F1TENTH Research Logs
Alright, I’m going to write the logs for doing research.
2023-03-13
Apparently, stable-baselines essentially just expects the zip file when it is loading. That is very weird.
Really annoying dependency issues
you need to
pip install stablebaselines-3
pip install numpy --upgrade
I need to change the friction coefficient.
You set this in f110_env.py
2023-08-01
Reading the paper that I found last week: “In order to guarantee proper curve tracking and smooth transitions on the straights, sections of higher curvature κ obtain a more dense layer coverage than straight sections”
select a set of motion promitives
simplest goal is just get it to drive fast, using frenet frames
2023-07-25
A formulation would be
Look at the professor Maxim Likhachev.
ignore the vulgarity below I was really angry
NO I HAVEN’T FOUND IT WHERE THE F IS IT. KFDLJSKKKKKFJSDOIJFioew ifewopifhw4ehf
Zotero also f- sucks what a f- stupid software can’t even f- sync properly fuck this software.
I hate f- searching for things. It is literally the most annoying thing in the world.
I found it: Multilayer Graph-Based Trajectory Planning for Race Vehicles in Dynamic Scenarios
This was the image I was looking for.
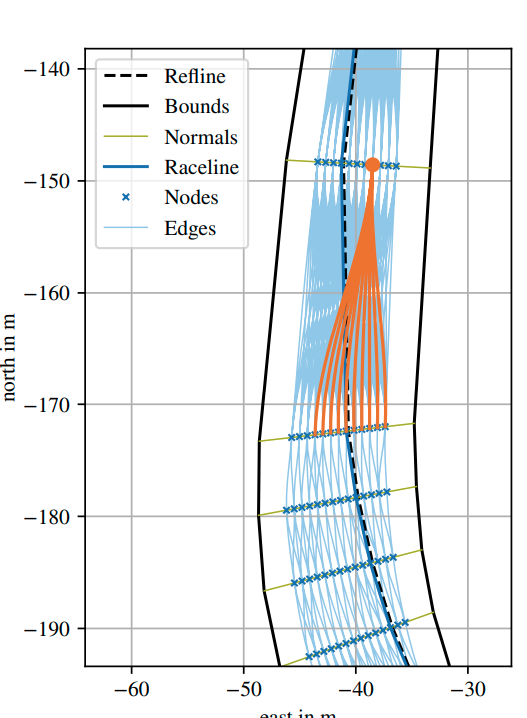
Now, I can be at peace.
Other nicholas baumann stuff:
- Paper: https://arxiv.org/pdf/2209.04346.pdf
- Video: https://www.youtube.com/watch?v=lE_Dk1iJHHg&ab_channel=D-ITETCenterforProject-BasedLearning
2023-07-20
Figure out a formulation that doesn’t require as much Reward Engineering.
Experiment 12 Reward is same as Experiment 11.
minimum speed of 2.0 m/s. I also increased the maximum speed to 6.0m/s.
- the reason I am doing this is because the output is usually just the car being stationary
Can be done by changing the following code:
# BEFORE
self.action_space = spaces.Box(low=np.array([[-1.0, 0.0]]), high=np.array([[1.0, 4.0]]),dtype=np.float64)
# AFTER
self.action_space = spaces.Box(low=np.array([[-1.0, 2.0]]), high=np.array([[1.0, 6.0]]),dtype=np.float64)
Also, add a termination when it reaches the 60s limit.
def _check_done(self):
...
done = (self.collisions[self.ego_idx]) or np.all(self.toggle_list >= 4) or self.current_time > 60For some reason, it is going in circles… let me try revert back to a simpler reward function, without the decay
Experiment 13 Everything done in Experiment 12, but the reward is modified again to simply progress.
reward = 10 * (progress - self.progress)Ahh, it’s still going back in circles. This is the illustration of a faulty reward design. Where the agent has unexpected behavior, similar to what
To fix this, we will end the episode if the progress is in the negative direction.
