Deep Q-Network (DQN)
Deep Q-Learning is exactly the same as Q-Learning, except that instead of using a Q-table, we use a function approximator (i.e. neural network) with to approximate Q.
Resources
- Original paper https://www.nature.com/articles/nature14236 by DeepMind
- Slides Lecture 2: Deep Q-Learning from Deep RL Foundations, video here
- https://lilianweng.github.io/posts/2018-02-19-rl-overview/#deep-q-network
- Implementation https://docs.pytorch.org/tutorials/intermediate/reinforcement_q_learning.html
DQN still only works with discrete actions. If you want continuous actions, see DDPG.

- NOTE: I originally used screenshot for the pseudocode of original DQN paper, but they don’t even talk about using target , even though you need that for stability reasons
Instead of the Bellman Optimality Backup, we use the Mean Squared Bellman Error so that we can propagate gradients, i.e.
- is a frozen / delayed version of for better convergence
- Note that in DDPG, we actually use Polyak Averaging as opposed to just copying Q
Why
Q_{\theta_{target}}, why not just useQ_\thetaas the target?That is what we do in the Tabular Q-Learning case, because every time we update the Q-table, only 1 entry changes.
HOWEVER, in the continuous case, when we do a gradient update on , any parameter change can drastically alter the function landscape. If you set the target with the same and do a gradient update, this target will shift as fast as your weights do. This feedback loop causes divergence and instability.
Notes from DQN paper:
- are stacked frames in the Atari game, because a single frame doesn’t have enough information (you need to know velocity, which direction the ball is moving)
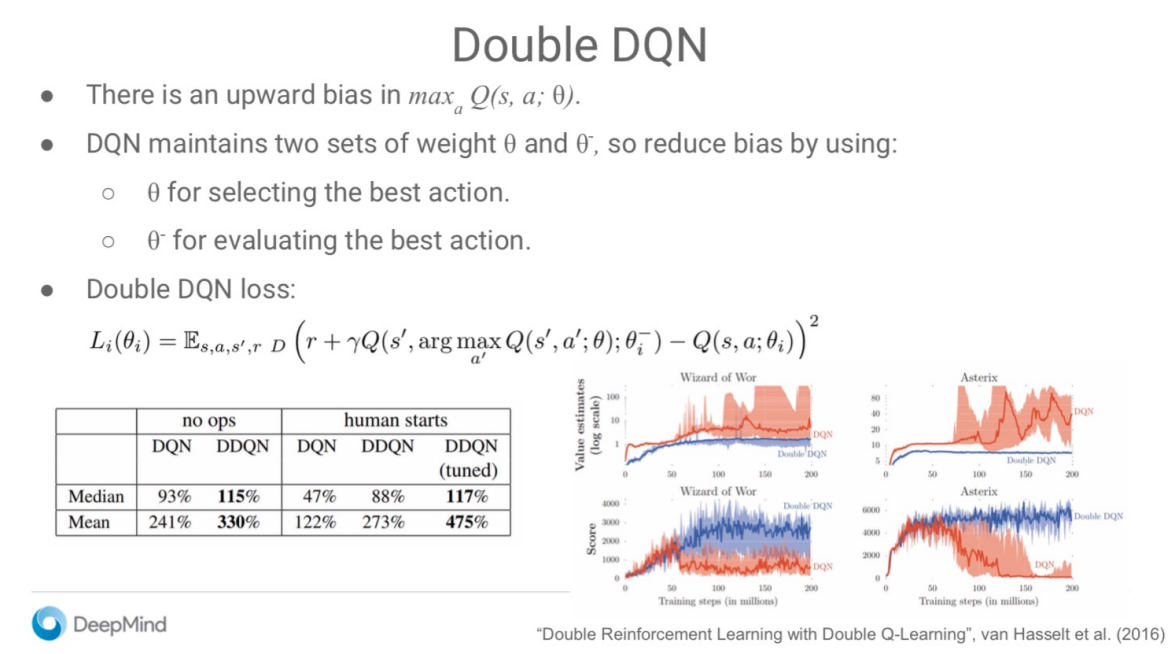
Double DQN
All DQN implementations today use Double DQN just because it is better.