labels are the (x,y) positions.
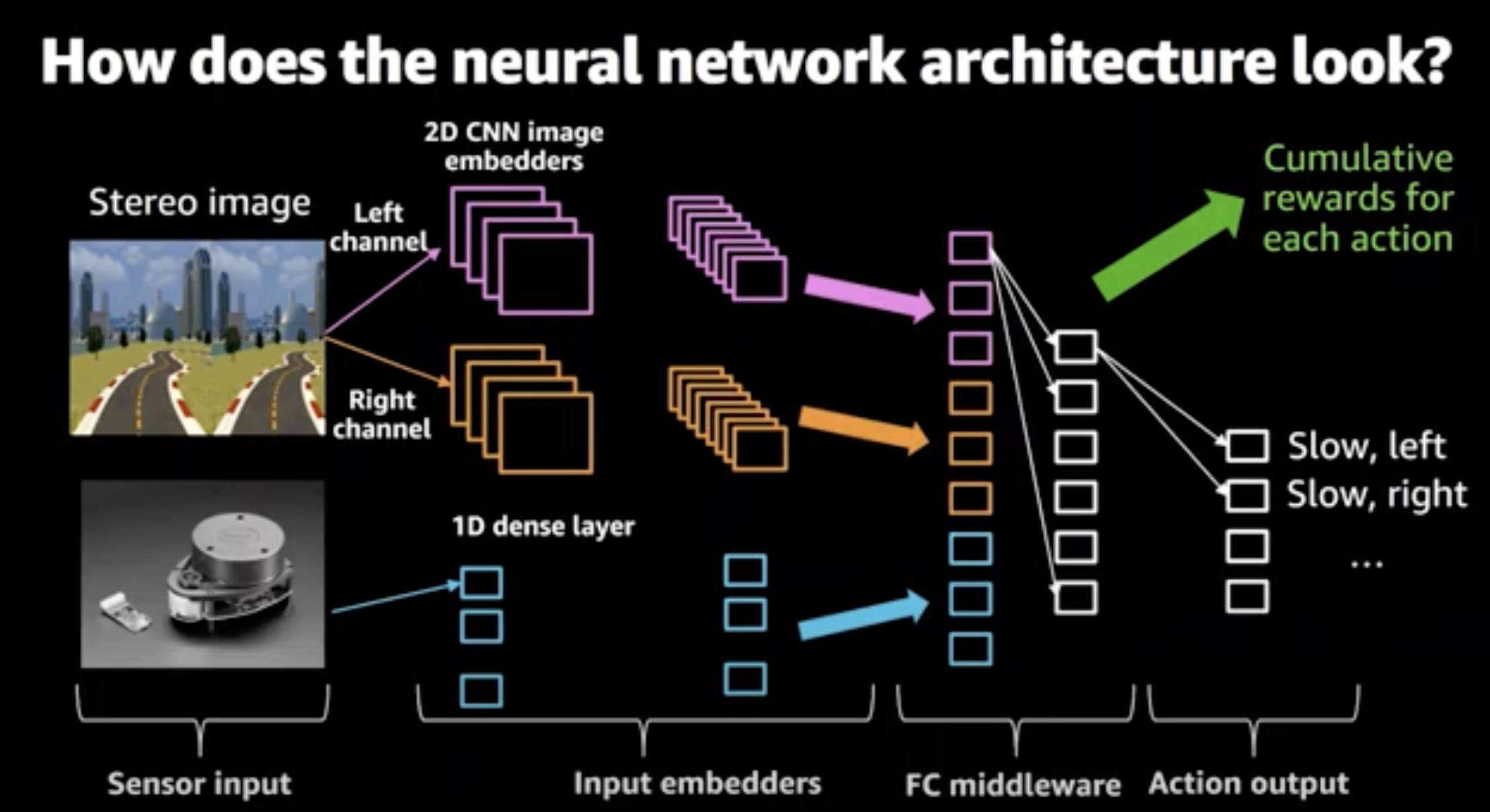
This is really cool, but I feel like i need to find focus. Finish the Poker agent first.
https://tealfeed.com/training-deepracer-speed-oys4d
https://towardsdatascience.com/an-advanced-guide-to-aws-deepracer-2b462c37eea
https://github.com/aws-deepracer/aws-deepracer-workshops
For youtube, reinforcement learning, you have to explain how the problem is framed: They use a CNN for feature extraction, and then that is fed through a policy network, the AWS slides are actually pretty cool.
- The problem is framed as a Reinforcement Learning problem
- Exploration vs exploitation (show during training)
Programming your reward function. We force the car to move at a certain speed. Use Discrete actions.
- Reward function
Reward function tricks:
- Steps: how often the loop updates
- Input parameter: Waypoints to reward different behavior
https://docs.aws.amazon.com/deepracer/latest/developerguide/what-is-deepracer.html
F1tenth video is about scan matching. Optimize everything towards making YouTube videos. For Poker, you need those really fancy graphics.
Terribly slow course: https://www.aws.training/Details/eLearning?id=32143, they don’t allow you to 2x speed
Three Part videos:
- 200L: Get rolling with machine learning
- 300L: AWS DeepRacer analysis tools
- 400L: Conquer the track with SageMaker
Waypoints: World record tips (winning team): https://qiita.com/dnp-ayako/items/2b42f2cf25fa79abd55b
AWS Sagemaker,
Concepts
They use this thing called Nav2 https://navigation.ros.org, which might be interesting to look into for future projects.