Experiment 14
reward = 10 * (progress - self.progress)
if (progress - self.progress < 0):
reverse_direction = True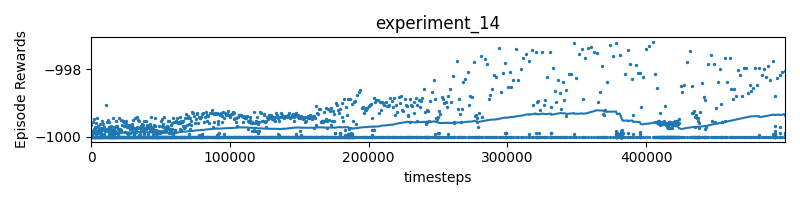
- umm this seems a lot more different than experiment 2?
oh, I know why:
if done and progress <= 0.99:
reward = -1000I punish with -1000 if the car crashes into the wall. Since the plot doesn’t show anywhere with a value of 0, it means that the car is always crashing into the wall.
- So actually, removing the laser scans make it harder, because the car doesn’t know the distances to the walls.
Experiment 15 Would it help if I give it with distance to centerline?
reward = 10 * (progress - self.progress) - distance
if (progress - self.progress < 0):
reverse_direction = True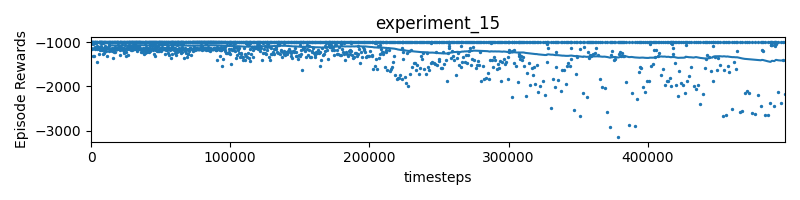
- No, because again, the AI doesn’t have access to scan measurements
Experiment 16 This shows how all episodes terminate when the lidar scans are removed, presumably because the car can’t see anything. Let’s bring back the Lidar scan measurements, but we keep the speed minimum of 2.0m/s so that the car goes faster.
self.action_space = spaces.Box(low=np.array([[-1.0, 2.0]]), high=np.array([[1.0, 6.0]]),dtype=np.float64) # only works for 1 agent for nowreward = 10 * (progress - self.progress)
if (progress - self.progress < 0):
reverse_direction = TrueExperiment 17 Increase minimum speed?
remove # if done and progress <= 0.99: # reward = -1000
focus on overtaking
Other things to try
- Deepening NN hidden layers
- Learning Rate for PPO
Lower level controller for tracking, + action space for these motion primitives
2023-07-13
Spoke with professor, recommends trying decay as part of my reward.
Experiment 7 Instead of directly subtracting the timestep, use a decay.
reward = pow(0.99, self.timestep) * 10 * (progress - self.progress) - max(0.1 * distance, 1)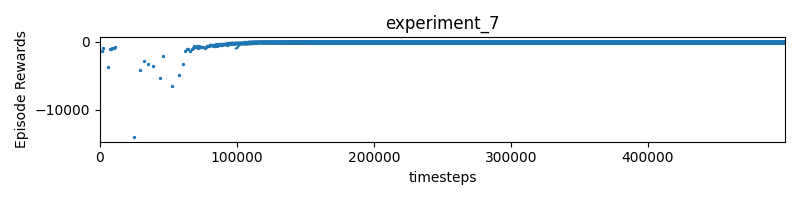
Experiment 8 Remove distance to centerline, only track progress but include declay
reward = pow(0.99, self.timestep) * 10 * (progress - self.progress) 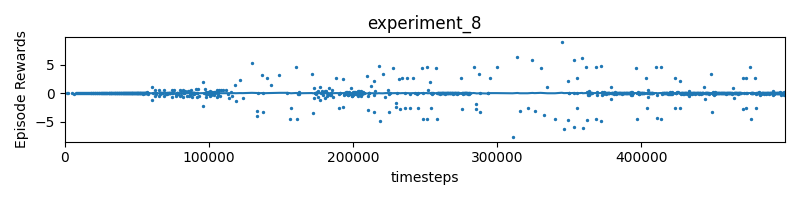
Experiment 9
reward = 0.99**self.timestep * 10 * (progress - self.progress) - min(0.01 * distance**2, 1)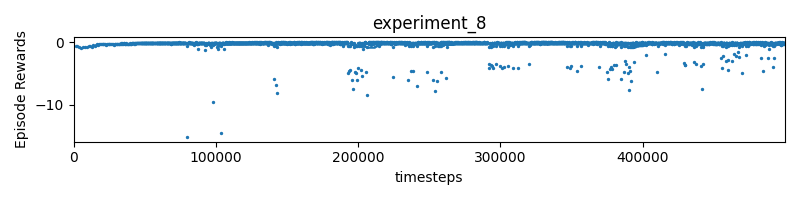
