Used for Reinforcement Learning
Stable Baselines
I believe I used this for my Poker AI.
https://stable-baselines3.readthedocs.io/en/master/
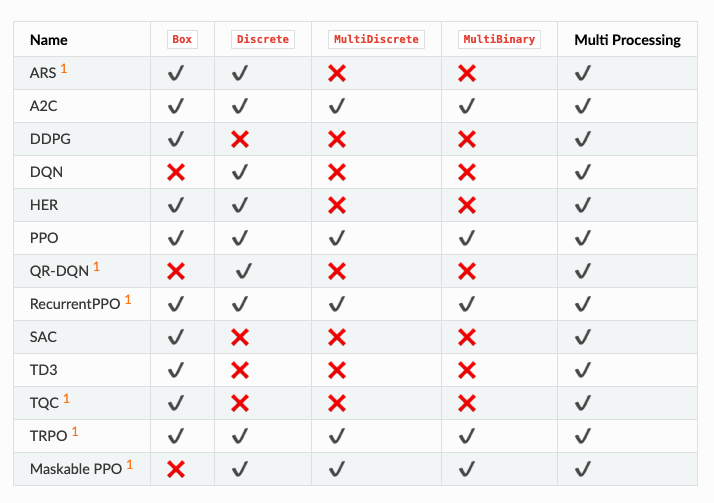
List of Algorithms https://stable-baselines3.readthedocs.io/en/master/guide/algos.html
This is example code for PPO
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
# Parallel environments
vec_env = make_vec_env("CartPole-v1", n_envs=4)
model = PPO("MlpPolicy", vec_env, verbose=1)
model.learn(total_timesteps=25000)
model.save("ppo_cartpole")
del model # remove to demonstrate saving and loading
model = PPO.load("ppo_cartpole")
obs = vec_env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = vec_env.step(action)
vec_env.render("human")Notice the following line:
obs = vec_env.reset()Usually, in reset, you also return info. This is kind of incorrect, you need to modify the environment so it works
How things work under the hood
https://stable-baselines3.readthedocs.io/en/master/guide/custom_policy.html
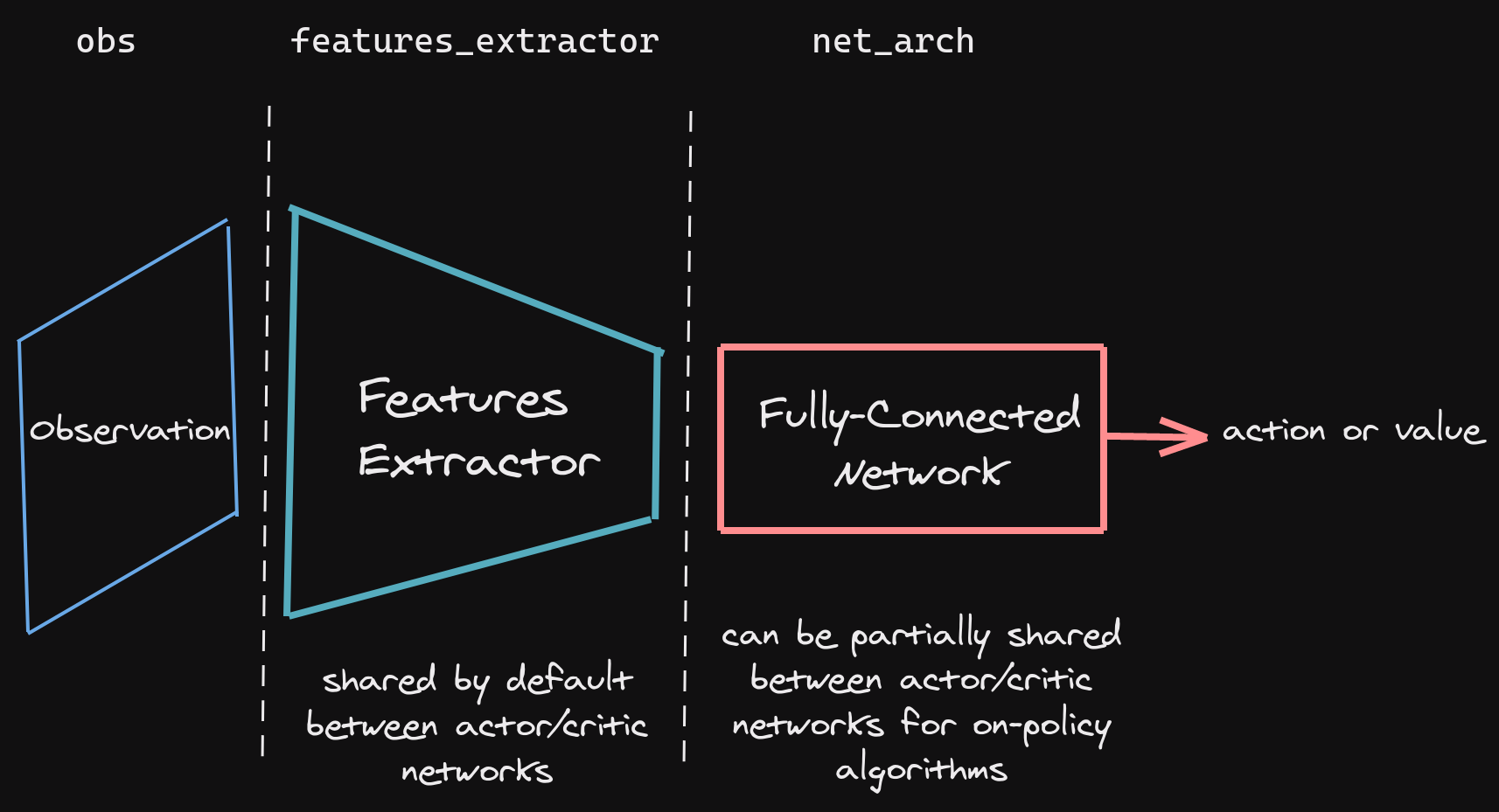
SB3 networks are separated into two mains parts (see figure below):
-
A features extractor (usually shared between actor and critic when applicable, to save computation) whose role is to extract features (i.e. convert to a feature vector) from high-dimensional observations, for instance, a CNN that extracts features from images. This is the
features_extractor_classparameter. You can change the default parameters of that features extractor by passing afeatures_extractor_kwargsparameter. -
A (fully-connected) network that maps the features to actions/value. Its architecture is controlled by the
net_archparameter.