NVIDIA GPU - CUDA
CUDA® is a parallel computing platform and programming model developed by NVIDIA for general computing on GPUs.
Super important to understand how modern Deep Learning models are trained.
Fundamental videos on CUDA Architecture by Stephen Jones:
I probably need to know this working at NVIDIA.
GPU Programming Paradigm
GPU Programming is usually a 3 step process
- Transfer Data to GPU (device)
- Perform computation on GPU
- Transfer Data to CPU (host)
This is why you want to overlap memory transfer and compute whenever possible. You can do this with Prefetching.

Another way to look at it side by side between CPU vs.GPU:
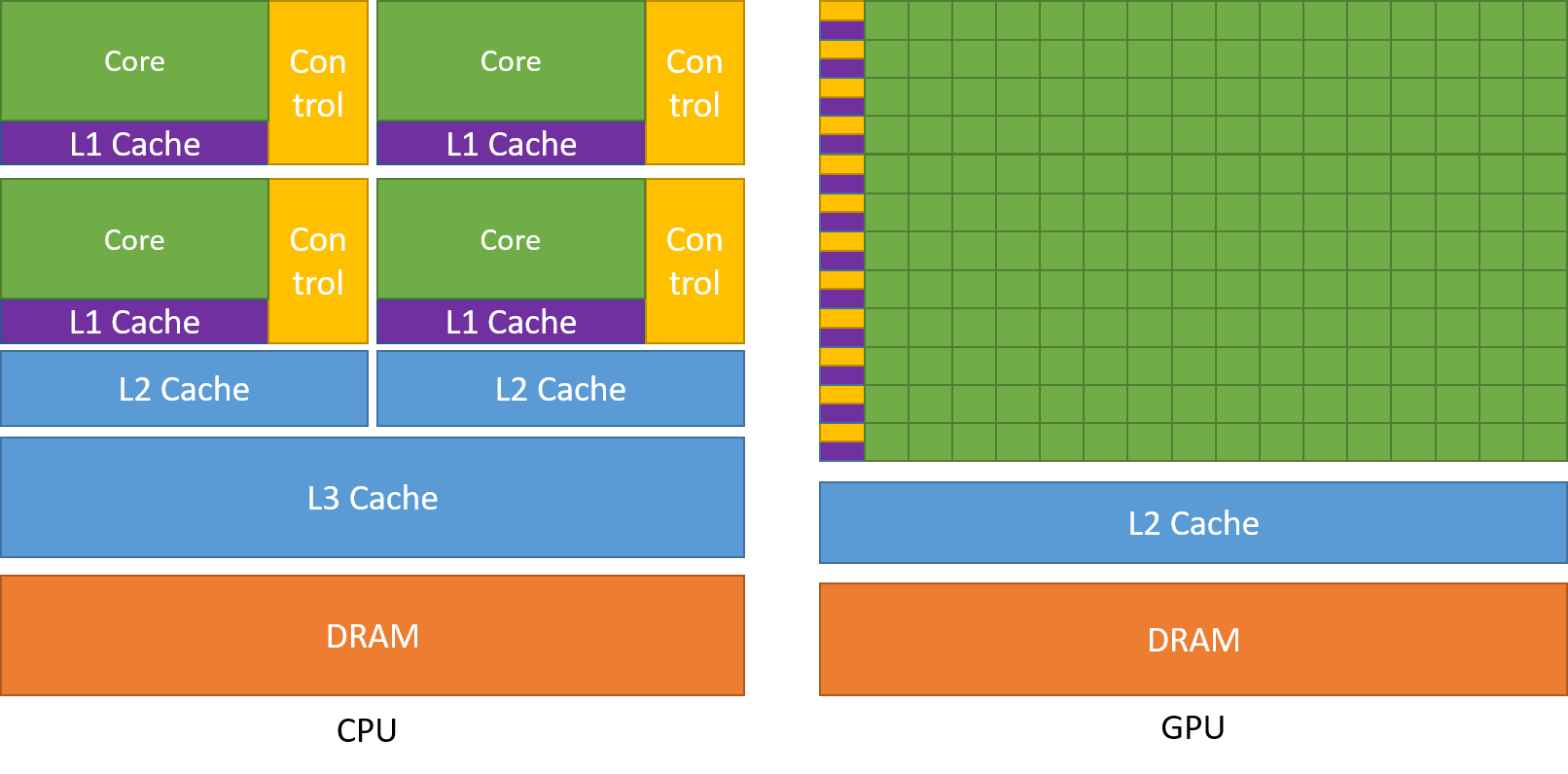
- From https://docs.nvidia.com/cuda/cuda-c-programming-guide/
- DRAM = global memory in the diagram above
Concepts
- GPU Optimization
- Streaming Multiprocessor
- CUDA Best Practices
- CUDA Memory
- NVIDIA Nsight Systems (
nsys) - Prefetching
- CUDA Stream
- CUDA Error Handling
Resources
- https://developer.nvidia.com/accelerated-computing-teaching-kit-syllabus
- Available locally at file:////Users/stevengong/Documents/GPU-Teaching-Kit-Accelerated-Computing
- Other NVIDA kits: https://developer.nvidia.com/teaching-kits
- CUDA Series on YouTube https://www.youtube.com/playlist?list=PLxNPSjHT5qvtYRVdNN1yDcdSl39uHV_sU (apparently too shallow according to Krish)
- Kajanan Recommendation: https://www.olcf.ornl.gov/cuda-training-series/
- Memory Optimizations
The natural way to start with CUDA (Books)
Taken from this gist. The natural way to start with CUDA if you plan to be self taught is:
- CUDA by Example: An Introduction to General-Purpose GPU Programming by Jason Sanders and Edward Kandrot Nice introduction. It is more like playing with your GPU and admire its capabilities.