- mislabeled experiment_8
Make reward super negative at the terminal state if collision
Experiment 10
if len(self.poses_x) == 0:
reward = - self.timestep
else:
# Distance to racing line
progress, distance = self.get_progress_along_track(np.array([self.poses_x[0], self.poses_y[0]]))
# Three factors: progress along track, distance to racing line, and time
ALPHA = 0
BETA = 0
GAMMA = 0
reward = 0.99**self.timestep * 10 * (progress - self.progress) - min(0.01 * distance**2, 1)
self.progress = progress
self.current_time = self.current_time + self.timestep
# update data member
self._update_state(obs)
# check done
done, toggle_list = self._check_done()
if done and progress <= 0.99:
reward = -1000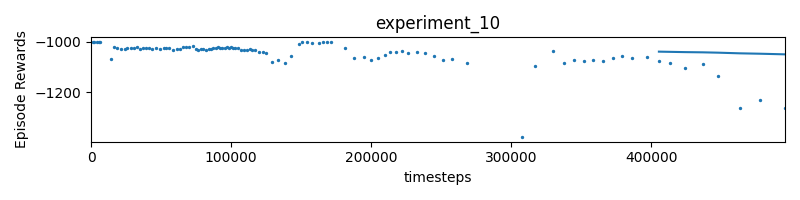
Experiment 11 Remove the laser scan as part of the observation space. Reward is the same as experiment 10
reward = 0.99**self.timestep * 10 * (progress - self.progress) - min(0.01 * distance**2, 1)2023-07-05
Ok, reprioritization, let me first make sure that I can get the fastest lap with the single agent case, using RL instead of traditional optimization.
I need to know the theoretical fastest racing line. To do that, I need to feed in a proper map and racing line.
Experiment 3
reward = 10 * (progress - self.progress) - distance- where distance is the distance to the racing line.
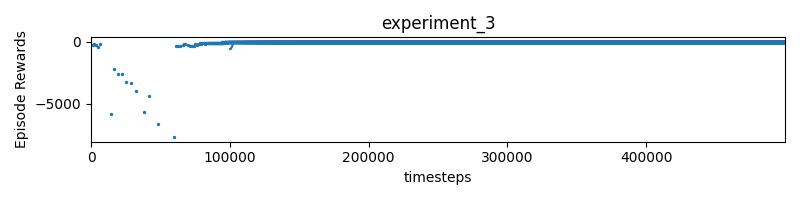
- weird…? I get a really bad result? it gives very similar results to experiment 1.
- The agent just crashes into the wall
Experiment 4 What if I try assigning a long more weight to progress?
reward = 1000 * (progress - self.progress) - 5 * distance - 0.1 * self.timestepExperiment 5 The car is moving super slowly, close to the racing line, so we should probably punish a lot more for being slow.
reward = 1000 * (progress - self.progress) - 500 * distance - 500 * self.timestepStill superrrrr slow…
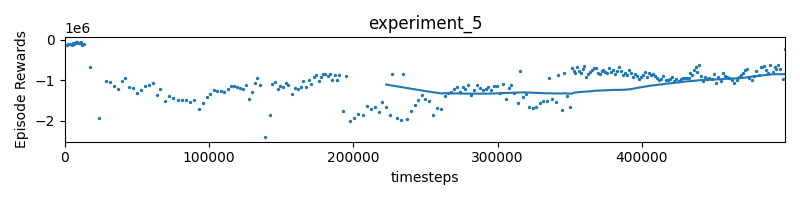
- yea the rewards are blown way out of proportion. However, we start seeing some nice shape?
Experiment 6 “large reward values can lead to instability in learning, as they can cause large updates to the agent’s estimated action values or policy.”
