Flow Matching
This is what pi0 uses.
Flow matching is a training method used to learn a mapping from a source distribution to a target distribution by approximating the underlying vector field.
- Source: meta guide
The paper:
Resources
- https://arxiv.org/pdf/2412.06264 (Flow matching guide and code by meta)
- https://flowreinforce.github.io/
- https://mlg.eng.cam.ac.uk/blog/2024/01/20/flow-matching.html
- https://diffusionflow.github.io/
- https://www.youtube.com/watch?v=DDq_pIfHqLs&ab_channel=Jia-BinHuang
- https://www.youtube.com/watch?v=7cMzfkWFWhI
Flow matching vs. Flow-Based Model?
Flow-based models care about exact probabilities. Flow matching cares about how to move from one distribution to another. Flow Matching bypasses the need for computing the log-determinant Jacobian or training via score-matching or log-likelihood.
Flow matching vs. diffusion?
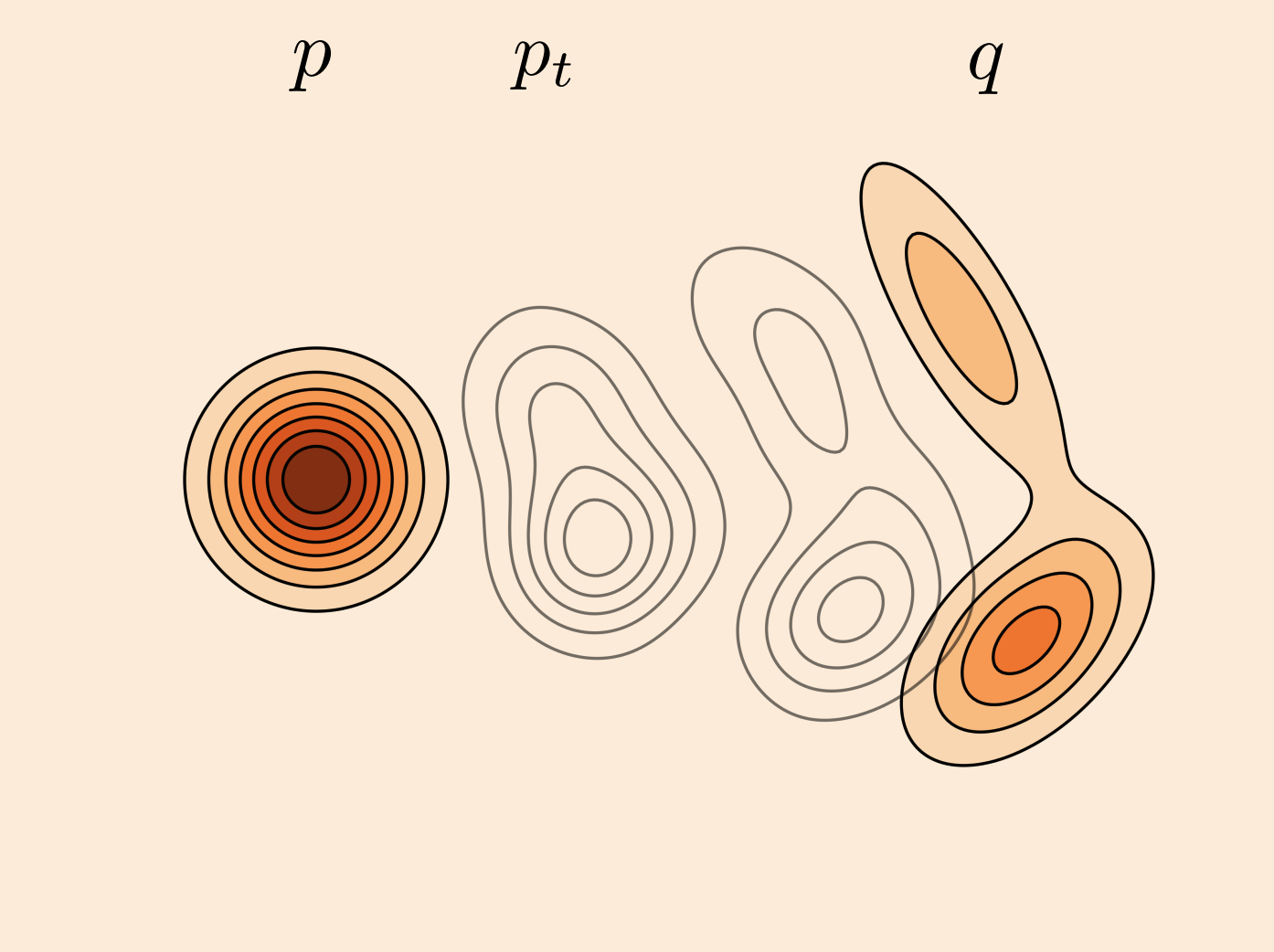
Image says it all.
