Disk Scheduling
Many of the ideas for OS Scheduling transfer over to Disk Scheduling.
Why is Disk Scheduling even a topic of study/debate?
Because there can be a huge difference between sequential read access and random read access. For a single disk there will be a number of I/O requests If requests are selected randomly, will get poor performance.
That is why we buffer I/O (see O Buffering).
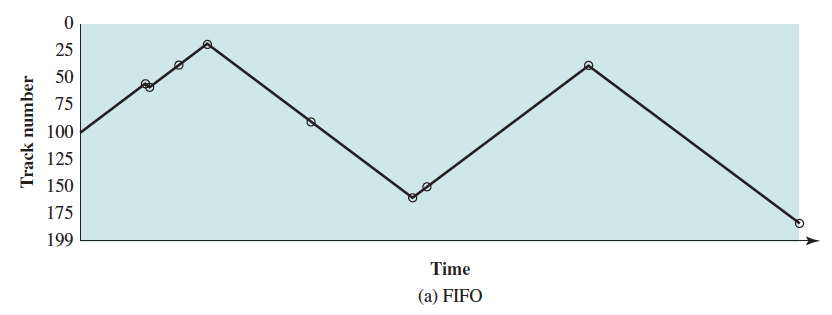
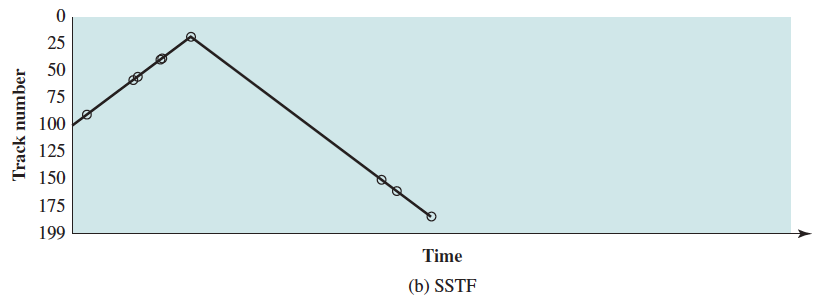
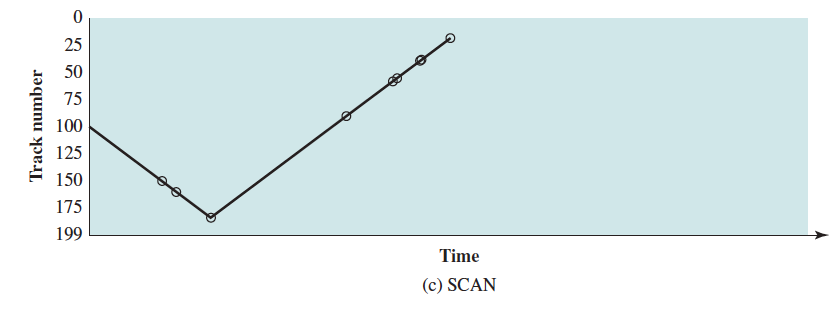
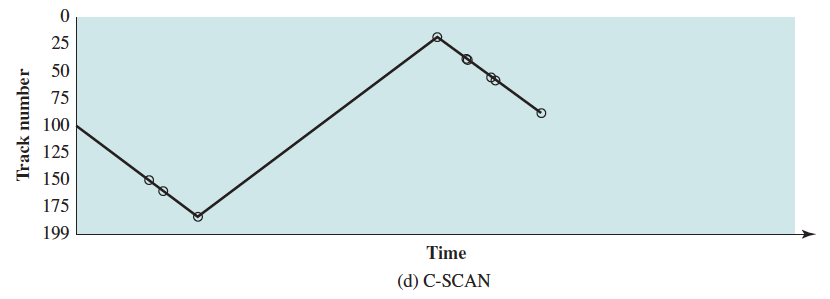
In the examples diagrams below, the requested tracks, in the order received by the disk scheduler, are 55, 58, 39, 18, 90, 160, 150, 38, 184.
Priority-based scheduling
- Goal is not to optimize disk use but to meet other objectives
- Example 1:
- Short batch jobs may have higher priority
- Provide good interactive response time
- Example 2:
- Earlier deadlines have higher priority
- Can lead to counter measures by users
- Can lead to starvation (principle of locality)
First-in, first-out (FIFO)
- Process requests sequentially
- Fair to all processes
- Approaches random scheduling in performance if there are many processes
Last-in, first-out
- Good for transaction processing systems
- The device is given to the most recent user, so there should be little arm movement
- Possibility of starvation since a job may never regain the head of the line
Shortest Seek Time First (SSTF)
- Select the disk I/O request that requires the least movement of the disk arm from its current position
- Always choose the minimum seek time
- Requires knowledge of track position
- Starvation still possible
SCAN (elevator algorithm)
- Arm moves in one direction only (increasing or decreasing track#), satisfying all outstanding requests until it reaches the last track in that direction, reverse the direction
- Similar performance as SSTF
- Biased against area most recently traversed
- Deterministic
Limitations of SCAN
The SCAN policy is biased against the area most recently traversed. Thus, it does not exploit locality as well as SSTF.
C-SCAN (Circular SCAN)
- Restricts scanning to one direction only
- When the last track has been visited in one direction, the arm is returned to the opposite end of the disk and the scan begins again.
- Deterministic, reduces delay for new requests
N-step-SCAN
- Segments the disk request queue into subqueues of length N
- Subqueues are processed one at a time, using SCAN
- New requests added to some other queue when queue is processed