Streaming Multiprocessor (SM)
A Streaming Multiprocessor (SM) is a fundamental component of NVIDIA GPUs, consisting of multiple Stream Processors (CUDA Core) responsible for executing instructions in parallel.
They are general purpose processors with a low clock rate target and a small cache.
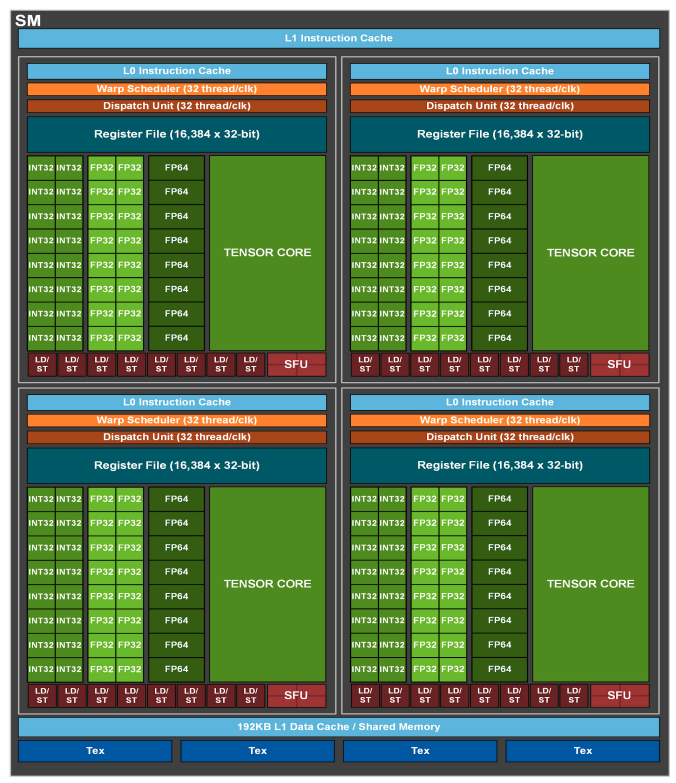
- Inside a GA100 SM, source: Ampere whitepaper
Consists of:
- SUPER LARGE Register File
- This is how they can context switch quickly with no overhead, by keeping data on registers, see Warp Scheduling
- Caches and shared memory
- Warp Scheduler
- Execution units (SFUs, CUDA Cores and Tensor Cores)
Task of SM
SMs execute several thread blocks in parallel. As soon as one of its thread block has completed execution, it takes up the serially next thread block.