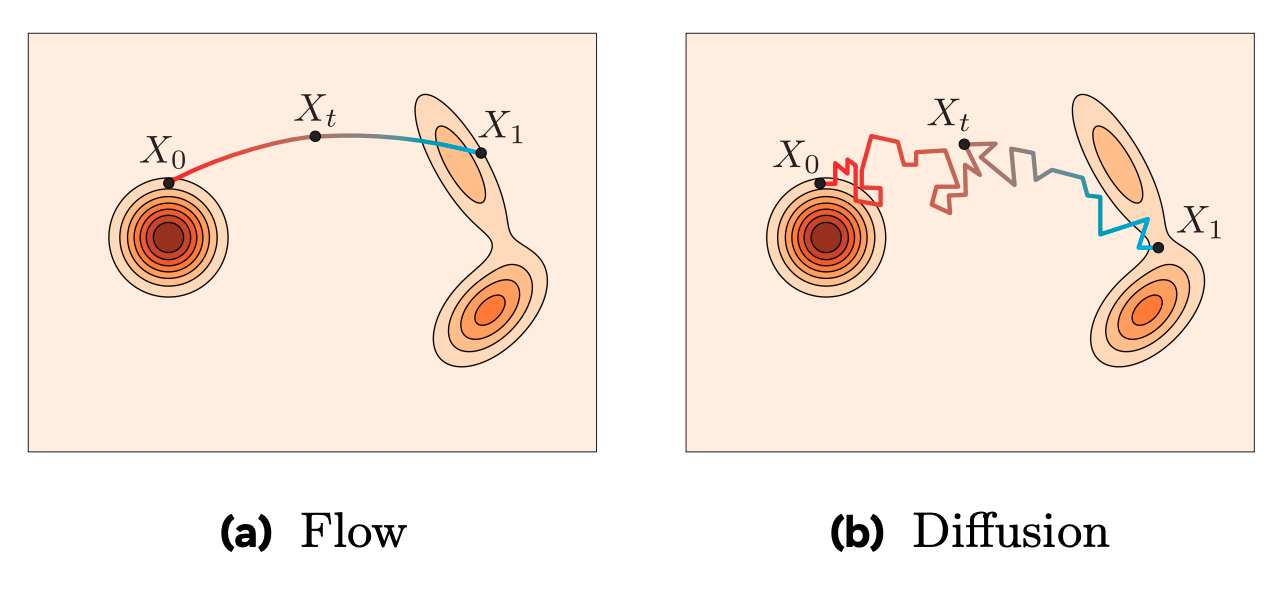
Instead, it trains the flow function to match a target vector field that would push a sample from the base distribution to the target distribution over time.
This makes training more stable.
Flow matching is an alternative way to train CNFs, where you learn the dynamics directly by matching flows instead of optimizing Log Likelihood.

See pi0 for equation of flow matching in context of robotics.

I think the above diagram is the easiest to way to visualize in 1D what’s happening. Imagine you are doing matching to map from one gaussian to the other gaussian. You end up with these curved shapes. It’s very unlikely that you go from one outlier to the other outlier (outlier to mean and mean to outlier are more common), so you’ll never learn those velocity fields.
Now, think about a multi-modal flow matching. Intuitively, you cannot do this.
Background on flow matching
Taken from notes pi0. ChatGPT conversation: https://chatgpt.com/share/68c5b5fa-7db4-8002-9708-ef4e953533f9
The idea: we want to turn noise into a data sample (here, an action ). We can describe this transformation as continuous process over time , i.e. an ODE:
with initial condition and at the end, . Flow matching tries to learn this vector field .
To train such a model, we choose reference path between and and differentiate over it. The simplest path between and is a straight line (i.e. straight line interpolation):
- At , you are at pure noise, and at , you’re at the action
Taking the derivative with regards to , we see that:
- The derivative of a straight line is a constant slope, so we just need to learn this constant!