I’ve noticed in my previous experiments that the rewards blow out of the scale. I’m going to try to keep it within -1 and 1, and see how that does:
- The progress is a number between and , and it’s impossible for the car to finish within one timestep. Multiplying by 10 makes sense
- The distance is kind of arbitrary. Larger tracks will have larger distances. Distance is always POSITIVE
timestepis defined to be0.01, so that is too small. I think we should decay by 0.2 (multiply by 20)?
reward = 10 * (progress - self.progress) - max(0.1 * distance, 1) - 20 * self.timestep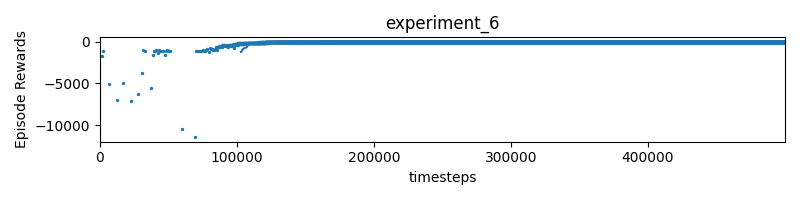
Just crashes into the wall…
2023-07-04
Getting back into the research thing.
I need to get multi-agent working. Here are the things I am going to do today
- Document rewards
- Design multi-agent setup
- Environment generator? So you could get domain adaption to work? Maestro stuff is actually pretty cool
Experiment 1
These rewards are defined inside f110_env.py
reward = 10 * (progress - self.progress) - self.timestep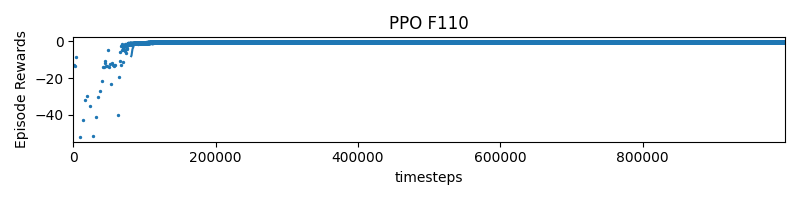
Experiment 2
reward = 10 * (progress - self.progress)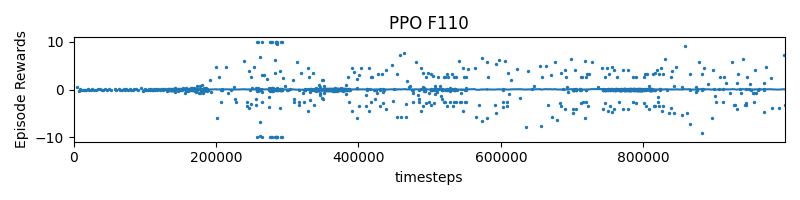
Experiment 3
- If you feed the RC car distance to the racing line as an observation space, that can probably help the RC car determine that minimizing distance to the racing line will help a lot.
But I also am doing the multi-agent setup.
2023-06-18
The goal today is to really understand how PPO works, I’ve been following the Peter Abbeel RL Foundation series.
2023-06-14
So initially, I had this.
model = A2C("MlpPolicy", env, verbose=1)To get the F1TENTH gym running with Stable Baselines, I needed to add the definition for self.observation_space and self.action_space.
- Figured out by following https://www.gymlibrary.dev/content/environment_creation/
However, when I started training, I got this error
ValueError: You must use `MultiInputPolicy` when working with dict observation space, not MlpPolicy
- So basically, the issue is that MlpPolicy expects 1D data, whereas MultiInputPolicy can deal with your situation “This policy allows for more flexibility in handling different types of inputs in the environment.”
This is observation space for f1tenth gym (for now):
self.observation_space = spaces.Dict(
{'ego_idx': spaces.Box(low=0, high=np.inf, shape=(1, ), dtype=np.int16),
'scans': spaces.Box(low=0, high=np.inf, shape=(self.num_agents, 1080), dtype=np.float64),
'poses_x': spaces.Box(low=-np.inf, high=np.inf, shape=(self.num_agents, ), dtype=np.float64),
'poses_y': spaces.Box(low=-np.inf, high=np.inf, shape=(self.num_agents, ), dtype=np.float64),
'poses_theta': spaces.Box(low=-np.inf, high=np.inf, shape=(self.num_agents, ), dtype=np.float64),
'linear_vels_x': spaces.Box(low=-np.inf, high=np.inf, shape=(self.num_agents, ), dtype=np.float64),
'linear_vels_y': spaces.Box(low=0, high=0, shape=(self.num_agents, ), dtype=np.float64),
'ang_vels_z': spaces.Box(low=-100.0, high=100.0, shape=(self.num_agents, ), dtype=np.float64),
'collisions': spaces.Box(low=-np.inf, high=np.inf, shape=(self.num_agents, ), dtype=np.float64),
}
)Also, I had to change reset() so that it doesn’t expect poses in its arguments. And the return value is just observations.
