CUDA Architecture
These are fundamental:
- CUDA Streaming Multiprocessor
- CUDA Warp
- CUDA Block
- CUDA Thread
Hardware Perspective
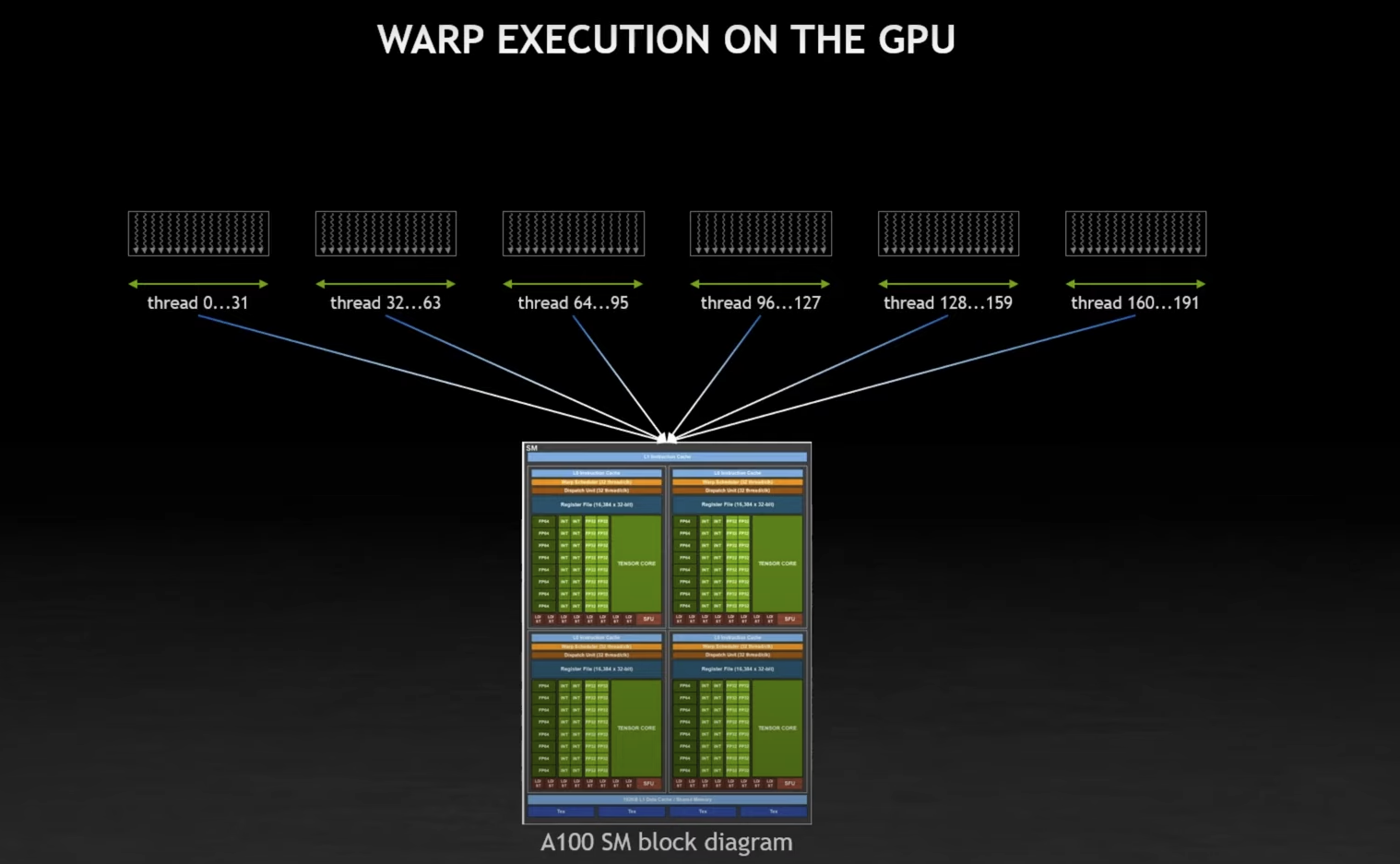
SM Block / Warp Thread
SMs manage 2048 threads (or 64 warps of threads, 32 * 64 = 2048 threads).
Warp
A warp is a logical assembly of 32 threads of execution. It is the vector element of the GPU.
You want the number of threads in a block to be a multiple of 32 so it can be scheduled. A block cannot be placed across 2 different SMs.
- It is fundamental you understand the resources constraints
Warps contain consecutive threads!
Each warp consists of 32 threads of consecutive
threadIdxvalues: thread 0-31 from the 1st warp, 32-63 for the 2nd warp, etc.
Software Perspective
Grid Block Thread

Maximum number of threads in block?
The maximum number of threads in the block is limited to 1024. Source
Maximum number of blocks in grid?
For blocks, it is 65535 in a single dimension. Source
Linking the two together
If you understand the hardware, you will understand why
Characteristics:
- Blocks are scheduled to an SM
- All threads within a particular block must reside on a single SM
- SMs can handle multiple thread blocks at the same time
- A thread ID is assigned to a thread by its respective SM
True or False?
True or False: All the threads inside the thread block are executed at the same time.
False. Threads are scheduled in groups of 32 to a CUDA Warp. If a block has more than 32 threads, there is no guarantee that all threads of the block will run at the same time.
2-4 Warps are scheduled at a time in a given cycle (see Warp Scheduling) per SM, so there is a possibility that they execute at the same time (if each warp is in a different queue). If all warps of the same thread block are assigned to the same warp scheduler on a given SM, then only after the 4th cycle will they start running concurrently.
To free a memory of a thread block inside the SM, it is critical that the entire set of threads in the block have concluded execution.
Block
\rightarrowWarp ConversionEach thread block is physically broken down into warps (chunks of 32 consecutive threads).
A warp does not contain blocks; it is the other way around (a block contains 1 or more warps).
Instructions are issued at the warp level (32 consecutive threads at a time). This execution model is referred to as SIMT Architecture.
What happens if the number of threads per block is
< 32?Since there are less than 32 threads, all of the threads would fit into a single warp. Certain threads of the warp would get masked off and the code would run at lower than peak efficiency. You can think of it as if the warp was divergent for the entire program. Source
Each warp is executed in a SIMD fashion (all threads within a warp execute the same instruction at any given time)
One SM per block!
A block runs on a single SM. It can never span 2 different SMs.
- Why? Because of shared memory access? And synchronization if you want to call
__syncthreads
Confusion
Like I was confused by the point of blocks, because we only really need 1 block and a bunch of threads?
- Yea, so in this scenario, your block would exist in a single SM. Let’s say you let your block be split across a bunch of SMs..
- it’s going to be hard to synchronize threads, you need to have SMs talk to each other
- Shared memory access is also a problem?
The number of thread blocks in a grid is usually dictated by the size of the data being processed, which typically exceeds the number of processors in the system.
Better Performance
This is fundamental to getting better performance:
- Choose a number of blocks that is a multiple of the SMs number (because blocks are spread out over SMs)
- Choose a block size that is a multiple of 32 (because warps consists of 32 threads)