We learn to predict this gradient (a constant) so that at inference time, we learn this mapping for any arbitrary
At inference time, we start with random noise and integrate the learned vector field from to , and use forward Euler integration rule:
- where is the integration size ( in paper)
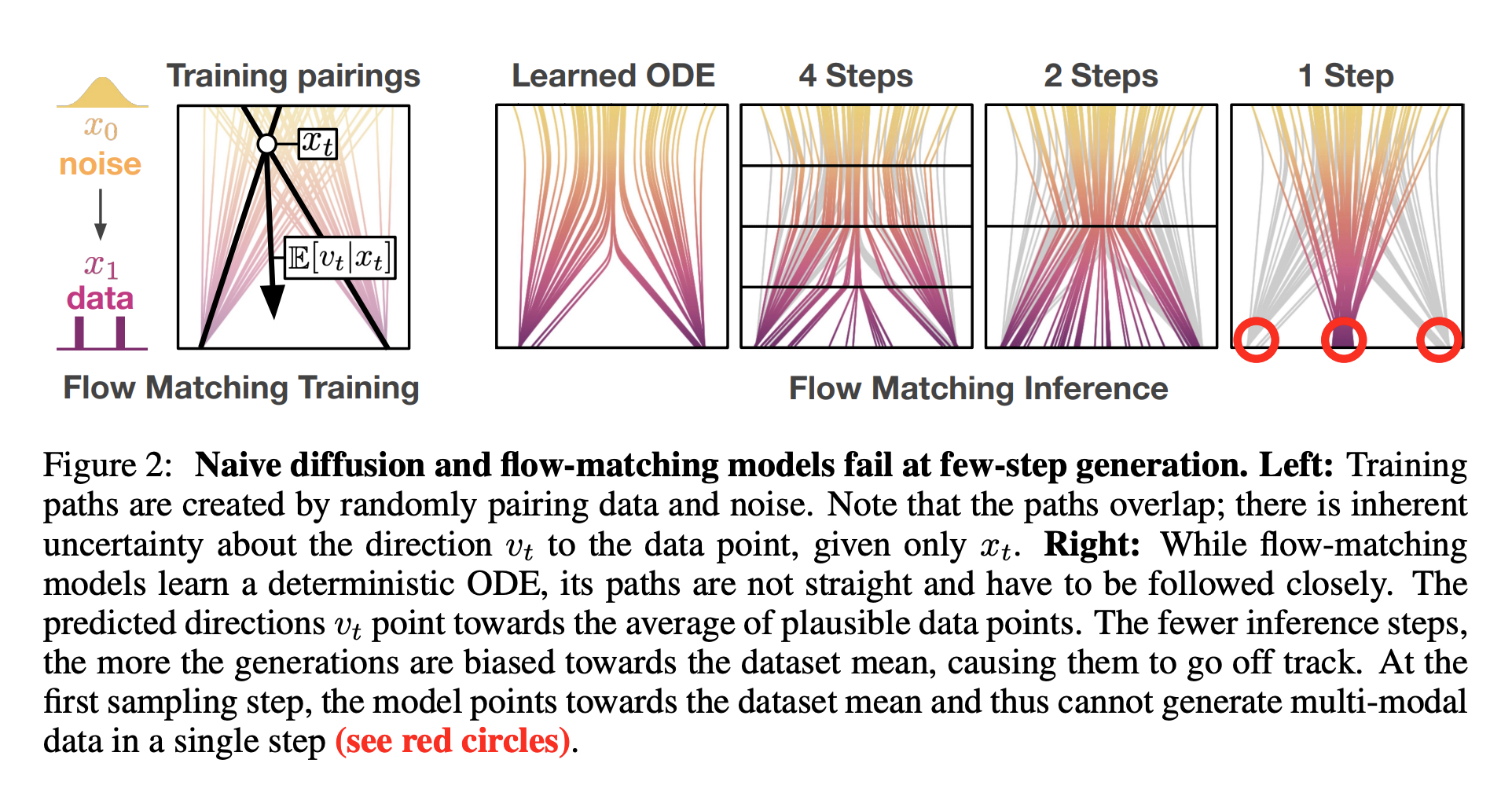
Why is 10 steps better than 1 step?
Because at the end of the day, we are trying to learn multi-modal distributions.
- ChatGPT answer: If you take 10 smaller steps, each step only needs to be locally correct. Integration keeps pulling you back onto the line. So error doesn’t explode; it averages out