From Stephen Jones, I learned that each SM can managed 64 warps, so a total of 2048 threads. However, it really processes 4 warps at a time (see Warp Scheduling).
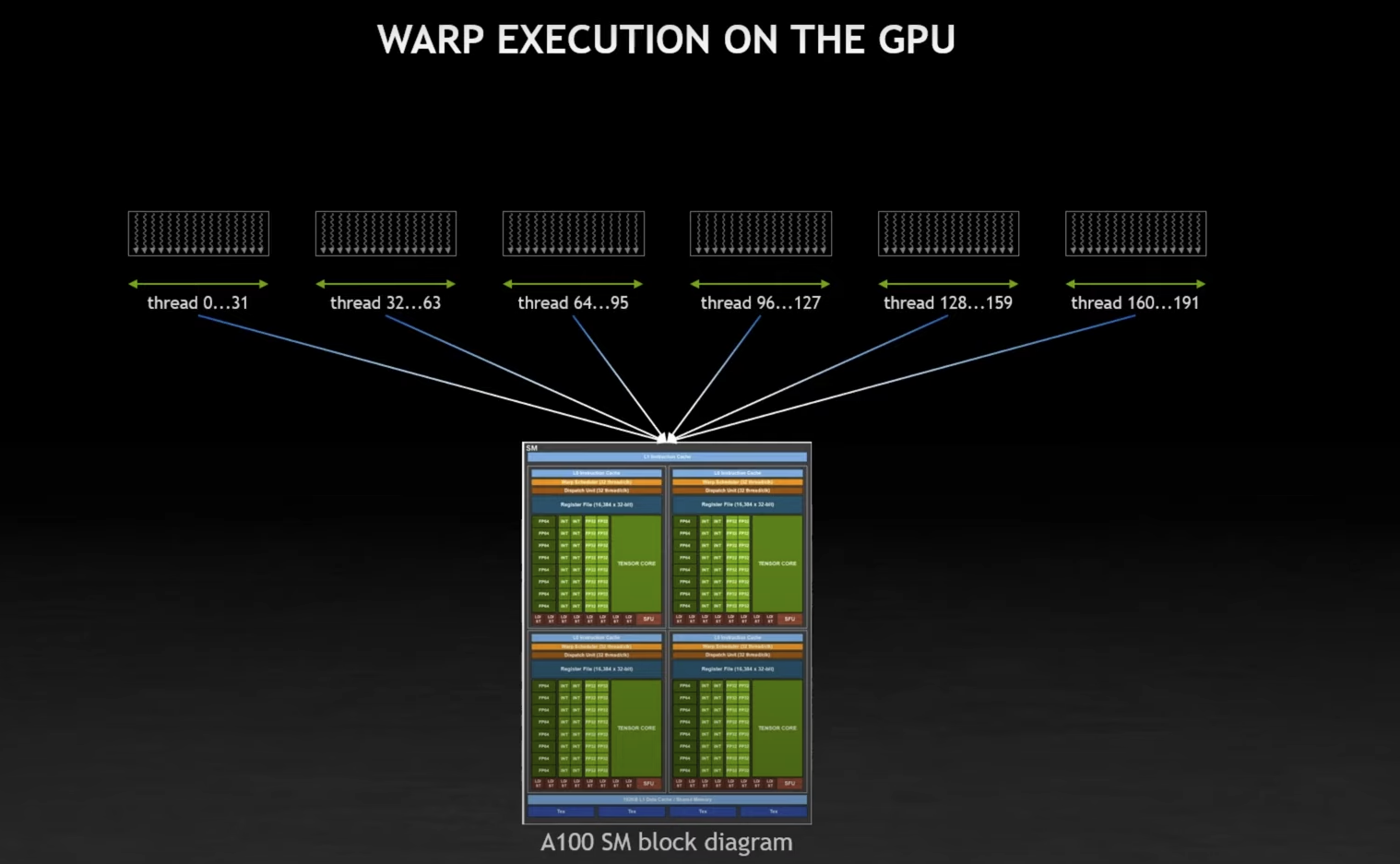

Resources
- Stephen Jones
- http://thebeardsage.com/cuda-streaming-multiprocessors/
- https://en.wikipedia.org/wiki/Thread_block_(CUDA_programming)
- https://saturncloud.io/blog/an-introduction-to-streaming-multiprocessors-blocks-and-threads-in-cuda/
- https://stackoverflow.com/questions/3519598/streaming-multiprocessors-blocks-and-threads-cuda (clarifies CUDA core and CUDA warp)
How many thread blocks at the same time?
An SM may contain up to 8 thread blocks in total.
Branch prediction?
In general, SMs support instruction-level parallelism but not branch prediction.
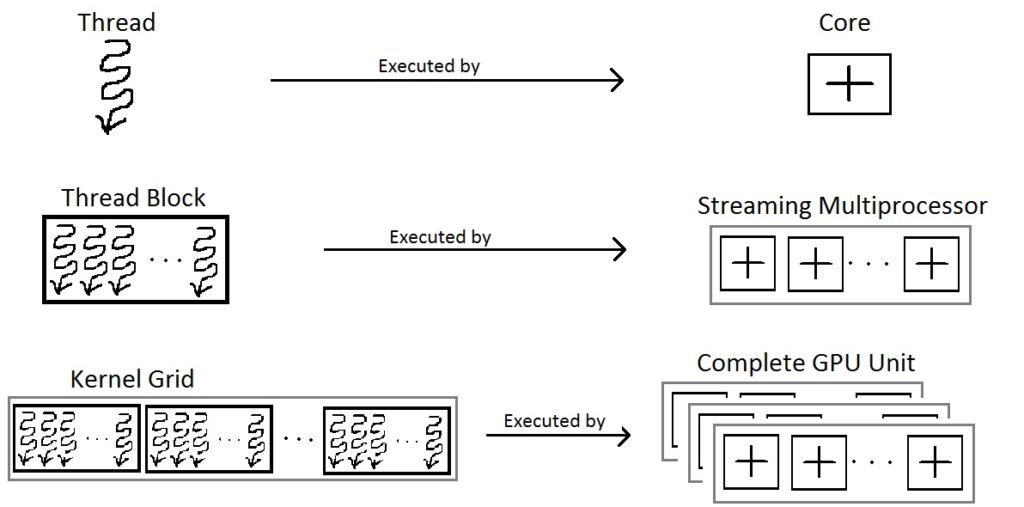
Each architecture in GPU consists of several SM.