- [Programming Massively Parallel Processors, 3rd Edition: A Hands-on Approach] by David B. Kirk and Wen-mei W. Hwu It explains a lot of things in GPU Programming. You simply can’t go without it.
- Available locally here
- CUDA Application Design and Development by Rob Farber I would recommend a nice look at it. Grasp some concepts and then move to.
- CUDA Programming: A Developer’s Guide to Parallel Computing with GPUs (Applications of GPU Computing Series) by Shane Cook. I would say it will explain a lot of aspects that Farber cover with examples.
Puzzles
At NVIDIA
Wow, I am finally getting to this. I have access to the deep learning institute stuff for free. I get to learn stuff for free. This is amazing.
- An Easy Introduction to CUDA C and C++ written in 2012
- An Even Easier Introduction to CUDA Blog written in 2017
- CUDA Official Programming Guide
- CUDA Best Practices Guide
How is CUDA implemented from hardware?
-
See https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#hardware-implementation
-
They use Streaming Multiprocessors
To read
- Beyond GPU Memory Limits with Unified Memory on Pascal
- Adaptive Parallel Computation with CUDA Dynamic Parallelism
Tips
So far, the core ideas:
- Use appropriate block and thread size for the functions
- Do not forget
cudaDeviceSynchronize()so the CPU functions actually wait for the GPU functions - Use Prefetching for speedups, overlap copy/compute
The courses from DLI follow this timeline:
- Learn to write simple CUDA applications (through the intro course)
- Learn to overlap copy/compute to parallelize (through the CUDA Streams course)
- Learn to use multiple GPUs (through the multiple GPU course)
- Learn to increase performance with multi-node CUDA
Some Quirks
How does the order of things get printed out? For example, for this code:
#include <stdio.h>
__global__ void printSuccessForCorrectExecutionConfiguration()
{
if(threadIdx.x == 1 && blockIdx.x == 1)
{
printf("Success!\n");
} else {
printf("Failure. Update the execution configuration as necessary.\n");
}
}
int main()
{
/*
* Update the execution configuration so that the kernel
* will print `"Success!"`.
*/
printSuccessForCorrectExecutionConfiguration<<<3, 3>>>();
cudaDeviceSynchronize();
}The output is
Success!
Failure. Update the execution configuration as necessary.
Failure. Update the execution configuration as necessary.
Failure. Update the execution configuration as necessary.
Failure. Update the execution configuration as necessary.
Failure. Update the execution configuration as necessary.
Failure. Update the execution configuration as necessary.
Failure. Update the execution configuration as necessary.
Failure. Update the execution configuration as necessary.
So seems like we cannot count on order. However, for something simpler like a for loop,
#include <stdio.h>
/*
* Refactor `loop` to be a CUDA Kernel. The new kernel should
* only do the work of 1 iteration of the original loop.
*/
__global__ void loop()
{
printf("This is iteration number %d \n", threadIdx.x);
}
int main()
{
/*
* When refactoring `loop` to launch as a kernel, be sure
* to use the execution configuration to control how many
* "iterations" to perform.
*
* For this exercise, only use 1 block of threads.
*/
int N = 10;
loop<<<1, N>>>();
cudaDeviceSynchronize();
}
This is iteration number 0
This is iteration number 1
This is iteration number 2
This is iteration number 3
This is iteration number 4
This is iteration number 5
This is iteration number 6
This is iteration number 7
This is iteration number 8
This is iteration number 9
Runtime
You can plug the N? But this is still compile time. Can CUDA be runtime? YES!
Something like this works surprisingly…!
int main()
{
/*
* It is the execution context that sets how many "iterations"
* of the "loop" will be done.
*/
int i;
cin >> i;
loop<<<1, i>>>();
cudaDeviceSynchronize();
}Handling Block Configuration Mismatches to Number of Needed Threads
It may be the case that an execution configuration cannot be expressed that will create the exact number of threads needed for parallelizing a loop.
Tip
Due to GPU hardware traits, blocks that contain a number of threads that are a multiple of 32 are often desirable for performance benefits.
Solution 1: Use formula to decide the number of blocks
// Assume `N` is known
int N = 100000;
// Assume we have a desire to set `threads_per_block` exactly to `256`
size_t threads_per_block = 256;
// Ensure there are at least `N` threads in the grid, but only 1 block's worth extra
size_t number_of_blocks = N / threads_per_block + 1;
some_kernel<<<number_of_blocks, threads_per_block>>>(N);And then inside the function, use an if statement:
__global__ some_kernel(int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) // Check to make sure `idx` maps to some value within `N`
{
// Only do work if it does
}
}Data Sets Larger Than the Grid
The number of threads in a grid may be smaller than the size of a data set
- We need to utilize each thread multiple times
- One common method to do this is to use a grid-stride loop within the kernel
__global__ void kernel(int *a, int N)
{
int indexWithinTheGrid = threadIdx.x + blockIdx.x * blockDim.x;
int gridStride = gridDim.x * blockDim.x;
for (int i = indexWithinTheGrid; i < N; i += gridStride)
{
// do work on a[i];
}
}Grids and Blocks of 2 and 3 Dimensions
Grids and blocks can be defined to have up to 3 dimensions. Defining them with multiple dimensions does not impact their performance in any way, but can be very helpful when dealing with data that has multiple dimensions, for example, 2d matrices. To define either grids or blocks with two or 3 dimensions, use CUDA’s dim3 type as such:
dim3 threads_per_block(16, 16, 1);
dim3 number_of_blocks(16, 16, 1);
someKernel<<<number_of_blocks, threads_per_block>>>();Given the example just above, the variables gridDim.x, gridDim.y, blockDim.x, and blockDim.y inside of someKernel, would all be equal to 16.