But okay, it’s fixed, now I have another error.
ValueError: Expected parameter loc (Tensor of shape (1, 2)) of distribution Normal(loc: torch.Size([1, 2]), scale: torch.Size([1, 2])) to satisfy the constraint Real(), but found invalid values:
it’s because i get nan values.
I think it is because I allowed my velocity to be negative.
Before
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(self.num_agents, 2), dtype=np.float32)
After
self.action_space = spaces.Box(low=np.array([-1.0, 0.0]), high=np.array([1.0, 4.0]),dtype=np.float32) # only works for 1 agent for now
hmmm I am getting different values than what i am expecting
this is when i call env.step(action) and print out obs
{'ego_idx': [0], 'scans': [array([1.48816205, 1.51503759, 1.49369368, ..., 2.63124369, 2.62152873,
2.64538327])], 'poses_x': [0.7], 'poses_y': [0.0], 'poses_theta': [1.37079632679], 'linear_vels_x': [0.0], 'linear_vels_y': [0.0], 'ang_vels_z': [0.0], 'collisions': array([0.]), 'lap_times': array([0.01]), 'lap_counts': array([0.])}Notice that there is lap_times and lap_counts..?
- Yea, I forgot those were are a thing
obs = self.sim.step(action)
obs['lap_times'] = self.lap_times
obs['lap_counts'] = self.lap_countsNow that I got the basic environment running, I need to think a little harder about the observation space, and the rewards that are present.
Reward shaping
Currently, the reward is given by time steps. There is also no punishment for when the car runs into the wall.
We need a concept of track progress.
So here’s what I’m going to do: Clean up observation space
- Remove ego_idx
- collisions?? (it’s a 0 or 1)
# update agent collision with environment
if agent.in_collision:
self.collisions[i] = 1.Reward should be based on track progress, and subtract time.
progress = self.get_progress_along_track(np.array([self.poses_x[0], self.poses_y[0]]))
reward = 10 * (progress - self.progress) - self.timestep
self.progress = progressI will do the video recording later on.
https://stable-baselines3.readthedocs.io/en/master/guide/examples.html#record-a-video
Haven’t tried this, but this is how you load a checkpoint??
from stable_baselines3.ppo import PPO
# Create the PPO model
model = PPO("MultiInputPolicy", env, verbose=1, tensorboard_log="./ppo_f110_tensorboard/")
# Define the log directory and checkpoint file path
log_dir = "./ppo_f110_tensorboard/"
checkpoint_path = log_dir + "checkpoint.zip"
# Optionally, you can load a pre-trained model checkpoint
model = PPO.load(checkpoint_path, env=env, tensorboard_log="./ppo_f110_tensorboard/")
# Continue training
model.learn(total_timesteps=timesteps)
# Save the updated model
model.save(checkpoint_path)Experiment 1 Initial testing, PPO doesn’t seem to converge to anything useful
reward = 10 * (progress - self.progress) - self.timestep
I think it’s because I didn’t design my rewards to be super good. Maybe don’t punish for being slow yet.
Maybe also add a negative reward for being close to the walls? Like you want to be safe … hmm that might be too much.
Experiment 2 I didn’t negate the timestamp. This seems to work much better!
reward = 10 * (progress - self.progress)
- The negative reward can probably be explained by the fact that the car is going backwards.
Now, an interesting question arizes: Wouldn’t a Genetic Algorithm be equally as good as RL?
2023-06-13
There are many dependency conflicts. I think that f1tenth_gym requires gym==0.19.0. However, when installing stable_baselines3, they have a higher version for the gym.
This is the error I have when installing back the older version of the gym.
stable-baselines3 1.8.0 requires gym==0.21, but you have gym 0.19.0 which is incompatible.
f110-gym 0.2.1 requires pyglet<1.5, but you have pyglet 1.5.20 which is incompatible.
2023-06-08
First, I need to understand how the observation space is encoded.
I think we can try this in multiple steps
- Single agent, try to complete an entire lap around the course
- Multi-agent, opponent has a fixed policy of staying behind the track
- You can give negative reward at every time step where the opponent is in front of you
- Of course, there is the shortcoming that it doesn’t mean that you automatically win the race