Cache Coherency
Cache coherency is the property that (1) all per-CPU caches hold consistent values for any given memory location, and (2) the system behaves as if all CPUs share memory.
Why?
Each CPU has its own L1/L2 cache (L3/L4 are often shared). Without a coherence protocol, the value CPU1 has for
xcould disagree with the value CPU3 has. The lazy fix (marking shared variables uncacheable) “works” but tanks hit rate and floods the bus. We want both: caching and a consistent view.
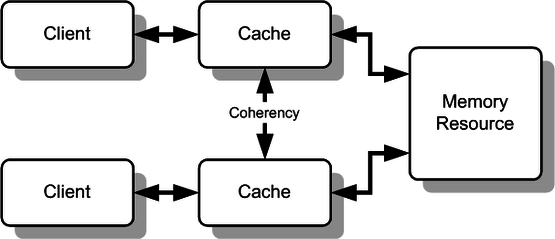
The motivating example (L08)
Initially x = 7 in main memory:
- CPU1 reads
x→ caches it. - CPU3 reads
x→ caches it. - CPU3 writes
x := 42. - CPU1 reads
xfrom its (now stale) cache?
Without a protocol, step 4 returns 7. The protocol’s job is to make step 4 return 42.
Physical picture
- L1 / L2: private per core. L3: shared across cores on the chip. DRAM: off-chip
- Bus (for transport) = the interconnect carrying coherence messages. Real CPUs use a ring, mesh, or Infinity Fabric, not a literal shared wire
- Main memory (for sharing data) = the shared backstop tier. In practice most coherence resolves at L3, not DRAM
The cache protocols just needs a shared tier and a transport; which physical levels play those roles is an implementation detail.
Design axes
A coherence protocol is a point in a small design space:
| Axis | Options |
|---|---|
| How other caches learn about a new write | Snooping (broadcast to all caches via shared bus) vs directory (unicast, writer sends targeted messages only to caches holding the line) |
| What other caches do on a remote write | Write-invalidate (common) vs write-update |
| When writes reach memory* | Write-through (every write) vs Write-back (dirty bit, deferred) |
| What this cache does on a local write miss | Write-allocate (pull line in, then write) vs Write-no-allocate (bypass cache, write straight to memory) |
| Cache State richness | 2-state (Valid/Invalid) vs MSI vs MESI vs MESIF |
"when writes reach memory" → why does the write ever have to reach memory?
Caches are small and evict lines constantly to make room. If a dirty line got evicted without flushing, the value would vanish, no other tier is holding it.
RAM is the only backstop large enough and permanent enough to survive eviction, so every dirty line eventually has to land there. Write-Back just delays that flush until eviction (or a coherence demand); it doesn’t skip it.
You don’t pick, the hardware designer did. More states means less bus traffic at the cost of controller complexity; MESI’s E exists precisely so an unshared line can go to Modified without a bus message.
The same design space applies to software: a distributed cache (Redis/redict across nodes) can run the exact same protocols. The difference is that in software you actually get to pick, while on a CPU you live with what the vendor shipped.
Coherence vs. consistency
Easy to conflate but they’re separate questions (CS 343 §10.2.2):
- Coherence: hardware protocol that keeps duplicates in sync. “Is every cached copy of
xeventually the same value?” (this note)- Consistency: when a write becomes visible to other cores. Eager vs. lazy ack policy
Two mechanisms for how a write reaches other caches:
- Snooping: every cache watches a shared bus and decides for itself whether it cares. Simple, but the bus saturates past ~8 cores
- Directory-based: a hardware table tracks which cores hold each line, so the writer sends targeted messages only to those cores. Scales to many cores at the cost of maintaining the directory